19 視覚化(Visualize)
19.1 基本的なこと
R では、追加パッケージを使わなくても、簡単に、グラフを描画できますが、質の高いグラフを作成するには、ggplot2 パッケージを用いたものが標準となっています。ggplot2 は、tidyverse パッケージの一部ですので、tidyverse パッケージをインストール、使えるように、library(tidyverse) として読み込んであれば、そのまま使うことができます。
サイト:https://ggplot2.tidyverse.org
パッケージサイト:https://CRAN.R-project.org/package=ggplot2
19.1.1 ggplot2 概要
ggplot2 is a system for declaratively creating graphics, based on The Grammar of Graphics. You provide the data, tell ggplot2 how to map variables to aesthetics, what graphical primitives to use, and it takes care of the details.
ggplot2は、グラフィックスの生成に関する「Grammar of Graphics(グラフィックスの文法)」に基づいて、一つ一つの要素を定めていくことによって、グラフを作成するシステムです。データを提供し、変数を視覚的要素にマッピングする方法や、どのようなグラフィカルな基本要素を使用するかをggplot2に伝えると、詳細な部分はggplot2 が処理してくれます。
19.1.2 基本的な例
19.1.2.1 tidyverse の読み込み
タイトルや、列名などに日本語を使う場合があるときは、install.packages('showtext') で、showtext パッケージをインストールして、下のように設定してください。そうでない場合は、最初の行 library(tidyverse) だけで他は不要です。
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(showtext)
#> Loading required package: sysfonts
#> Loading required package: showtextdb
showtext_auto()19.1.2.2 復習
Tidyverse の章で、紹介した例の復習から始めましょう。
df_iris <- datasets::iris
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length)) + geom_point()
さまざまな描画が可能ですが、一番、一般的な、散布図、plot に対応するものです。ggplot の中の、aes (aesthetic)の部分に、x 軸、y 軸に対応する変数(列名)を書きます。
<DATA> |> ggplot(aes(<変数 x の列名>, <変数 y の列名>)) + geom_point()もっと明示的に、下のように書きます。最初は、このような書き方が、わかりやすいと思います。
<DATA> |> ggplot(aes(x = <変数 x の列名>, y = <変数 y の列名>)) + geom_point()さらには
<DATA> |> ggplot(mapping = aes(x = <変数 x の列名>, y = <変数 y の列名>)) + geom_point()パイプを使わず
ggplot(<DATA>, aes(x = <変数 x の列名>, y = <変数 y の列名>)) + geom_point()や、さらに、詳しく
ggplot(data = <DATA>, mapping = aes(x = <変数 x の列名>, y = <変数 y の列名>)) + geom_point()も可能です。いろいろな書き方が可能であることを書きましたが、原則は、関数の中に書く、引数をどのような順序で、名前をつけて書くか省略するかですので、詳細は、Tidyverse の メモ蘭をご覧ください。
種類(Species)ごとに色を変える場合には、color = Species とします。
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length, color = Species)) +
geom_point()
さらに、点の大きさを、Petal.Width によって変える場合には次のように、size = Petal.Width を加えます。
df_iris |>
ggplot(aes(Sepal.Width, Sepal.Length, color = Species,
size = Petal.Width)) +
geom_point()
ここでは、散布図でしたから、geom_point() を使いましたが、これを他のものに変えていくと、さまざまなグラフが描けるようになっています。
19.2 散布図(Scatter Plot)
散布図は、データの二つの変数(列) を x と y に対応させる、最も基本的なグラフです。最初に試すべきグラフだともいうことができます。mapping = は省略することができます。
ggplot(data = <data>,
aes(x = <column name for x>, y = <column name for y>)) +
geom_point()ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point()変形(Transform)のときにもつかい、上でも使った、あやめ(iris )データを使います。
まずは、上で復習した基本形から。
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point()
19.2.1 ラベル Labels
グラフの表題や、x 軸、y 軸のラベルをつけるには labs() を使います。
ggplot(data = <data>, aes(x = <column name for x>, y = <column name for y>)) +
geom_point() +
labs(title = "Title", x = "Label for x", y = "Label for y")
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
