25 世界銀行(World Bank)
25.1 World Development Indicator (WDI)
パッケージ と tidyverse と WDI を使いますから、下のコードによって、ロードします。
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(WDI)まず、三つの例を見てみましょう。なにをしているかわかりますか。考えて見てください。
WDI(country = "all", indicator = c(gdp = "NY.GDP.MKTP.CD"),
extra=TRUE) %>% drop_na(gdp) %>%
filter(year==max(year), income !="Aggregates") %>%
drop_na(region) %>% arrange(desc(gdp))#> Rows: 16758 Columns: 13
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (4): year, gdp, longitude, latitude
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
WDI(country = c("CN","GB","JP","IN","US","DE"), indicator = c(gdp = "NY.GDP.MKTP.CD"), extra=TRUE) %>% drop_na(gdp) %>%
ggplot(aes(year, gdp, col = country)) + geom_line() +
labs(title = "WDI NY.GDP.MKTP.CD: gdp")#> Rows: 372 Columns: 13
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (4): year, gdp, longitude, latitude
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.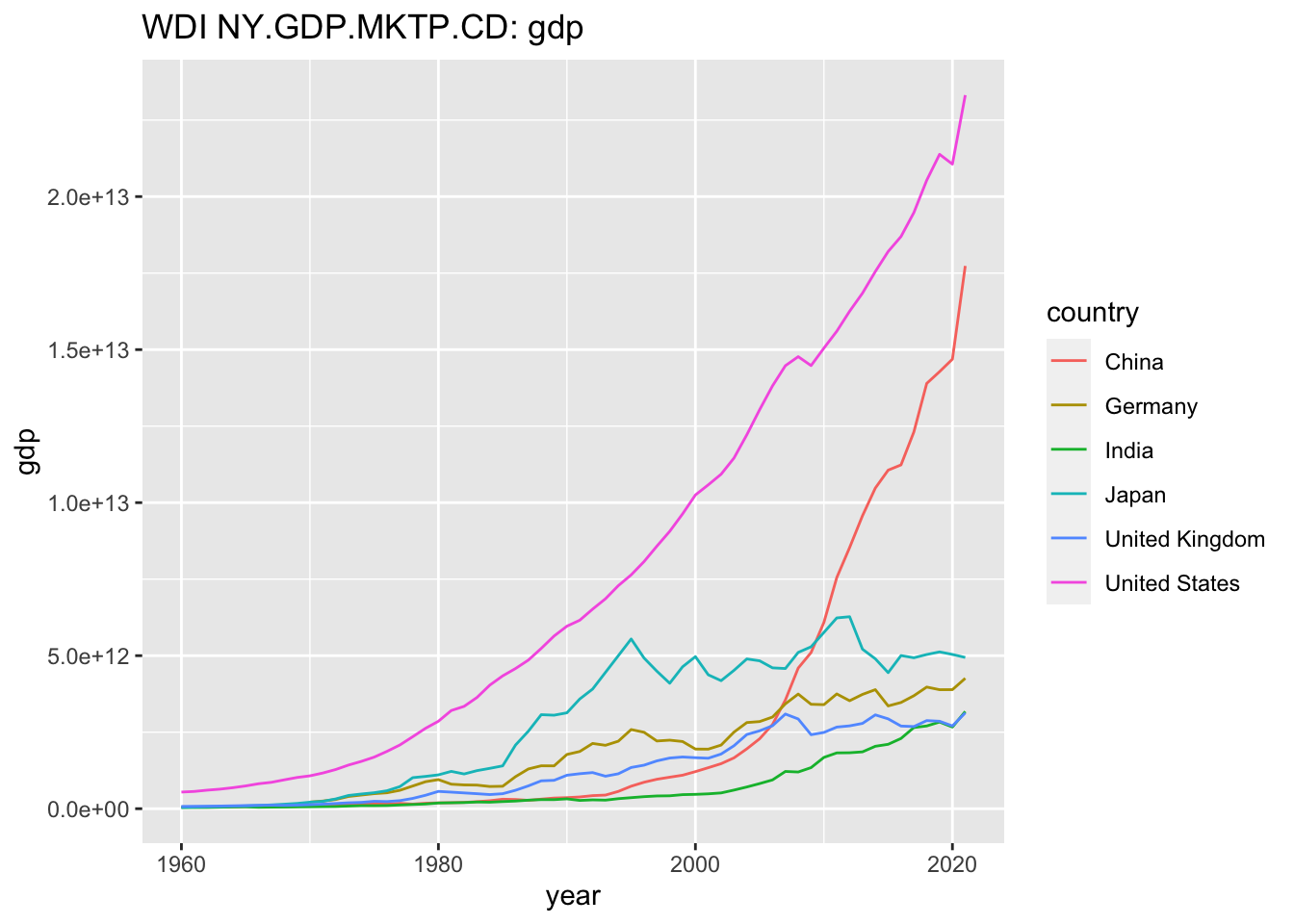
WDI(country = c("CN","IN","JP","US"),
indicator = c(gdp_growth_rate = "NY.GDP.MKTP.KD.ZG"), extra=TRUE) %>%
drop_na(gdp_growth_rate) %>%
ggplot(aes(year, gdp_growth_rate, col = country)) + geom_line() +
labs(title = paste("WDI NY.GDP.MKTP.KD.ZG: gdp growth rate"))#> Rows: 248 Columns: 13
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (4): year, gdp_growth_rate, longitude, latitude
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.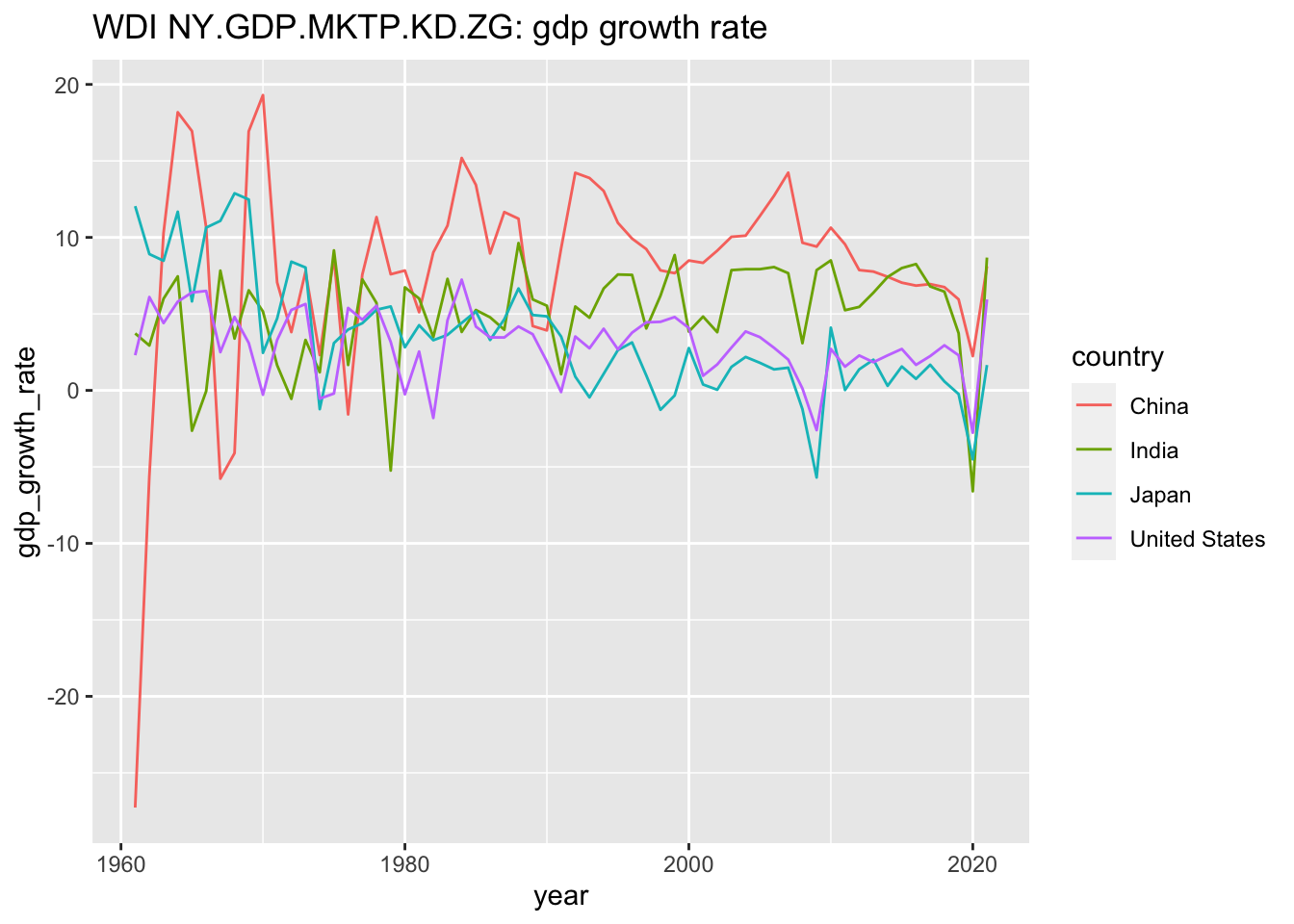
まず、世界の国々の、GDP(gross domestic product 国内総生産)のデータを、取得して、2021年の GDP を大きな順に並べています。
値は、たとえば、\(2.331508e+13\) のように書かれていますが、これは、科学的記法と呼ばれるもので、\(2.331508 \times 10^{13}\) を意味しています。約23兆ドルです。
次に、3兆ドル以上の、6カ国を選択し、その、iso2c と呼ばれるコードを使って、それらの国のデータをもう一度取得し、年次変化をあらわすグラフを描いています。
さらにその中から、4カ国を選んで、今度は、GDP の年次変化率を描いています。単位は、パーセントです。
これは、ひとつの例ですが、ここで使われているのが、WDI World Development Indicator というもので、世界銀行が、いくつかの指標を定めて、編纂しているものです。
25.1.1 指標 Indicators (WDI)
上の例では、次の二つの指標のコード Indicator Code (WDI Code) が使われました。
- NY.GDP.MKTP.CD: GDP (current US$)
- NY.GDP.MKTP.KD.ZG: GDP growth (annual %)
25.1.2 指標 WDI (World Development Indicators)
The World Development Indicators is a compilation of relevant, high-quality, and internationally comparable statistics about global development and the fight against poverty. The database contains 1,400 time series indicators for 217 economies and more than 40 country groups, with data for many indicators going back more than 50 years.
WDIは、世界の開発状況と、貧困との戦いに関する、適切で上質、かつ、国際的に比較可能な時系列の統計データを編纂したものです。このデータベースは、217の経済と40以上の国グループについて1,400の時系列指標を含み、指標のデータの多くは50年以上前に遡ることができます。
- 世界銀行(World Bank): https://www.worldbank.org
- World Bank Open Data: https://data.worldbank.org
- Country / Indicator > Featured & All > Details
-
World Development Indicators (WDI) :
- Themes: Poverty and Inequality, People, Environment, Economy, States and Markets, Global Links
- Open Data & DataBank: Explore data, Query database
25.1.3 指標 のコード、WDI code を探してみよう
いくつかの探し方があります。まず、ここでは、World Bank のサイトから探す方法を説明しましょう。