labs(title = "Scatter Plot of Sepal Data of Iris",
x = "Sepal Length", y = "Sepal Width")
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
labs(title = "あやめの萼の長さと幅についての散布図",
x = "萼の長さ", y = "萼の幅")
このように、日本語をタイトルや、ラベルに使うことも可能ですが、以後は、データに日本語が含まれていない場合には、そのまま表示します。
19.2.2 色付き Colors
菖蒲(iris)のデータは、Species 列に、三種類の菖蒲の名前が含まれていました。それぞれに、違う色で表示してみましょう。それには、x 軸、y 軸に対応する変数を指定したように、color = Species と指定します。これも、Species の列に書いてある値によって変化させるので、mapping(写像)の、aes() の一部として加えます。色は自動的に割り当ててくれます。色を指定する方法23などは、また別の箇所で述べます。
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width,
color = Species)) +
geom_point()
単に、点の色をすべて、blue に変えたいのなら、geom_point() の中に color = “blue” と書きます。表へのリンクをつけておきます。sape(Software and Programmer Efficiency Research Group) のggplot2 quick reference のものです。
{kind=link}
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point(color = "blue")
19.2.3 形状 Shapes
色ではなく、形で Species を区別することも可能です。sape のリンクをつけておきます。
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width, shape = Species)) +
geom_point()
色と、形、両方を同時に使うことも可能です。色盲の方など、さまざまな背景の方にやさしい工夫・配慮をすることも、大切です。色についても、色盲の方に配慮した配色を選択することも可能なようになっています。参照リンク
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width,
color = Species, shape = Species)) +
geom_point()
19.3 箱ひげ図 Boxplot
The boxplot compactly displays the distribution of a continuous variable.
箱ひげ図は、連続な値をとる変数の分布を簡潔な表示でみることができるグラフです。箱や、線の長さ、外れ値の表示なども、正確に決まっていますので、次のビデオをみてください。英語ですが、わかりやすく、まとまっていると思います。
日本語では、下のサイトの箱ひげ図の項目を見ていただければと思います。外れ値についての説明もあります。
箱ひげ図と幹葉表示:https://bellcurve.jp/statistics/course/5219.html
Transcript ボタンから、スクリプトを表示することもできます。
例のように、それぞれのグループごとに箱ひげ図を表示することもできますが、その場合は、文字データや、離散的な数値データ(いくつかの飛び飛びの値をとる変数)を使います。x と y を入れ替えれば、横向きになります。
ggplot(data = df_iris, aes(x = Species, y = Sepal.Length)) +
geom_boxplot()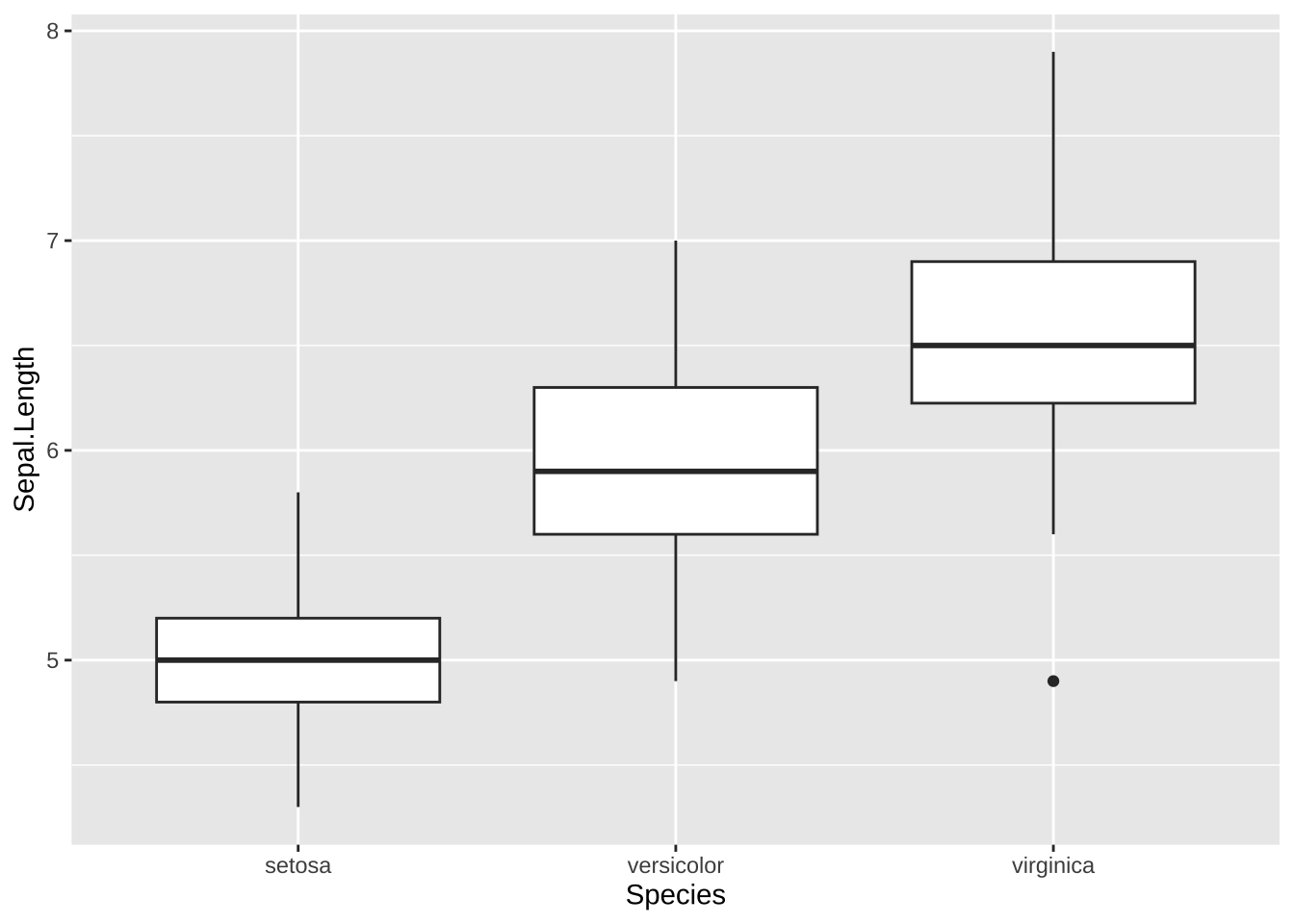
ggplot(data = df_iris, aes(y = Species, x = Sepal.Length)) +
geom_boxplot()
各、種類(Species)ごとに、Sepal.Width(萼(がく)幅)が、どのように分布しているかを示しています。真ん中の太い線が、中央値(median)、箱が、第一四分位(Q1)から第三四分位(Q3)、線と点で表される外れ値も、どのような基準か定められています。(IQR = Q3-Q1, 線は、Q3+1.5\(\times\) IQR 以下に入っている実際の値までと、Q1-1.5 \(\times\) IQR 以上に入っている実際の値まで。それらに入っていないものが外れ値)。
color を指定すると、枠に色がつき、fill を指定すると、箱の中が塗り潰されます。
ggplot(data = df_iris,
aes(x = Species, y = Sepal.Length, color = Species)) +
geom_boxplot()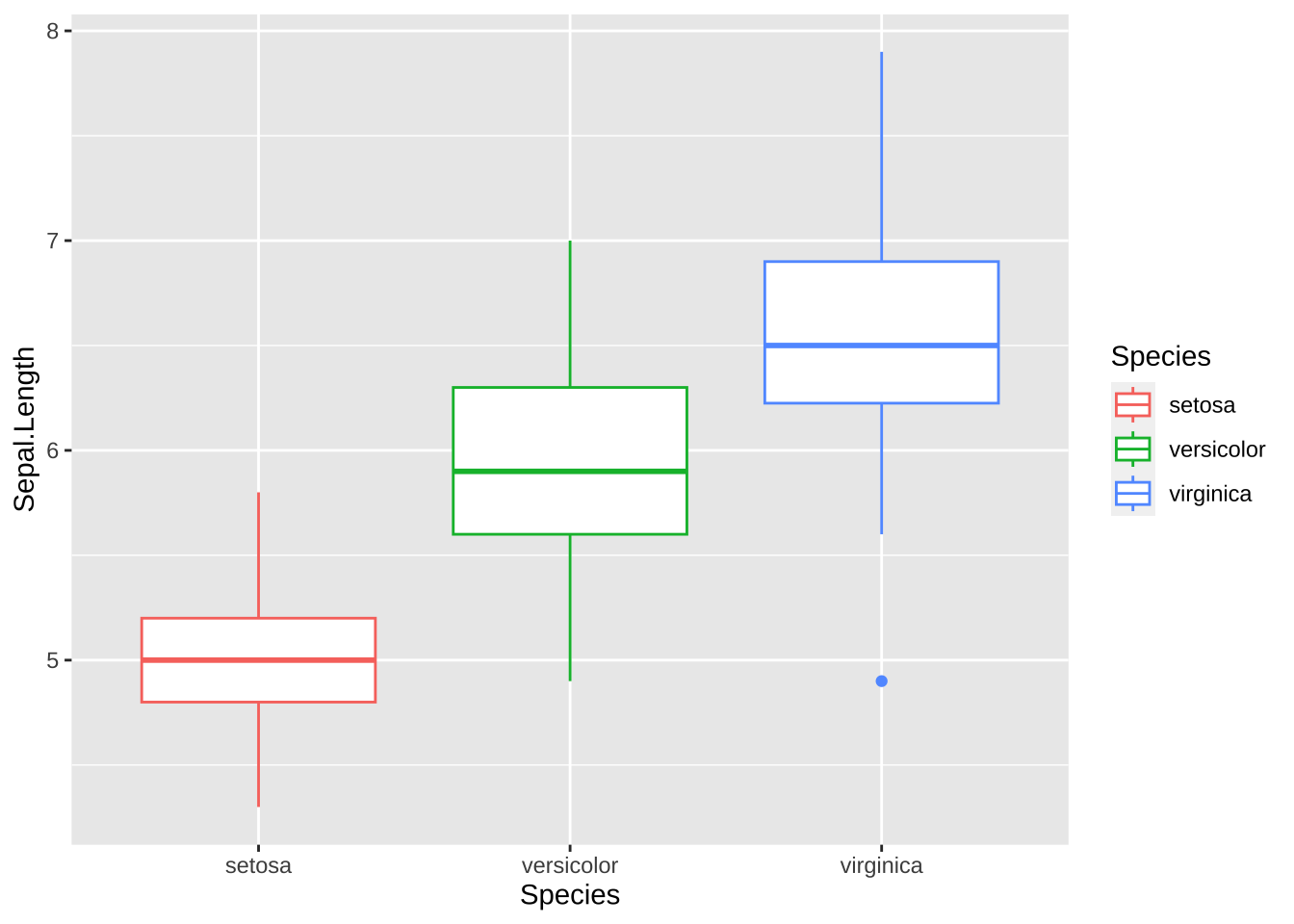
ggplot(data = df_iris,
aes(x = Species, y = Sepal.Length, fill = Species)) +
geom_boxplot()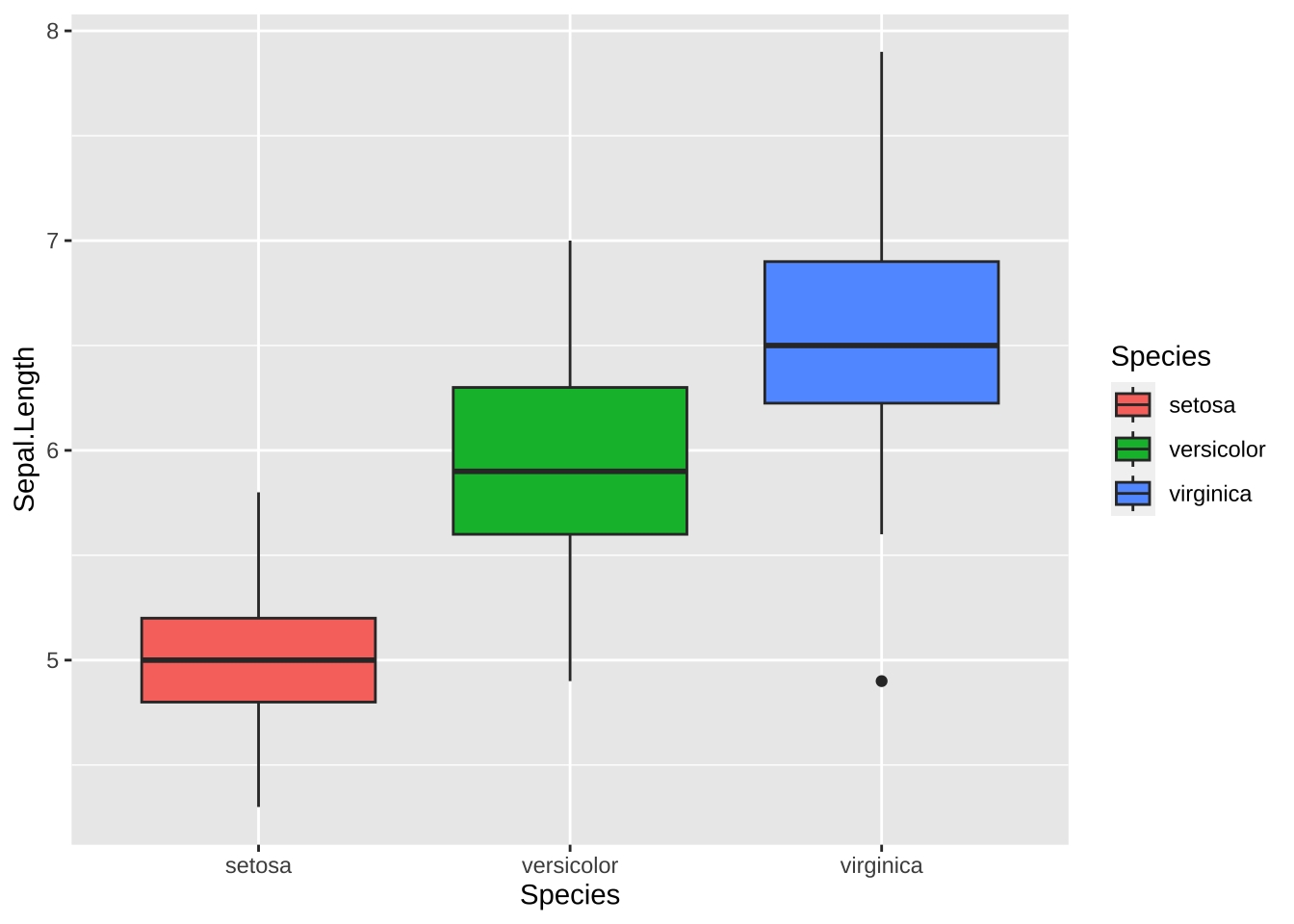
19.3.1 ヒストグラム Histogram
Visualize the distribution of a single continuous variable by dividing the x axis into bins and counting the number of observations in each bin. Histograms (geom_histogram()) display the counts with bars; frequency polygons (geom_freqpoly()) display the counts with lines. Frequency polygons are more suitable when you want to compare the distribution across the levels of a categorical variable.
単一の連続変数の分布を可視化するために、x軸をビンに分割し、各ビン内の観測値の数を数えます。ヒストグラム(geom_histogram())は、棒で数を表示します。一方、頻度多角形(geom_freqpoly())は、数を線で表示します。頻度多角形は、カテゴリ変数のレベル間の分布を比較したい場合により適しています。
説明ビデオです。https://vimeo.com/221607341
ggplot(data = df_iris, aes(x = Sepal.Length)) +
geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.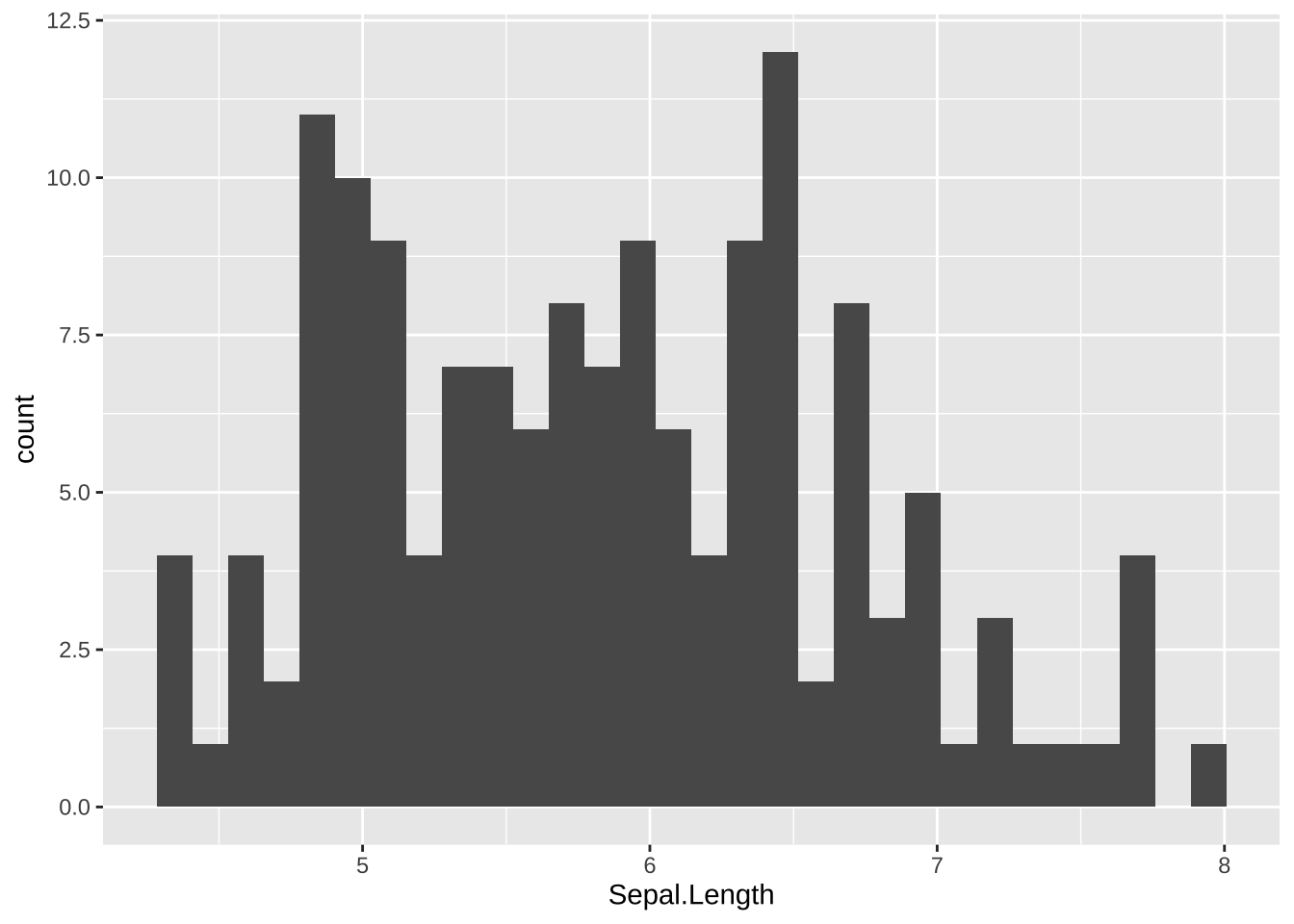
枠(bins)を幾つに分けるか、または枠の幅を指定するようにとのメッセージが表示されます。
枠(bins)の数を変更するには bins = <number> を使います。幅を指定するときは、binwidth = <number> とします。
最初の例では、枠の個数を(初期設定では30になっているものを)10個とし、二つ目の例では、幅を1にしています。
ggplot(data = df_iris, aes(x = Sepal.Length)) +
geom_histogram(bins = 10)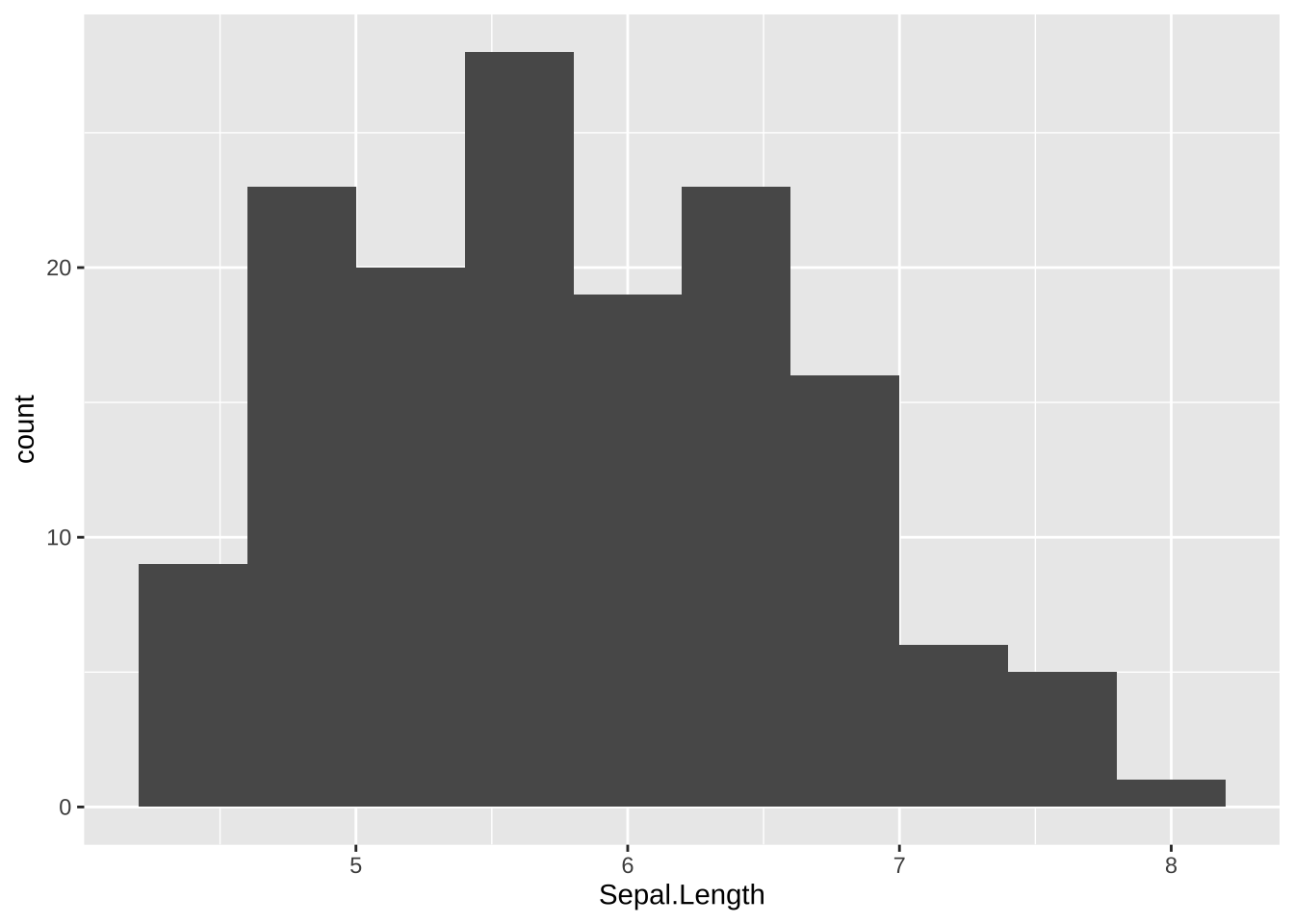
ggplot(data = df_iris, aes(x = Sepal.Length)) +
geom_histogram(binwidth = 1)
頻度多角形(geom_freqpoly())を使うと以下のようになります。Species ごとに比べたり、色をつけたりもできます。
ggplot(data = df_iris, aes(x = Sepal.Length)) +
geom_freqpoly()
#> `stat_bin()` using `bins = 30`. Pick better value with
#> `binwidth`.