ふた通りあります。
World Bank Open Data にいくと、表題の下の検索窓の下に、 Country / Indicator とありますから、Indicator を選択します。すると、そこに、項目のリストが、Featured と All という二つのタブに分かれて出ています。かなり膨大です。それを選択すると、その項目のサイトに行きます。それが、指標のサイトです。図などの、右上に、Details とありますから、それを選択すると、その中に、Indicator が書かれています。 実は、指標のサイトのアドレス(URL)を見ると、そこにも、この Indicator が書かれていることがわかります。
World Development Indicators (WDI) にいくと、下のようなテーマに分かれています。
Themes: Poverty and Inequality, People, Environment, Economy, States and Markets, Global Links
その中から、選択して、スクロールすると、そこに、指標が書かれています。
Indicator, Code, Time coverage, Region coverage, Get data
とあり、Code が、指標のコードです。実は、すべての年や、すべての地域のデータが揃っているわけではないので、この情報を見ておくことはとても重要です。ほとんど、データがない場合もあります。
一番右端の Get data からは、CSV や、データバンク(Data Bank)へのリンクがあります。
それぞれの方法で、上で使った、二つの指標およびそのコードは見つかりましたか。
1 の方法の途中に出てきた、検索窓から検索することも可能です。
25.1.4 指標 WDIの例
このあとの、例で使う指標を書いておきます。
- NY.GDP.MKTP.CD: GDP (current US$)
- NY.GDP.DEFL.KD.ZG: Inflation, GDP deflator (annual %)
- SL.UEM.TOTL.NE.ZS: Unemployment, total (% of total labor force) (national estimate)
- CPTOTNSXN: CPI Price, nominal
- SL.TLF.CACT.MA.NE.ZS: Labor force participation rate, male (% of male population ages 15+) (national estimate)
- SL.TLF.CACT.FE.NE.ZS: Labor force participation rate, female (% of male population ages 15+) (national estimate)
25.2 WDI パッケージ
WDI パッケージ の使い方を紹介します。
WDI パッケージで、データをダウンロードしたり、探したり、詳細情報を得たりできます。
25.2.1 指標 WDI 検索
まず、検索です。上で、サイトから調べる方法を紹介しましたが、WDI パッケージの、WDIsearch でも探すことができます。詳細は、右下の窓枠の Help タブの検索窓に、WDIsearch といれて調べて見てください。ここでは、二種類の検索方法を紹介します。
25.2.1.1 検索例 1(WDI名)
WDI 名に、ある文字列が含まれているものを検索します。検索文字列は、大文字・小文字は関係ありません。
なんと、500件以上出てきました。Indicator(指標コード)と、Name(指標名)が列挙されます。すべてに、GDP という文字列が入っていることを確認できると思います。
25.2.1.2 検索例 2(WDI)
Indicator(指標コード)から、Name(指標名)を検索します。
WDIsearch(string = "NY.GDP.MKTP.CD", field = "indicator", short = TRUE, cache = NULL)二件出てきました。
25.2.1.3 練習 2. - 検索(short)
名前で検索(“” の間に、(なるべく簡単な)検索文字列を入れてください。)
WDIsearch(string = "", field = "name", short = TRUE, cache = NULL)Indicator で検索(“” の間に、調べたい indicator を入れてください。)
WDIsearch(string = "", field = "indicator", short = TRUE, cache = NULL)25.2.1.4 詳しい情報を得るには
上では、Indicator(指標コード)と、Name(指標名)だけでしたが、Description(説明) なども得ることができます。
それには、short = FALSE とします。
一回一回、World Bank にアクセスして調べるのは、時間もかかりますから、Indicator と、名前などの情報をもったファイルを手元に持っておくことにします。それには、次のようにします。
wdi_cache <- WDIcache()これは、series と、country の二つのデータ・フレームからなっているリストです。
右上の窓枠(pane)から、wdi_cache を探して、中身を見てみましょう。三角印や、右から二番目の巻物のようなアイコンをクリックすると中身が見えます。
series には、すべての指標がリストされ、その情報が書かれています。
また、country には、それぞれについて、さまざまな情報が書かれています。これは、とても、たいせつな情報です。国名と、iso2c, iso3c のようなコードもありますし、地域(region)や、その国が、どの income level(収入の階級)に入るかも書かれています。また、国だけではなく、地域など、グループの名称も含まれています。
今後、さまざまに利用していきたいと思います。
25.2.1.5 検索例 3(WDI名)
short = FALSE として、検索してみましょう。文字列が入っている、指標名を検索します。
WDIsearch(string = "CPI Price", field = "name", short = FALSE, cache = wdi_cache)- CPTOTNSXN: CPI Price, nominal
- The consumer price index reflects the change in prices for the average consumer of a constant basket of consumer goods. Data is not seasonally adjusted.