ggplot(data = df_iris, aes(x = Sepal.Length, color = Species)) +
geom_freqpoly(bins = 10)
滑らかな曲線にするときは、density plot を使います。alpha は透明度で 0 から 1 の値で指定します。数が小さい方が薄くなります。color で線の色もあわせて設定することも可能です。いろいろと試してみてください。
ggplot(data = df_iris, aes(x = Sepal.Length, fill = Species)) +
geom_density(alpha = 0.5)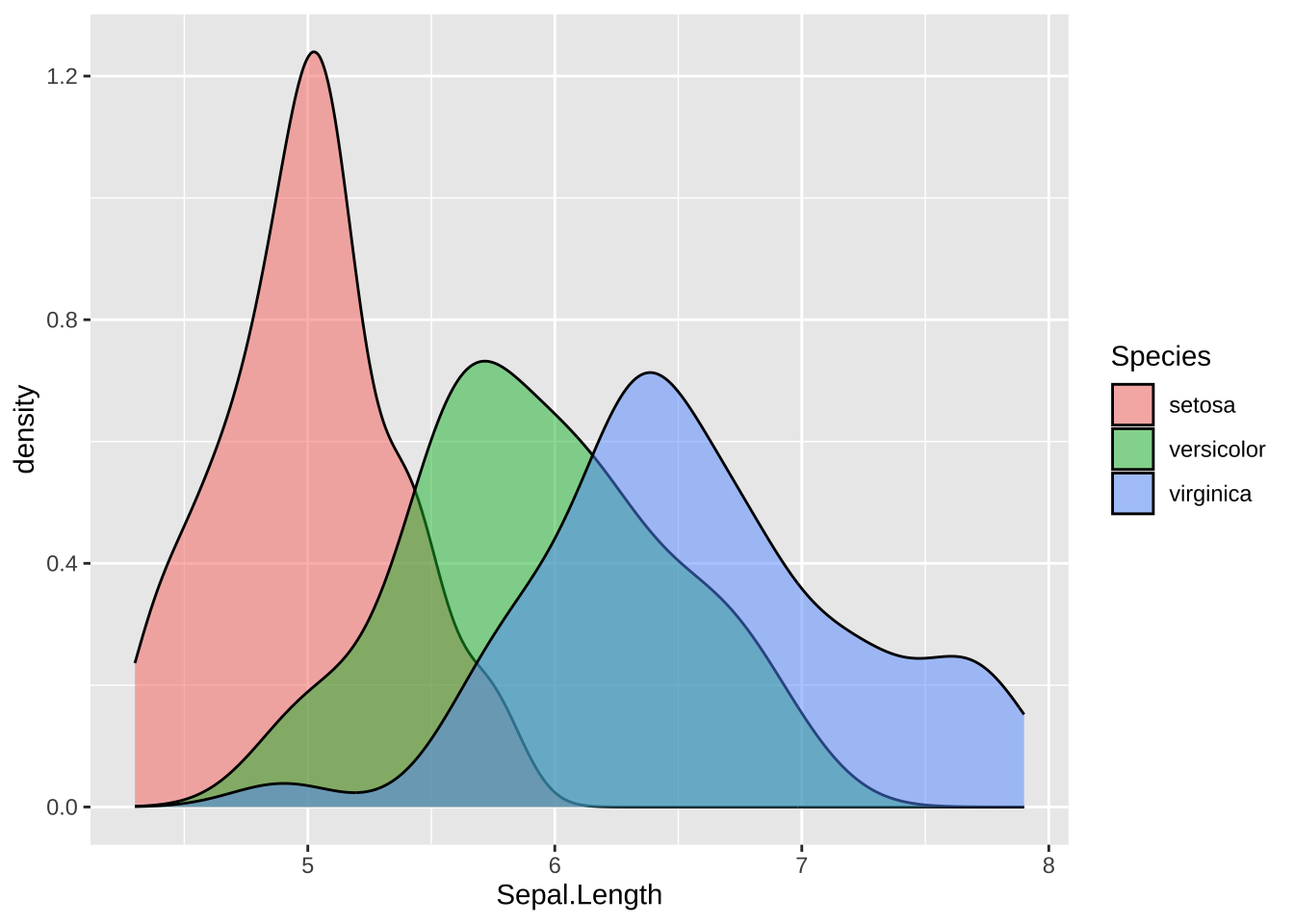
19.3.2 線形モデル Data Modeling
回帰直線を加えたり、他の近似曲線を加えることも可能です。グラフとしても直感的理解を助けますが、統計的な扱いについては、Modeling で説明します。
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)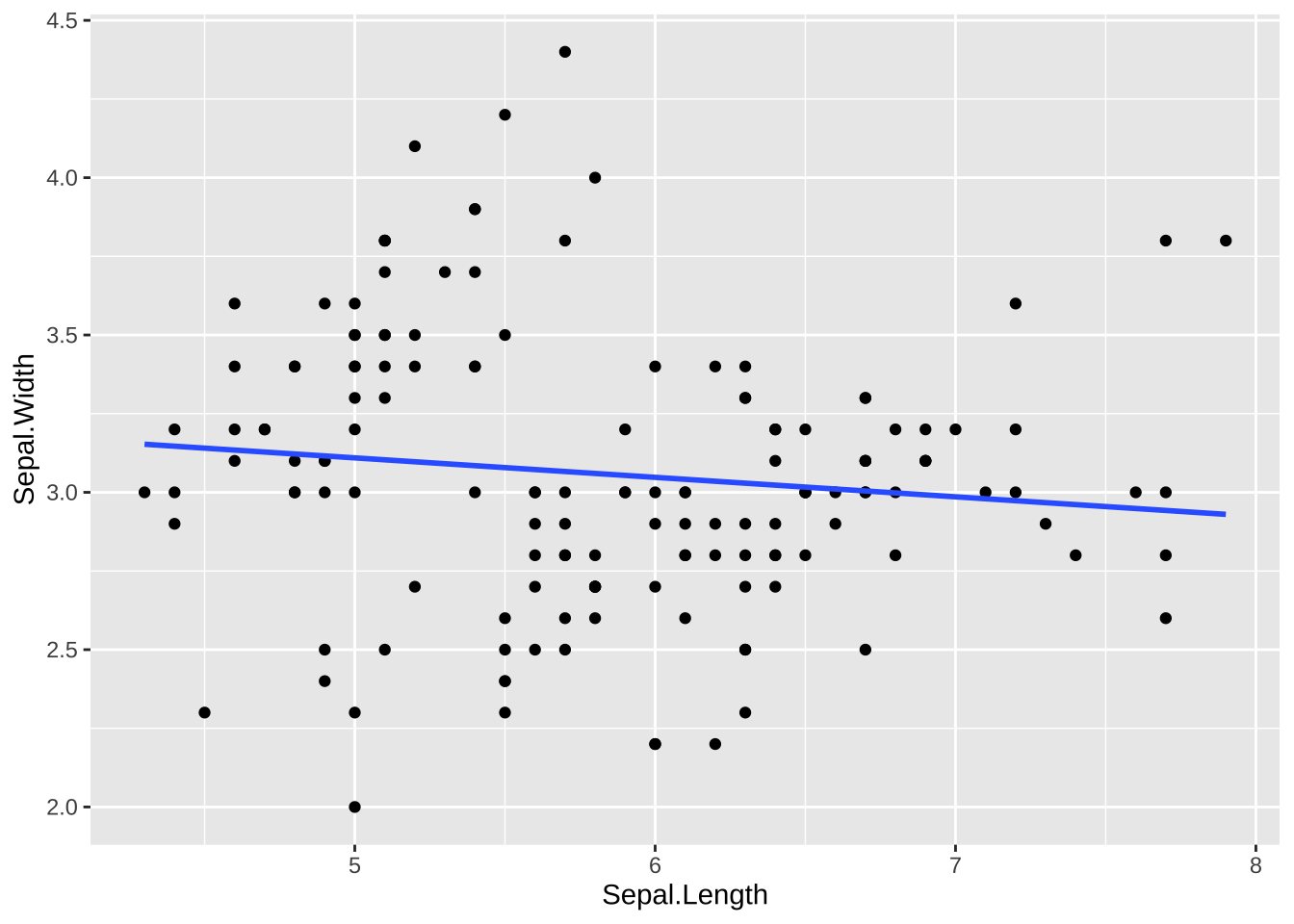
ggplot(data = df_iris, aes(x = Sepal.Length, y = Sepal.Width)) +
geom_point() +
geom_smooth()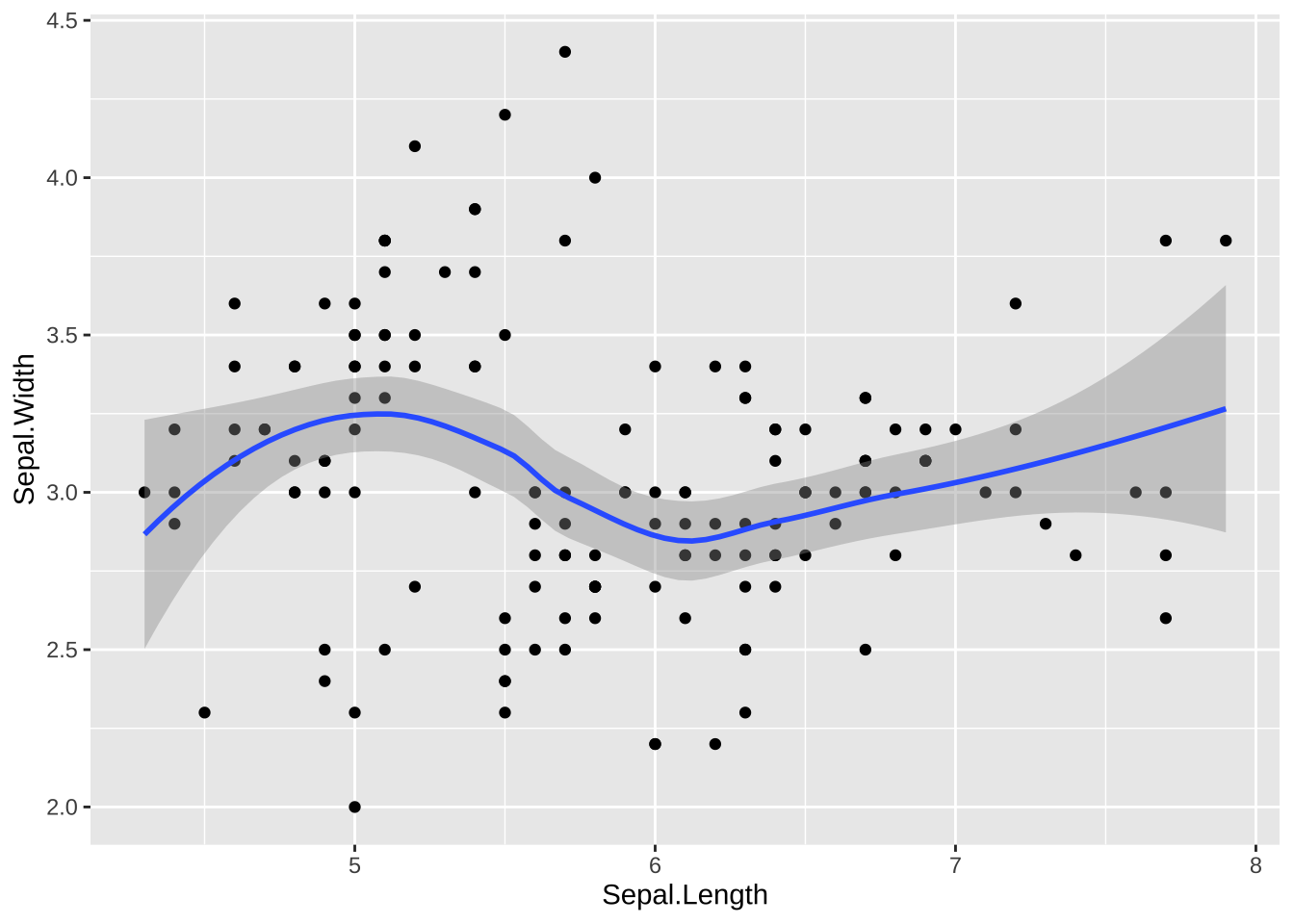
19.4 例から学ぶ ggplot2, I
19.4.0.1 mpg を使って
ggplot2 に含まれている、mpg(Fuel economy data from 1999 to 2008 for 38 popular models of cars - 1999年から2008年の38の型式の車の年燃費)データを使って、簡単な、散布図と、箱ひげ図を描いてみます。mpg の変数などについては、Help で調べてください。
manufacturer は、メーカー名、model は、型式、disp は、排気量(単位:リットル)、year は年式、cyl は、気筒数、trans は、オートマかマニュアルか、drv は、f が前輪駆動、r は後輪駆動、4 は四輪駆動、cty は街中での燃費(1ガロンで何マイル走るか)、hwy は高速道路での燃費(1ガロンで何マイル走るか)、fl 燃料の種類、class タイプ
df_mpg <- ggplot2::mpg
df_mpg
glimpse(df_mpg)
#> Rows: 234
#> Columns: 11
#> $ manufacturer <chr> "audi", "audi", "audi", "audi", "audi…
#> $ model <chr> "a4", "a4", "a4", "a4", "a4", "a4", "…
#> $ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.…
#> $ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2…
#> $ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6…
#> $ trans <chr> "auto(l5)", "manual(m5)", "manual(m6)…
#> $ drv <chr> "f", "f", "f", "f", "f", "f", "f", "4…
#> $ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 2…
#> $ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 2…
#> $ fl <chr> "p", "p", "p", "p", "p", "p", "p", "p…
#> $ class <chr> "compact", "compact", "compact", "com…
ggplot(data = df_mpg) + geom_point(mapping = aes(x = displ, y = hwy))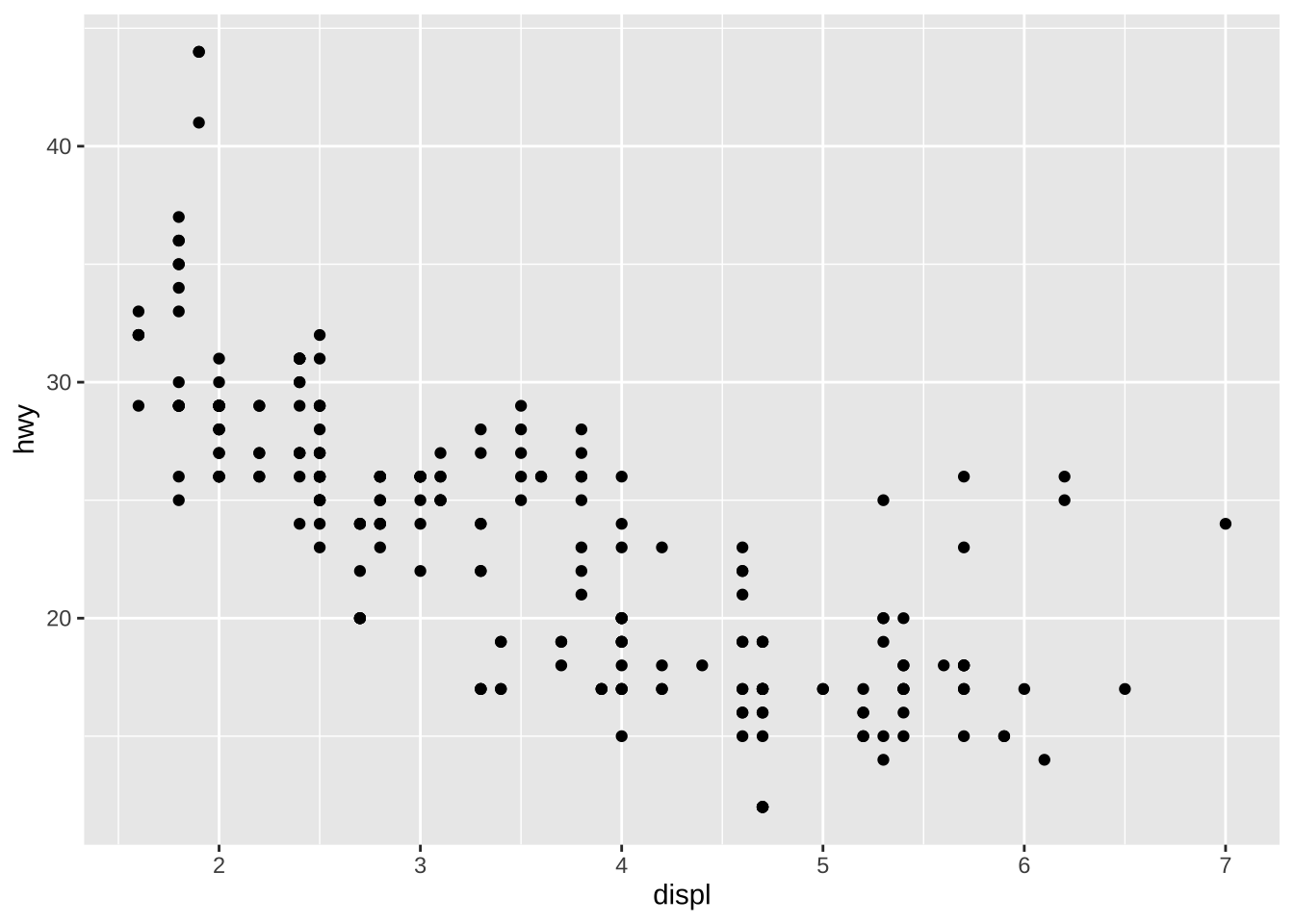
ggplot(data = df_mpg) + geom_boxplot(mapping = aes(x = class, y = hwy))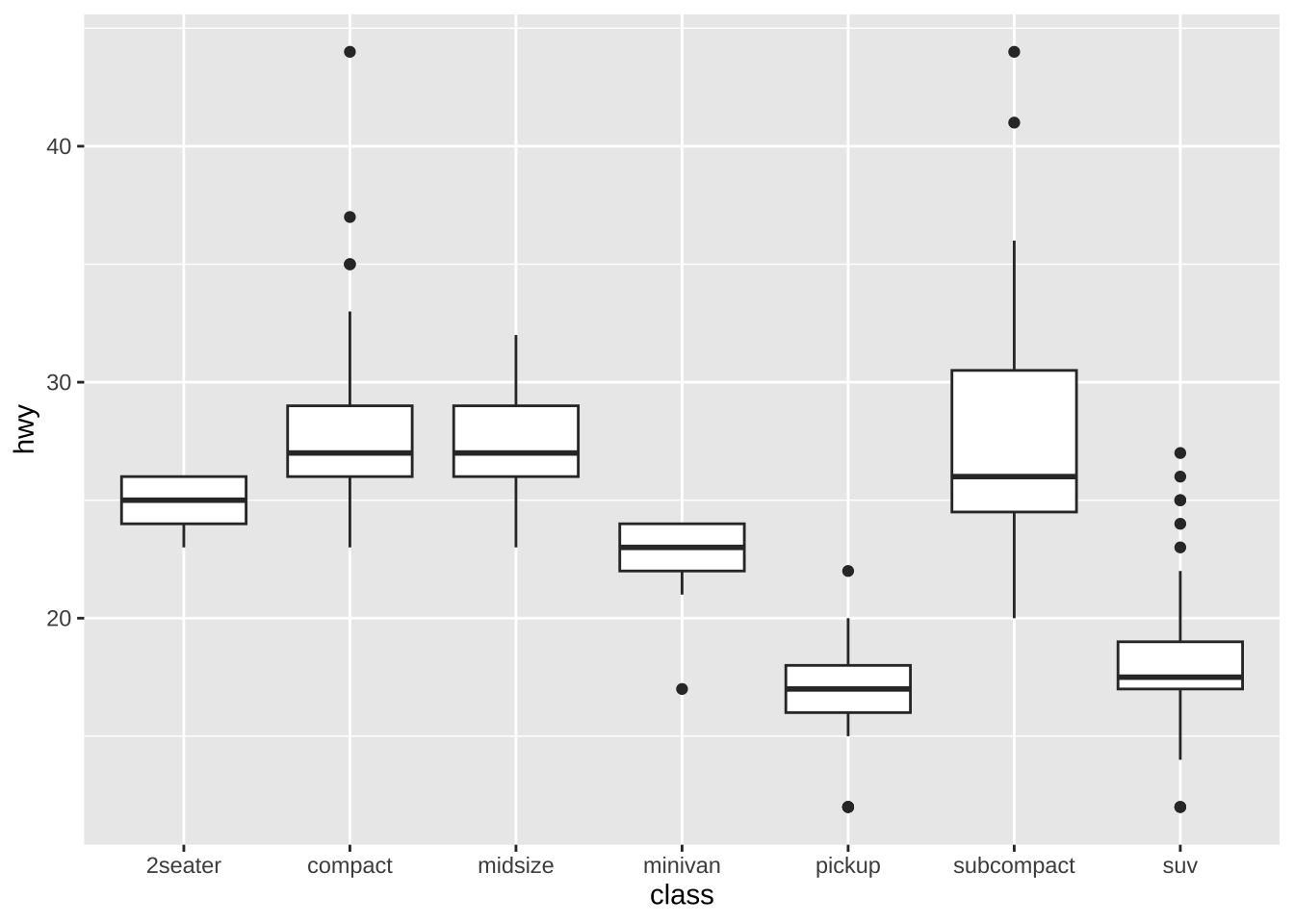
data = df_mpgでデータを指定します。どのようなグラフにするか、幾何関数(Geometric Function)を指定します。散布図では、
geom_pont()、箱ひげ図では、geom_boxplot()などです。-
x 軸、y 軸などに対応する変数の写像(mapping)を指定します。
散布図では、
dspl(displacemnt エンジンの排気量(単位 リットル))を x 軸に、hwy高速道路で1ガロンで走れる距離(単位 マイル)を y 軸に割り当てています。箱ひげ図では、
class車の型式を、x 軸に、hwy高速道路で1ガロンで走れる距離(単位 マイル)を y 軸に割り当てています。
記号的に書くと、下のようになっています。
ggplot(data = <DATA>) + <GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))