25.2.1.6 検索例 4(WDI)
指標コードから、詳細情報を得ます。
WDIsearch(string = "NY.GDP.MKTP.KD.ZG", field = "indicator", short = FALSE, cache = wdi_cache)25.2.1.7 練習 2 - 検索(long w/ cache)
string と、field を、ふたつとも入れてください。
WDIsearch(string = "", field = "", short = FALSE, cache = wdi_cache)25.2.2 指標 WDI データのダウンロード
Indicator が決まったら、ダウンロードします。右下の窓枠の Help タブの検索枠に、WDI と入れて確認しましょう。
WDI(
country = "all",
indicator = "NY.GDP.PCAP.KD",
start = 1960,
end = NULL,
extra = FALSE,
cache = NULL,
latest = NULL,
language = "en"
)上が基本的な用法ですが、start 以下は、Default(初期値)が書かれていますから、たいせつなのは、最初の二つ、country と、indicator です。
25.2.2.1 ダウンロード例 1-1
country は、初期値も、“all” となっていますから、最も簡単なのは、indicator に、指標コードを入れることです。引用符を忘れずに。
df_gdp1 <- WDI(country = "all", indicator = "NY.GDP.MKTP.CD")
df_gdp1#> Rows: 16492 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, iso2c, iso3c
#> dbl (2): year, NY.GDP.MKTP.CD
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.これでも良いのですが、利用するには、指標コードではわかりにくいので、それを簡単な名前に置き換えて、データを読み込むこができます。
25.2.2.2 ダウンロード例 1-2
#> Rows: 16492 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, iso2c, iso3c
#> dbl (2): year, gdp
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.25.2.2.3 ダウンロード例 1-3
今度は、extra = TRUE として、読み込みましょう。先ほど、読み込んである、wdi_cache を使います。
df_gdp3 <- WDI(country = "all", indicator = c(gdp = "NY.GDP.MKTP.CD"),
extra=TRUE, cache=wdi_cache)
df_gdp3#> Rows: 16492 Columns: 13
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (4): year, gdp, longitude, latitude
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.右上の三角印を使って、どのような詳細情報が付加されたか見て見ましょう。どんなことがわかりますか。
25.2.2.4 ダウンロード例 1-4
国名を指定します。WDI では、iso2c コードを使って、国名を指定します。上で見たように、Envoronment から、wdi_cache を選択すると、国名と、iso2c コード両方を見ることができました。iso2c や、iso3c は、よく使われるので、web 検索でも簡単にみつけることができます。最初に紹介した例ですから、どの国かはわかりますね、
df_gdp4 <- WDI(country = c("CN","GB","JP","IN","US","DE"),
indicator = c(gdp = "NY.GDP.MKTP.CD"), extra=TRUE, cache=wdi_cache)
df_gdp4#> Rows: 372 Columns: 13
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (4): year, gdp, longitude, latitude
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.25.2.2.5 ダウンロード例 2-1
二つの、指標コードを使って、同時に読み込むこともできます。そのときは、c() (combine) を使います。
- NY.GDP.DEFL.KD.ZG: Inflation, GDP deflator (annual %)
- CPTOTNSXN: CPI Price, nominal
df_gdp21 <- WDI(country = "all",
indicator = c(gdp_deflator = "NY.GDP.DEFL.KD.ZG",
cpi_price = "CPTOTNSXN"),
extra=TRUE, cache=wdi_cache)
df_gdp21#> Rows: 23972 Columns: 14
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (5): year, gdp_deflator, cpi_price, longitude, lati...
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.NA (not available) つまり、データがないものが多いことがわかります。もう少し、データをよく見て見ましょう。
str(df_gdp21)
#> spc_tbl_ [23,972 × 14] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
#> $ country : chr [1:23972] "Advanced Economies" "Advanced Economies" "Advanced Economies" "Advanced Economies" ...
#> $ iso2c : chr [1:23972] "AME" "AME" "AME" "AME" ...
#> $ iso3c : chr [1:23972] NA NA NA NA ...
#> $ year : num [1:23972] 1987 1988 1989 1990 1991 ...
#> $ status : logi [1:23972] NA NA NA NA NA NA ...
#> $ lastupdated : Date[1:23972], format: "2020-07-27" ...
#> $ gdp_deflator: num [1:23972] NA NA NA NA NA NA NA NA NA NA ...
#> $ cpi_price : num [1:23972] 58.7 60.5 63 66 69.1 ...
#> $ region : chr [1:23972] NA NA NA NA ...
#> $ capital : chr [1:23972] NA NA NA NA ...
#> $ longitude : num [1:23972] NA NA NA NA NA NA NA NA NA NA ...
#> $ latitude : num [1:23972] NA NA NA NA NA NA NA NA NA NA ...
#> $ income : chr [1:23972] NA NA NA NA ...
#> $ lending : chr [1:23972] NA NA NA NA ...
#> - attr(*, "spec")=
#> .. cols(
#> .. country = col_character(),
#> .. iso2c = col_character(),
#> .. iso3c = col_character(),
#> .. year = col_double(),
#> .. status = col_logical(),
#> .. lastupdated = col_date(format = ""),
#> .. gdp_deflator = col_double(),
#> .. cpi_price = col_double(),
#> .. region = col_character(),
#> .. capital = col_character(),
#> .. longitude = col_double(),
#> .. latitude = col_double(),
#> .. income = col_character(),
#> .. lending = col_character()
#> .. )
#> - attr(*, "problems")=<externalptr>
summary(df_gdp21)
#> country iso2c iso3c
#> Length:23972 Length:23972 Length:23972
#> Class :character Class :character Class :character
#> Mode :character Mode :character Mode :character
#>
#>
#>
#>
#> year status lastupdated
#> Min. :1960 Mode:logical Min. :2020-07-27
#> 1st Qu.:1982 NA's:23972 1st Qu.:2020-07-27
#> Median :1996 Median :2022-12-22
#> Mean :1995 Mean :2022-03-23
#> 3rd Qu.:2009 3rd Qu.:2022-12-22
#> Max. :2021 Max. :2022-12-22
#>
#> gdp_deflator cpi_price region
#> Min. : -98.704 Min. : 0.00 Length:23972
#> 1st Qu.: 2.317 1st Qu.: 55.95 Class :character
#> Median : 5.273 Median : 83.28 Mode :character
#> Mean : 25.308 Mean : 84.18
#> 3rd Qu.: 10.411 3rd Qu.:108.75
#> Max. :26765.858 Max. :551.25
#> NA's :11616 NA's :18410
#> capital longitude latitude
#> Length:23972 Min. :-175.22 Min. :-41.286
#> Class :character 1st Qu.: -15.18 1st Qu.: 4.174
#> Mode :character Median : 19.26 Median : 17.300
#> Mean : 19.14 Mean : 18.889
#> 3rd Qu.: 50.53 3rd Qu.: 40.050
#> Max. : 179.09 Max. : 64.184
#> NA's :10890 NA's :10890
#> income lending
#> Length:23972 Length:23972
#> Class :character Class :character
#> Mode :character Mode :character
#>
#>
#>
#> どんなことが分かりましたか。
右上の窓枠の、Environment でも df_gdp21 を見てみましょう。
25.3 可視化 Visualization
グラフ(Chart)を描いて視覚化します。ここでは、年ごとの変化をみる、折れ線グラフだけを描いて見ます。
25.3.1 グラフ 1
x = year, y = gdp の、x=, y= は省略してあります。col=country は、国ごとに、グループにして、色分けをします。col は、color としても colour としても、問題ありません。 `
df_gdp4 %>% ggplot(aes(year, gdp, col=country)) + geom_line()
#> Warning: Removed 10 rows containing missing values
#> (`geom_line()`).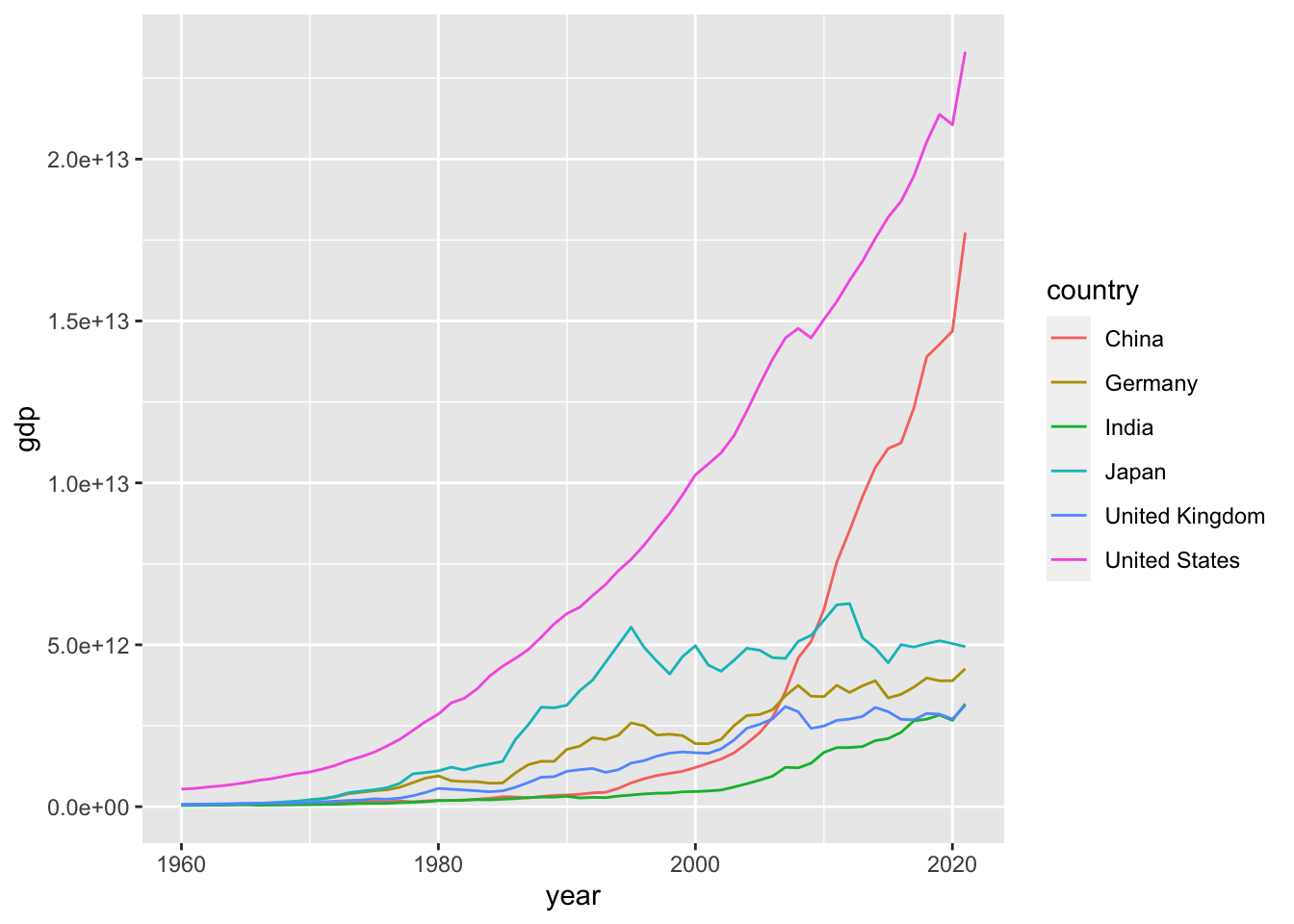
Warning として、missing values があると出ています。どこかは、分かりませんが、図を書くときですから、y に対応する、gdp の値がないものと思われます。
25.3.2 グラフ 2
drop_na(gdp) で、gdp の値が、NA であるものを削除します。また、labs で、図にタイトルをつけます。
df_gdp4 %>% drop_na(gdp) %>%
ggplot(aes(year, gdp, col=country)) + geom_line() +