19.5 例から学ぶ ggplot2, II
19.5.1 df_wdi, df_wdi_extra
前の章の Tidyverse で読み込み、概観した、世界開発指標(World Development Indicators)のデータを使います。参照:WDI のデータ
WDI の使い方は、世界銀行の部分で紹介しますが、はじめてのデータサイエンスの例でも紹介したように、データコードを利用して、データを読み込みます。ここでは、出生時の平均寿命と、一人当たりの GDP と、総人口のデータを使います。
- SP.DYN.LE00.IN: Life expectancy at birth, total (years) 出生時の平均寿命
- SP.POP.TOTL: Population, total 総人口
- NY.GDP.PCAP.KD: GDP per capita (constant 2015 US$) 一人当たりの GDP
次のコードで読み込みます。
df_wdi <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL",
gdpPercap = "NY.GDP.PCAP.KD")
)#> Rows: 16758 Columns: 7
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, iso2c, iso3c
#> dbl (4): year, lifeExp, pop, gdpPercap
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_wdi_extra <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL",
gdpPercap = "NY.GDP.PCAP.KD"),
extra = TRUE
)すこし、追加情報を付加したものも取得しておきます。
#> Rows: 16758 Columns: 15
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (6): year, lifeExp, pop, gdpPercap, longitude, lati...
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_wdi19.5.2 棒グラフ(bar graph and column graph)
まずは、年ごと、指標(indicator)ごとに、どの程度データがあるか見てみましょう。
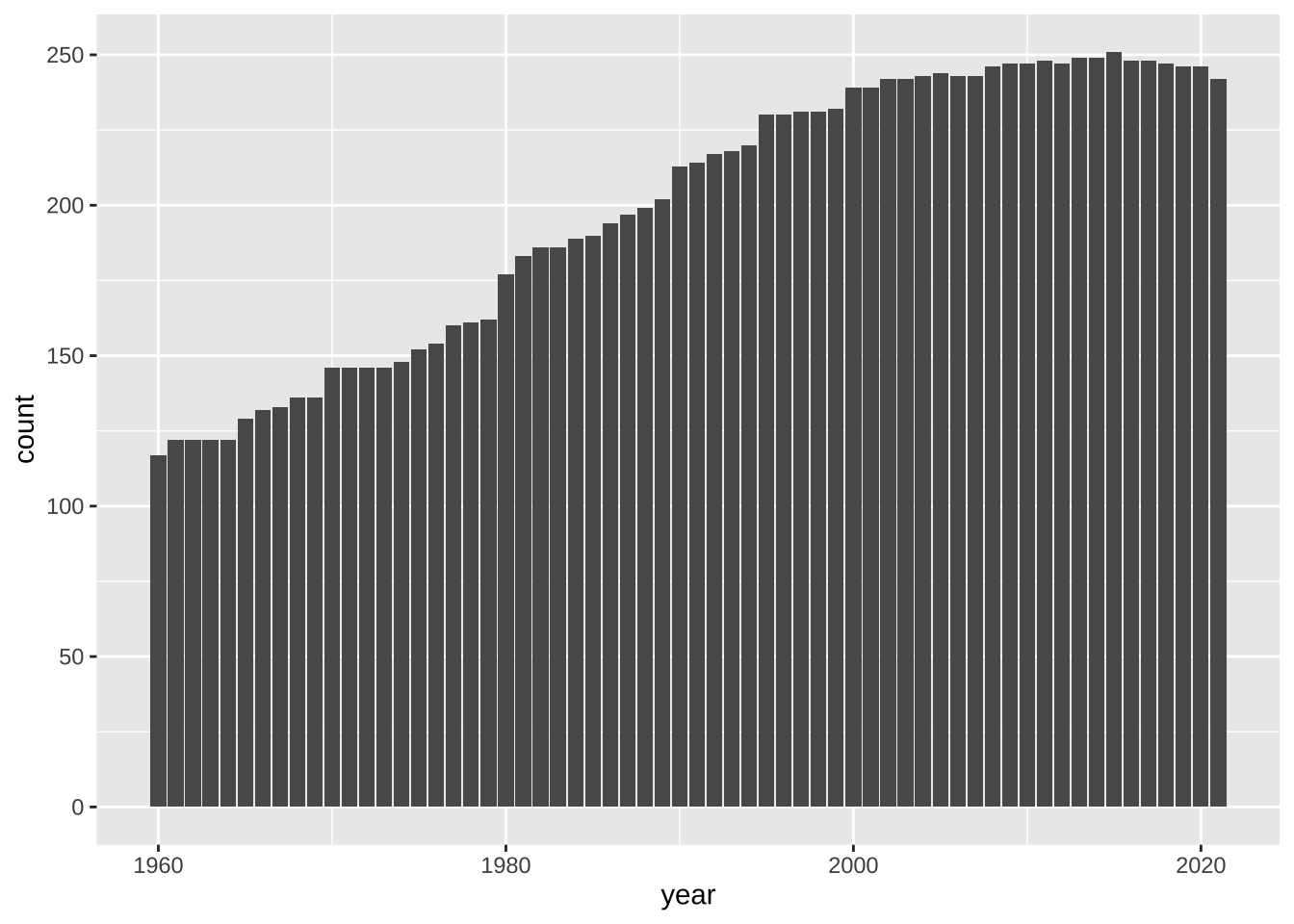