labs(title = "WDI - NY.GDP.MKTP.CD: gdp")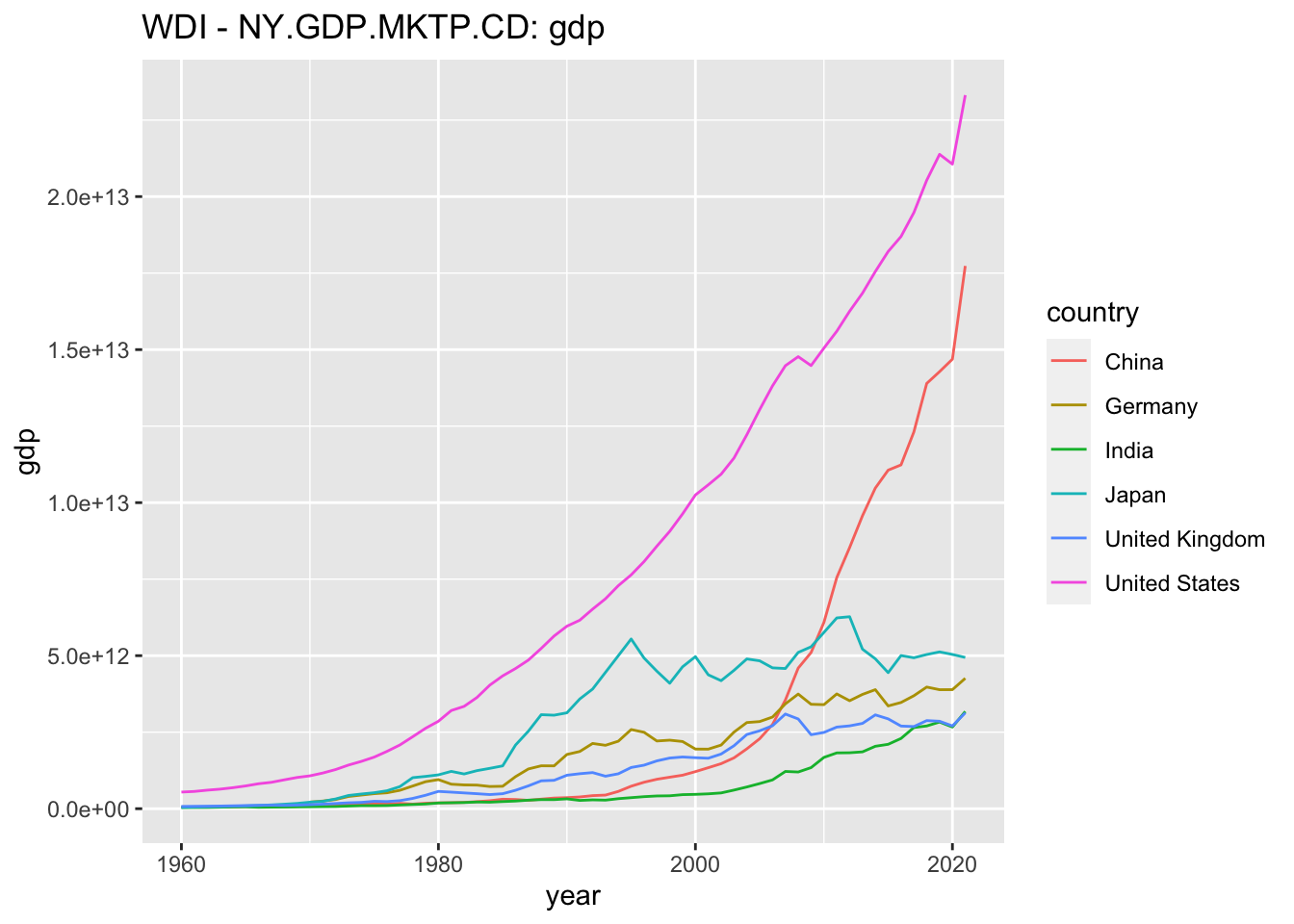
25.3.3 テンプレート Templates
下に、テンプレートをつけます。コピーして、指標コードや、略称、国などを、それぞれ置き換えて、試して見てください。少し、複雑な変形をしていますが、少しずつ説明します。
25.3.3.1 一つの国についての、一つの指標(WDI)と、その略称から、折線グラフを作成
Line Plot with one indicator with abbreviation and one country
chosen_indicator <- "SL.UEM.TOTL.NE.ZS"
short_name <- "unemployment"
chosen_country <- "United States"
WDI(country = "all", indicator = c(short_name = chosen_indicator), extra=TRUE, cache=wdi_cache) %>%
filter(country == chosen_country) %>%
ggplot(aes(year, short_name)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator, ": ", short_name, " - ", chosen_country),
y = short_name)25.3.3.2 一つの国についての、一つの指標(WDI)から、折線グラフを作成
Line Plot with one indicator and one country
chosen_indicator <- "SL.UEM.TOTL.NE.ZS"
chosen_country <- "United States"
WDI(country = "all", indicator = c(chosen_indicator = chosen_indicator),
extra=TRUE, cache=wdi_cache) %>%
filter(country == chosen_country) %>%
ggplot(aes(year, chosen_indicator)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator, " - ", chosen_country),
y = chosen_indicator)25.3.3.3 いくつかの国についての、一つの指標(WDI)と、その略称から、折線グラフを作成
Line Plot with one indicator with abbreviation and several countries
chosen_indicator <- "SL.UEM.TOTL.NE.ZS"
short_name <- "unemployment"
chosen_countries <- c("United States","United Kingdom", "Japan")
WDI(country = "all", indicator = c(short_name = chosen_indicator), extra=TRUE, cache=wdi_cache) %>% drop_na(short_name) %>%
filter(country %in% chosen_countries) %>%
ggplot(aes(year, short_name, col = country)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator, ": ", short_name), y = short_name)25.3.3.4 一つの国についての、二つの指標(WDI)と、その略称から、折線グラフを作成
Line Plot with two indicators with abbreviation and one country
chosen_indicator_1 <- "NY.GDP.DEFL.KD.ZG"
short_name_1 <- "gdp_deflator"
chosen_indicator_2 <- "CPTOTSAXNZGY"
short_name_2 <- "cpi_price"
chosen_country <- "United States"
WDI(country = "all", indicator = c(short_name_1 = chosen_indicator_1, short_name_2 = chosen_indicator_2), extra=TRUE, cache=wdi_cache) %>%
filter(country == chosen_country) %>%
pivot_longer(c(short_name_1, short_name_2), names_to = "class", values_to = "value") %>% drop_na(value) %>%
ggplot(aes(year, value, col = class)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator_1, ": ", short_name_1, "\n", chosen_indicator_2, ": ", short_name_2, " - ", chosen_country)) +
scale_color_manual(labels = c(short_name_1, short_name_2), values = scales::hue_pal()(2))
chosen_indicator_1 <- "SL.TLF.CACT.MA.NE.ZS"
short_name_1 <- "male"
chosen_indicator_2 <- "SL.TLF.CACT.FE.NE.ZS"
short_name_2 <- "female"
chosen_country <- "United States"
WDI(country = "all", indicator = c(short_name_1 = chosen_indicator_1, short_name_2 = chosen_indicator_2), extra=TRUE, cache=wdi_cache) %>%
filter(country == chosen_country) %>%
pivot_longer(c(short_name_1, short_name_2), names_to = "class", values_to = "value") %>% drop_na(value) %>%
ggplot(aes(year, value, col = class)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator_1, ": ", short_name_1, "\n", chosen_indicator_2, ": ", short_name_2, " - ", chosen_country)) +
scale_color_manual(labels = c(short_name_1, short_name_2), values = scales::hue_pal()(2))25.3.3.5 いくつかの国についての、二つの指標(WDI)と、その略称から、折線グラフを作成
Line Plot with two indicators with abbreviation and several countries
chosen_indicator_1 <- "NY.GDP.DEFL.KD.ZG"
short_name_1 <- "gdp_deflator"
chosen_indicator_2 <- "CPTOTSAXNZGY"
short_name_2 <- "cpi_price"
chosen_countries <- c("United States", "France", "Japan")
WDI(country = "all", indicator = c(short_name_1 = chosen_indicator_1, short_name_2 = chosen_indicator_2), extra=TRUE, cache=wdi_cache) %>%
filter(country %in% chosen_countries) %>%
pivot_longer(c(short_name_1, short_name_2), names_to = "class", values_to = "value") %>% drop_na(value) %>%
ggplot(aes(year, value, linetype = class, col = country)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator_1, ": ", short_name_1, "\n", chosen_indicator_2, ": ", short_name_2)) +
scale_linetype_manual(labels = c(short_name_1, short_name_2), values = c("solid", "dashed"))
chosen_indicator_1 <- "SL.TLF.CACT.MA.NE.ZS"
short_name_1 <- "male"
chosen_indicator_2 <- "SL.TLF.CACT.FE.NE.ZS"
short_name_2 <- "female"
chosen_countries <- c("United States", "France", "Japan")
WDI(country = "all", indicator = c(short_name_1 = chosen_indicator_1, short_name_2 = chosen_indicator_2), extra=TRUE, cache=wdi_cache) %>%
filter(country %in% chosen_countries) %>%
pivot_longer(c(short_name_1, short_name_2), names_to = "class", values_to = "value") %>% drop_na(value) %>%
ggplot(aes(year, value, linetype = class, col = country)) + geom_line() +
labs(title = paste("WDI ", chosen_indicator_1, ": ", short_name_1, "\n", chosen_indicator_2, ": ", short_name_2)) +