最初に、三つの indicator が どれもが、NA でない行だけを選択していますから、三つの指標がすべて値がある、データを年ごとに数えてグラフにしたものが、上のものになっています。表にすると次のようになっています。
同じような棒グラフですが、それぞれの値をグラフにする場合には、geom_col() を使います。
regions <- df_wdi_extra |> drop_na(region) |>
filter(region != "Aggregates") |> distinct(region) |> pull()
regions
#> [1] "South Asia"
#> [2] "Europe & Central Asia"
#> [3] "Middle East & North Africa"
#> [4] "East Asia & Pacific"
#> [5] "Sub-Saharan Africa"
#> [6] "Latin America & Caribbean"
#> [7] "North America"
df_wdi_extra |> filter(income == "Aggregates", year == 2020) |>
filter(country %in% regions) |>
ggplot(aes(y = country, x = lifeExp)) + geom_col()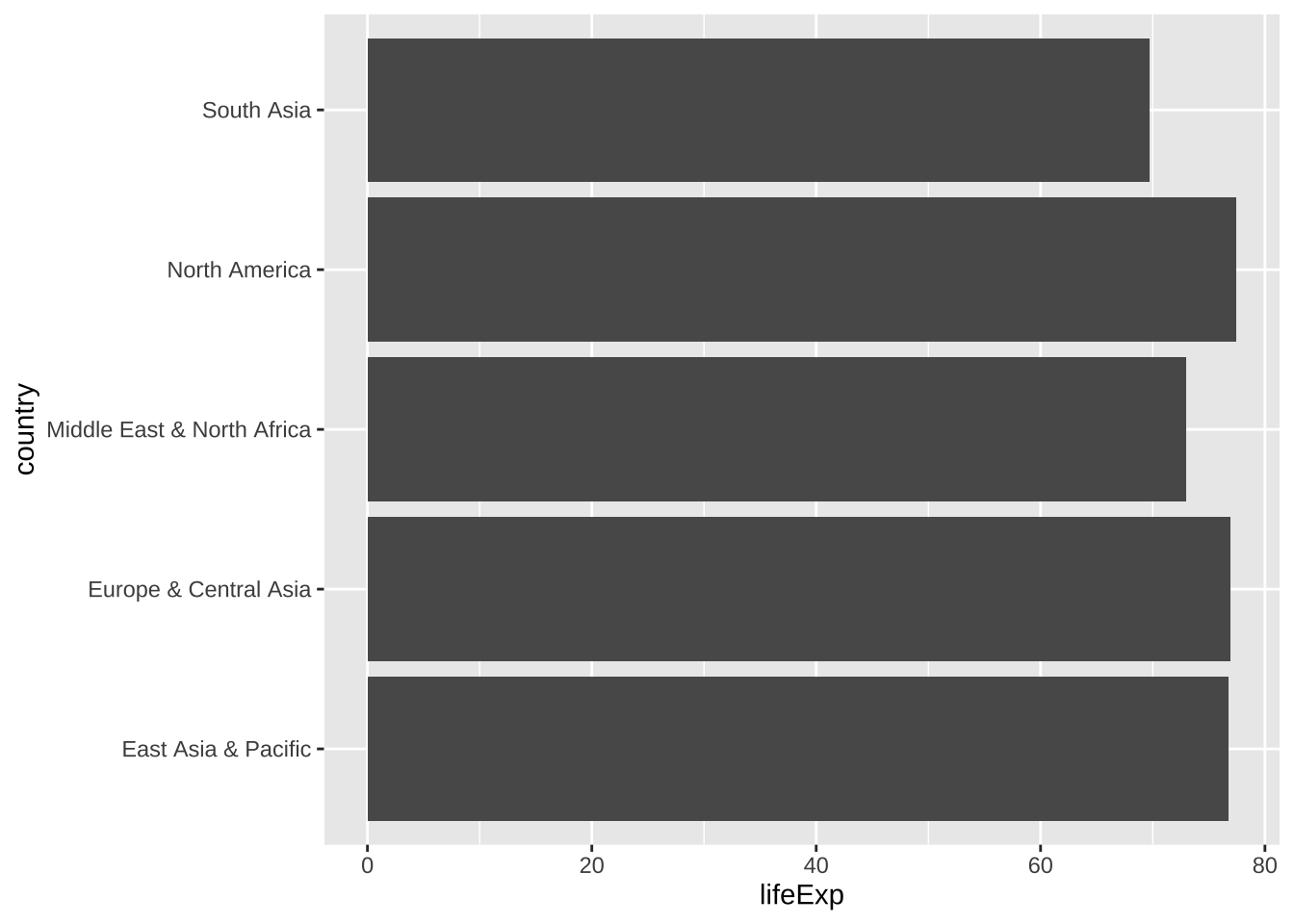
df_wdi_extra |> filter(income == "Aggregates", year == 2020) |>
filter(country %in% regions) |>
ggplot(aes(y = country, x = pop)) + geom_col()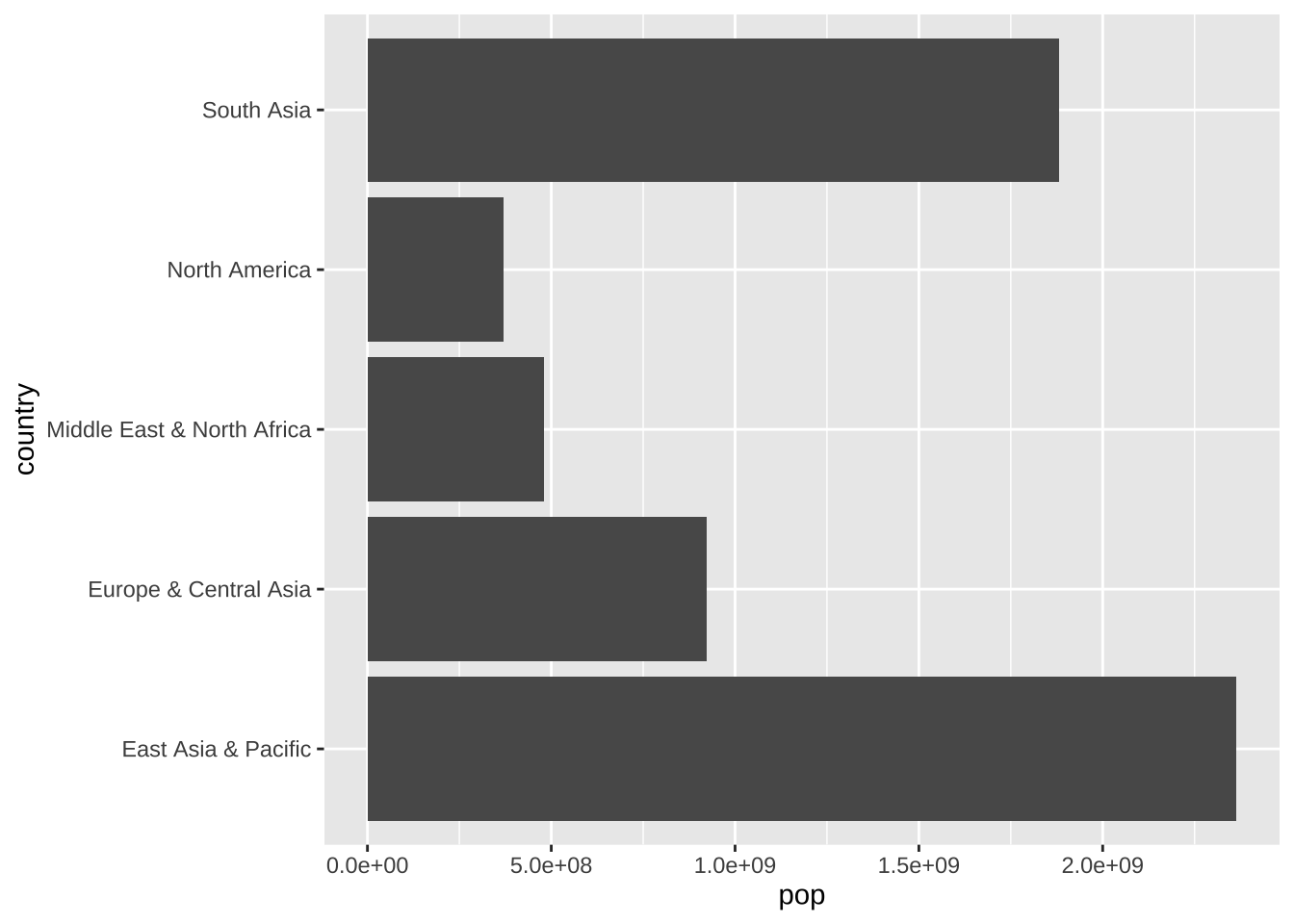
df_wdi_extra |> filter(income == "Aggregates", year == 2020) |>
filter(country %in% regions) |>
ggplot(aes(y = country, x = gdpPercap)) + geom_col()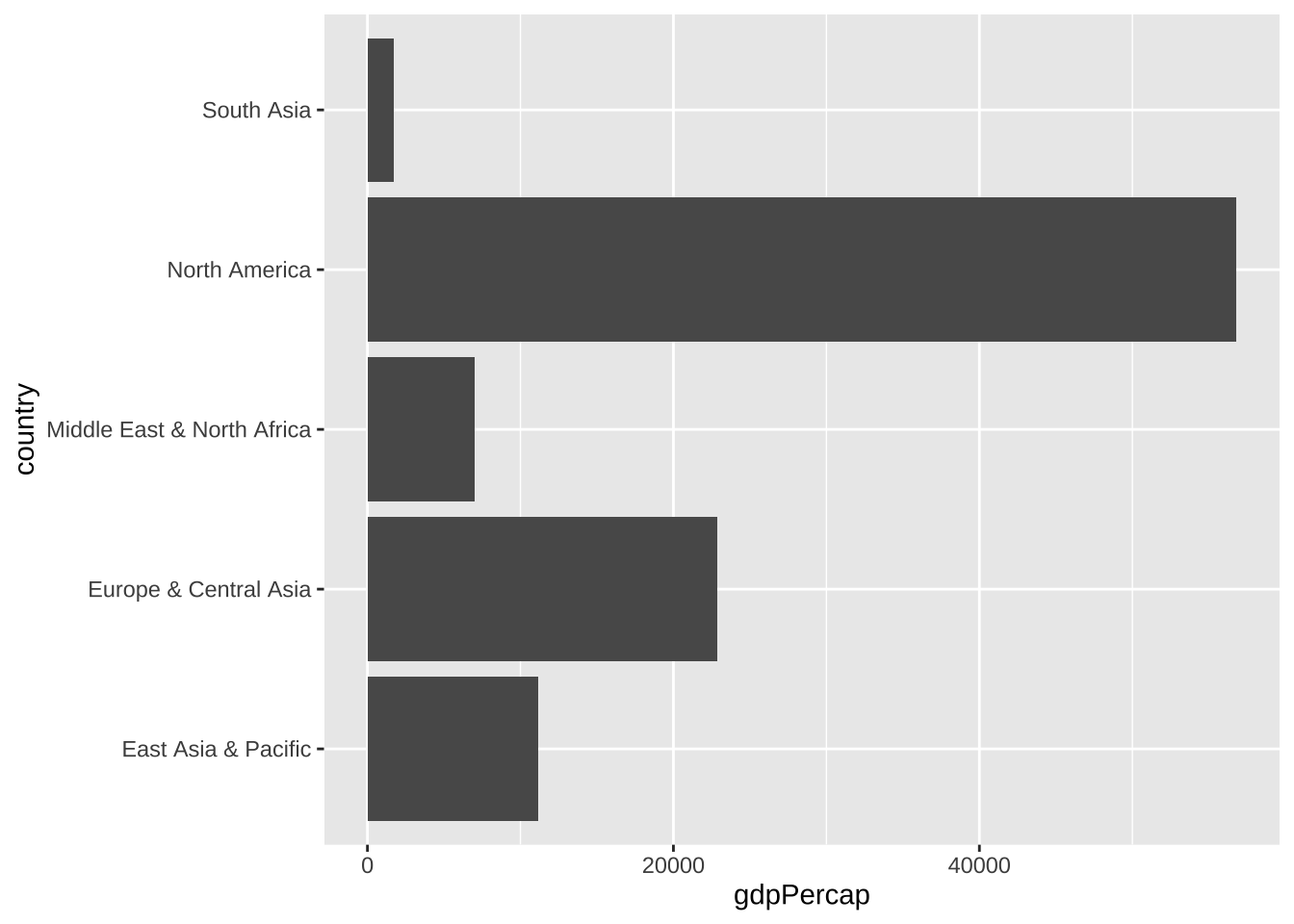
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(y = region, fill = income)) + geom_bar()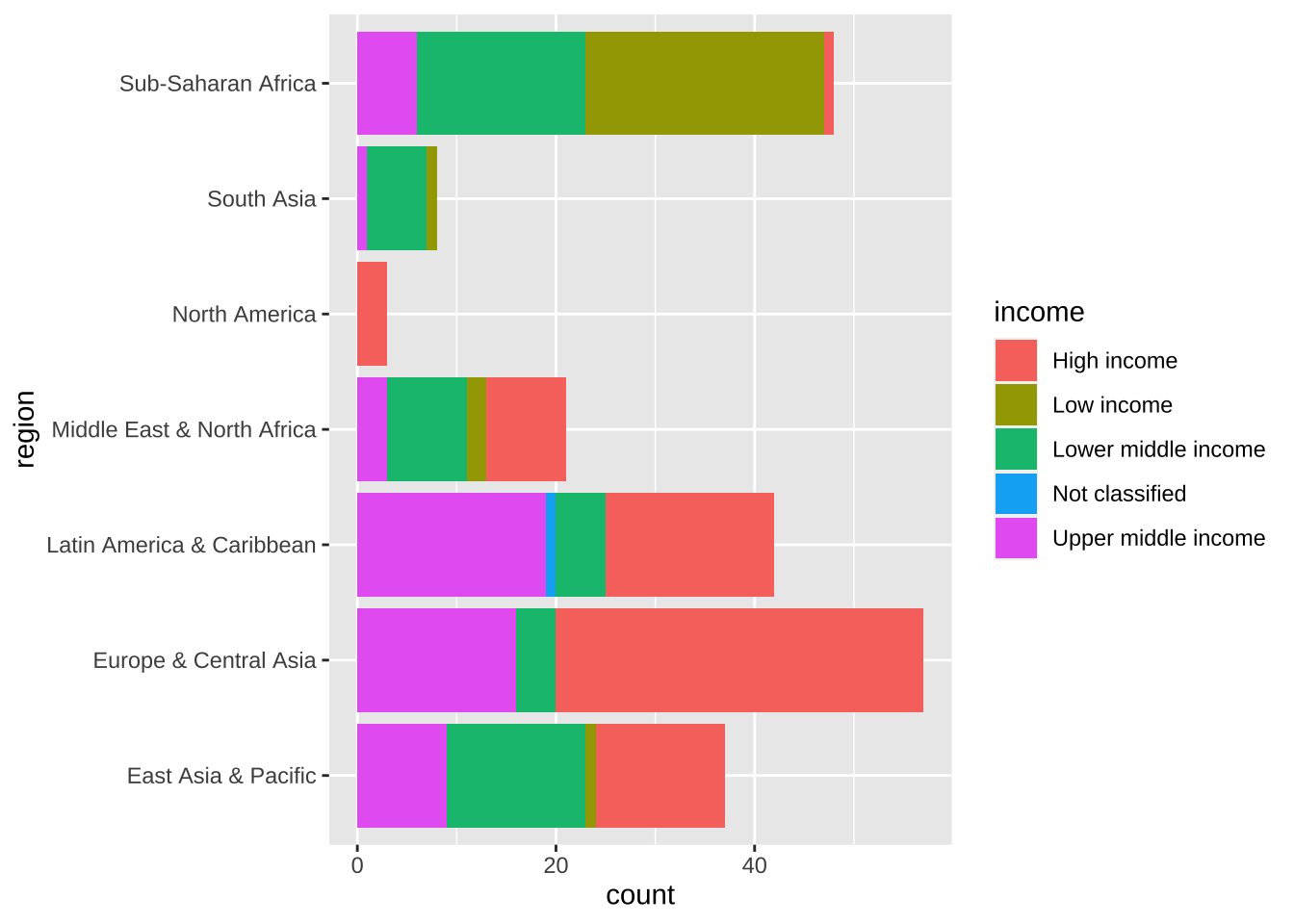
19.5.3 棒グラフの応用