scale_linetype_manual(labels = c(short_name_1, short_name_2), values = c("solid", "dashed"))25.4 課題 Assignment
上のテンプレートをコピーして、下に貼り付け、指標 indicator と、略称 short_name と、いくつかの国名 chosen_countries を、入れ替えて、試してみてください。
library(tidymodels)
#> ── Attaching packages ────────────────── tidymodels 1.1.1 ──
#> ✔ broom 1.0.5 ✔ rsample 1.2.0
#> ✔ dials 1.2.0 ✔ tune 1.1.2
#> ✔ infer 1.0.5 ✔ workflows 1.1.3
#> ✔ modeldata 1.2.0 ✔ workflowsets 1.0.1
#> ✔ parsnip 1.1.1 ✔ yardstick 1.2.0
#> ✔ recipes 1.0.8
#> ── Conflicts ───────────────────── tidymodels_conflicts() ──
#> ✖ scales::discard() masks purrr::discard()
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ recipes::fixed() masks stringr::fixed()
#> ✖ dplyr::lag() masks stats::lag()
#> ✖ yardstick::spec() masks readr::spec()
#> ✖ recipes::step() masks stats::step()
#> • Learn how to get started at https://www.tidymodels.org/start/25.5 政府支出(国内総生産比)Government Expenditure, (% of GDP)
ここでは、多変数モデルについては、紹介できませんが、複数の変数を使って、それぞれどのような影響があるかを調べる方法を少しだけ紹介します。
WDI の指標が、出生時平均寿命にどのていど、影響するかを調べてみます。
まずは、指標名の中に、“expenditure” と、“% of GDP” を含むものを探します。下では二つの方法を提示しています。一方は、表の結合の、inner_join を使う方法、もう一つは、正規表現の、grepl を使う方法です。なにも指定しないと、grepl は大文字小文字を区別し、WDIsearch は、区別しませんから、ひとつだけ、差が生じています。
wdi_cache <- read_rds("./data/wdi_cache.RData")
WDIsearch("expenditure", "name", cache = wdi_cache) %>%
inner_join(WDIsearch("% of GDP", "name", cache = wdi_cache))
#> Joining with `by = join_by(indicator, name)`以下の指標のデータを読み込んでみます。
NY.GDP.PCAP.KD: GDP per capita (constant 2015 US$) - 国際総生産
SP.DYN.LE00.IN: Life expectancy at birth, total (years) - 出生時寿命
SP.POP.TOTL: Population, total - 人口
GB.XPD.RSDV.GD.ZS: Research and development expenditure (% of GDP) - 2 - 研究開発
MS.MIL.XPND.GD.ZS: Military expenditure (% of GDP) - 6 - 軍事費
SE.XPD.TOTL.GD.ZS: Government expenditure on education, total (% of GDP) - 教育費
wdi_world <- WDI(country = "all", indicator = c(gdpPcap = "NY.GDP.PCAP.KD", lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL", research = "GB.XPD.RSDV.GD.ZS", military = "MS.MIL.XPND.GD.ZS", education = "SE.XPD.TOTL.GD.ZS"), 1990, extra = TRUE, cache = wdi_cache)#> Rows: 8778 Columns: 18
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (9): year, gdpPcap, lifeExp, pop, research, militar...
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
wdi_worldあまりデータがないものもあるようです。少しずつ調べてみましょう。
SE.XPD.TOTL.GB.ZS: Government expenditure on education, total (% of government expenditure)
SE.XPD.TOTL.GD.ZS: Government expenditure on education, total (% of GDP)
SE.XPD.PRIM.PC.ZS: Government expenditure per student, primary (% of GDP per capita)
MS.MIL.XPND.ZS: Military expenditure (% of general government expenditure)
SE.XPD.TERT.ZS: Expenditure on tertiary education (% of government expenditure on education)
mod_e <- lm(lifeExp ~ education, wdi_world); mod_e
#>
#> Call:
#> lm(formula = lifeExp ~ education, data = wdi_world)
#>
#> Coefficients:
#> (Intercept) education
#> 66.7431 0.7654
wdi_world |> ggplot(aes(education, lifeExp)) + geom_point() + geom_smooth(formula = y ~ x, method = "lm", se=FALSE)
#> Warning: Removed 4030 rows containing non-finite values
#> (`stat_smooth()`).
#> Warning: Removed 4030 rows containing missing values
#> (`geom_point()`).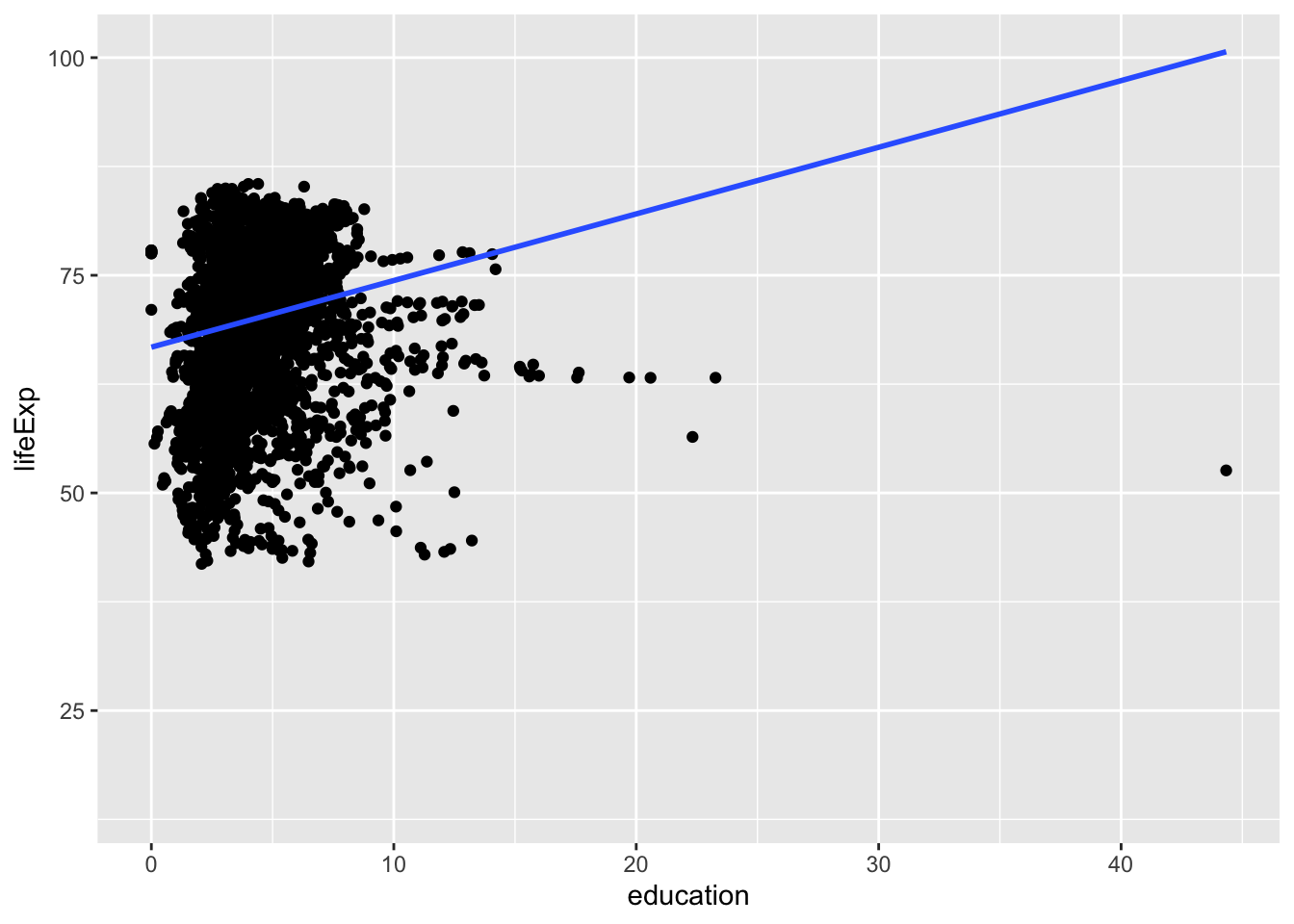
wdi_world %>% filter(income != "Aggregates") |> drop_na(education, lifeExp) |> ggplot(aes(education, lifeExp)) + geom_point() + geom_smooth(formula = y ~ x, method = "lm", se=FALSE)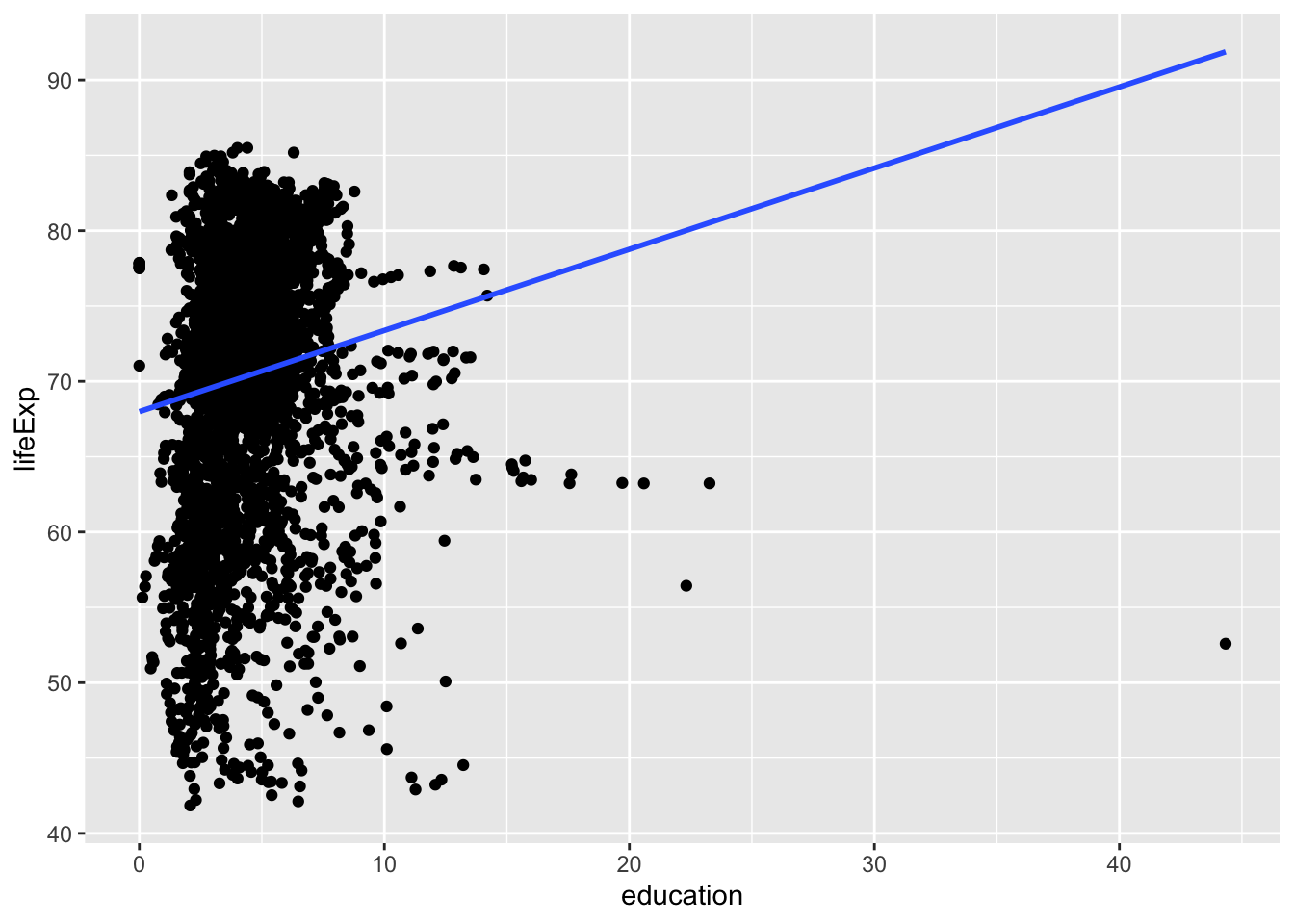
wdi_world_el <- wdi_world %>% select(country, year, education, lifeExp, gdpPcap, pop, research, military, region, income) |> filter(income != "Aggregates") |> drop_na(education, lifeExp)
wdi_world_el |> ggplot(aes(education)) + geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.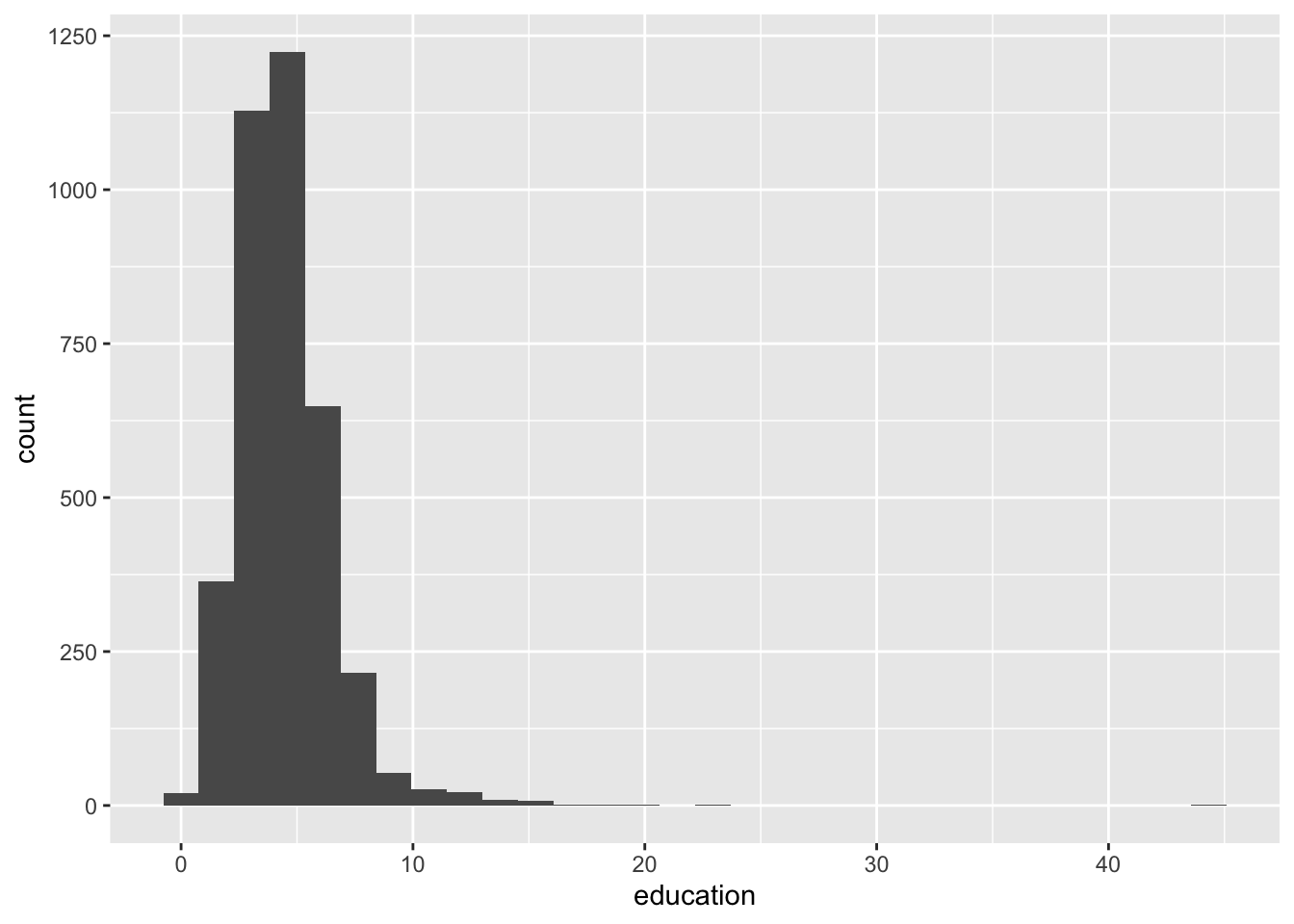
wdi_world_el |> filter(year==2020) |> ggplot(aes(x = income, y = education, fill = income)) + geom_boxplot()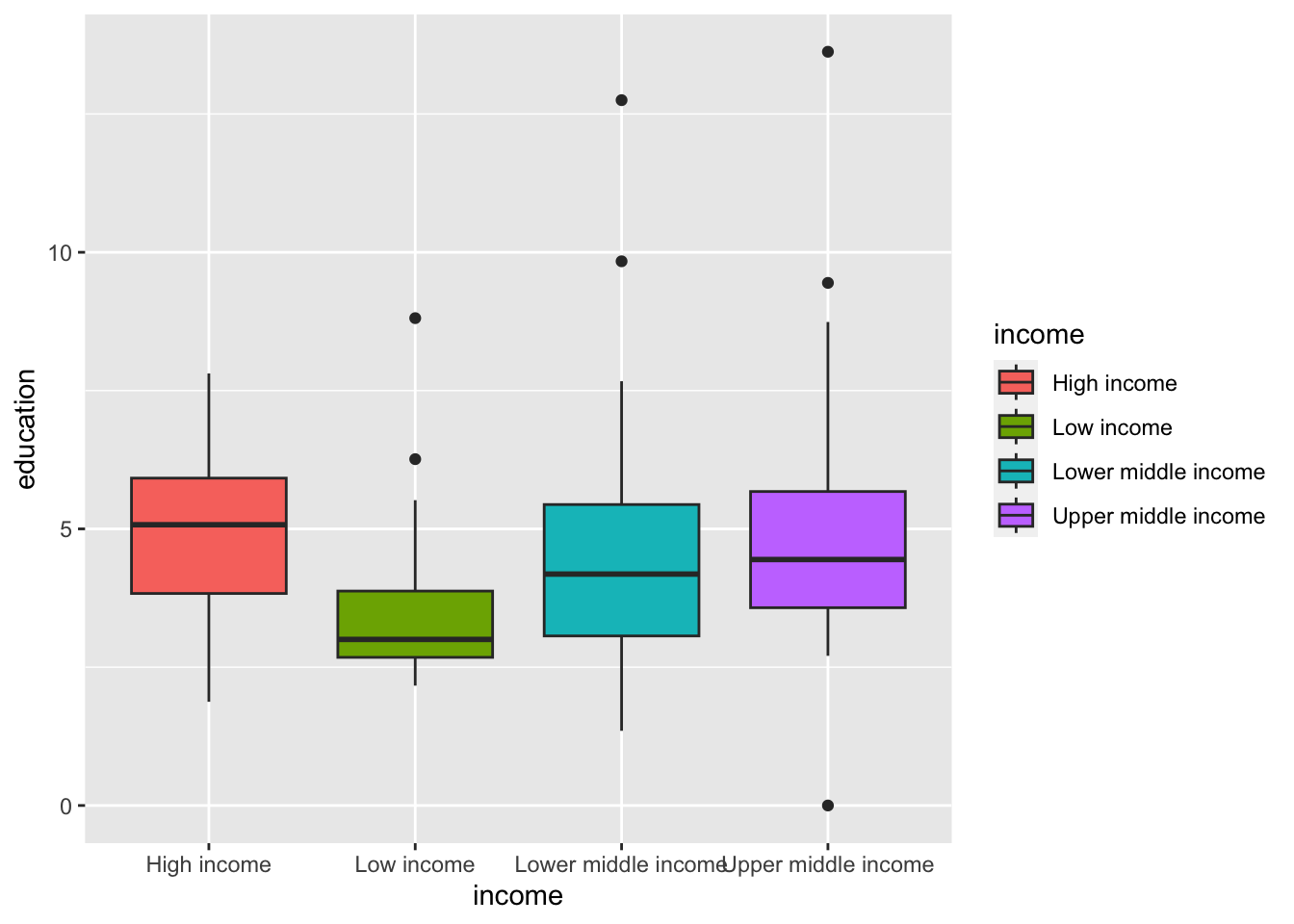
wdi_world_el |> filter(year==2020) |> lm(gdpPcap ~ education, data = _)
#>
#> Call:
#> lm(formula = gdpPcap ~ education, data = filter(wdi_world_el,
#> year == 2020))
#>
#> Coefficients:
#> (Intercept) education
#> 10568.8 940.2
wdi_world_el |> lm(lifeExp ~ education + research + military, data = _) |> glance()
wdi_world_el |> lm(lifeExp ~ education + research + military, data = _) |> tidy()\[lifeExp \sim 70.22 + 0.08\cdot education + 3.84 \cdot research - 0.07 \cdot military\]
wdi_world_el |> lm(gdpPcap ~ education + research + military, data = _) |> tidy()
wdi_world_el |> lm(gdpPcap ~ education + research + military, data = _) |> glance()\[gdpPcap \sim 1077 + 1024\cdot education + 12792 \cdot research - 967 \cdot military\]
mod_r <- lm(lifeExp ~ research, wdi_world); mod_e
#>
#> Call:
#> lm(formula = lifeExp ~ education, data = wdi_world)
#>
#> Coefficients:
#> (Intercept) education
#> 66.7431 0.7654