最後のグラフを例にとって、いくつかのコメントをしておきます。
19.5.3.1 概要
地域のリストを regions に入れてありますから、2020 年のデータを取り出し、その中で、それぞれの国ごとのデータではなく、集計してあるもの(Aggregates)を選択してあります。そして、地域ごとにグループ化します。
まず、地域ごとにまとめて、国がいくつあるかは次のように表にすることもできます。また、収入の多寡のグループにも分けたものをその下に加えておきます。
これらを、棒グラフで表示しています。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region) |> summarize(n = n())
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region, income) |> summarize(n = n())
#> `summarise()` has grouped output by 'region'. You can
#> override using the `.groups` argument.Y 軸に、地域名を取って、geom_bar() ですから、データがいくつあるかで棒グラフにしています。そのときに、fill = income としていますから、収入レベルごとに、色を変えて塗りつぶし(fill)て、描いています。color は、枠に色をつけ、fill は、塗りつぶしです。
19.5.3.2 縦か横か
棒が横に伸びていますが、縦にすることも可能です。それには、y = region と書いてあるものを、x = region とすればできます。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) + geom_bar()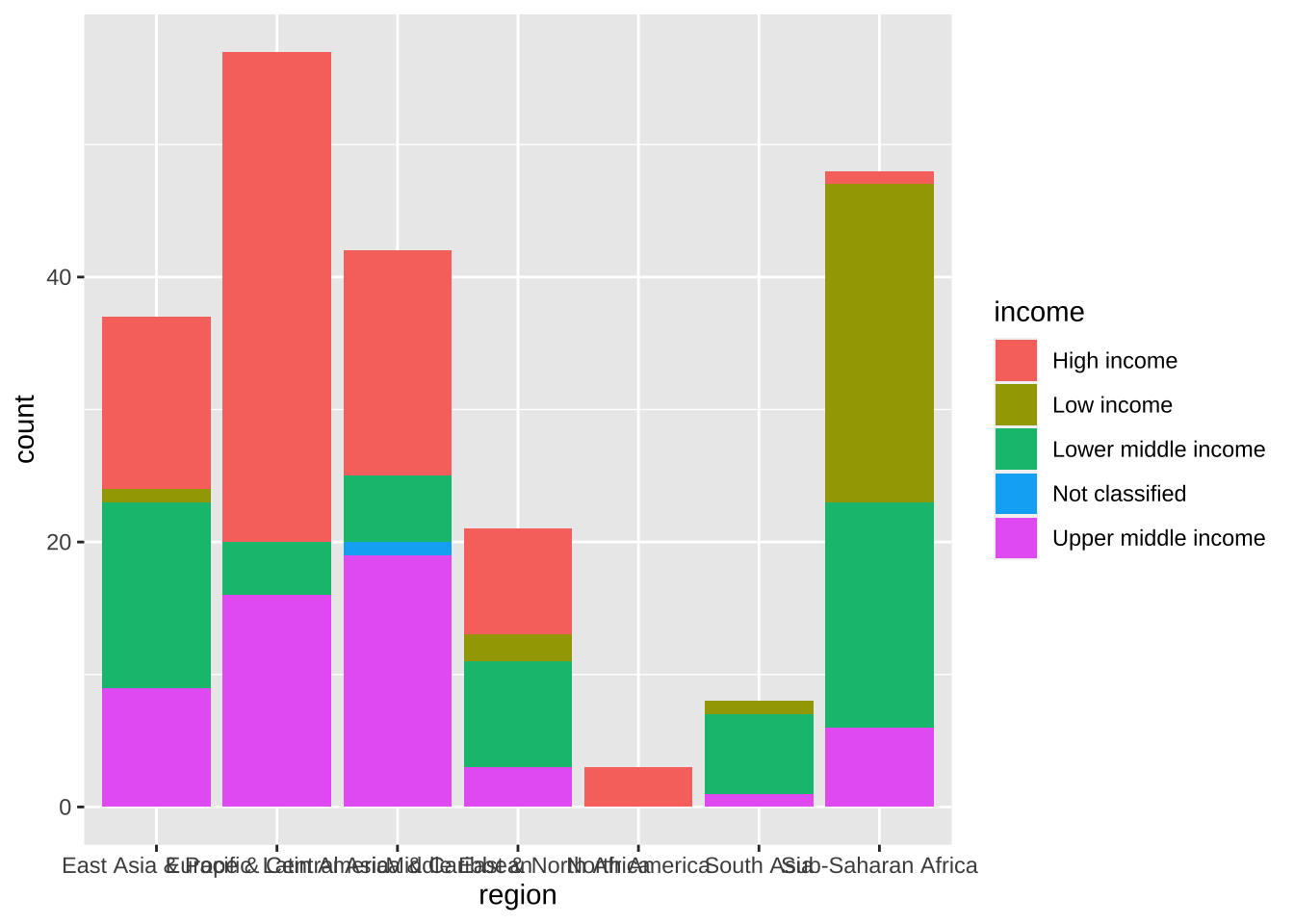
19.5.3.3 地域名
なぜ、横にしたか、見当がついたかと思います。縦にすると、地域名が長くて重なってしまうのですね。もちろん、それを、改善する手がいくつかあります。1つ目は、地域名を縦にしたり、角度を付ける方法。theme を使い、中に角度を書きます。実は、それだけだと、ちょっと重なってしまうので、hjust の変数で調節しています。垂直方向の調節は、vjust です。数はいろいろと変更してみてください。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) + geom_bar() +
theme(axis.text.x = element_text(angle = 45, hjust=1))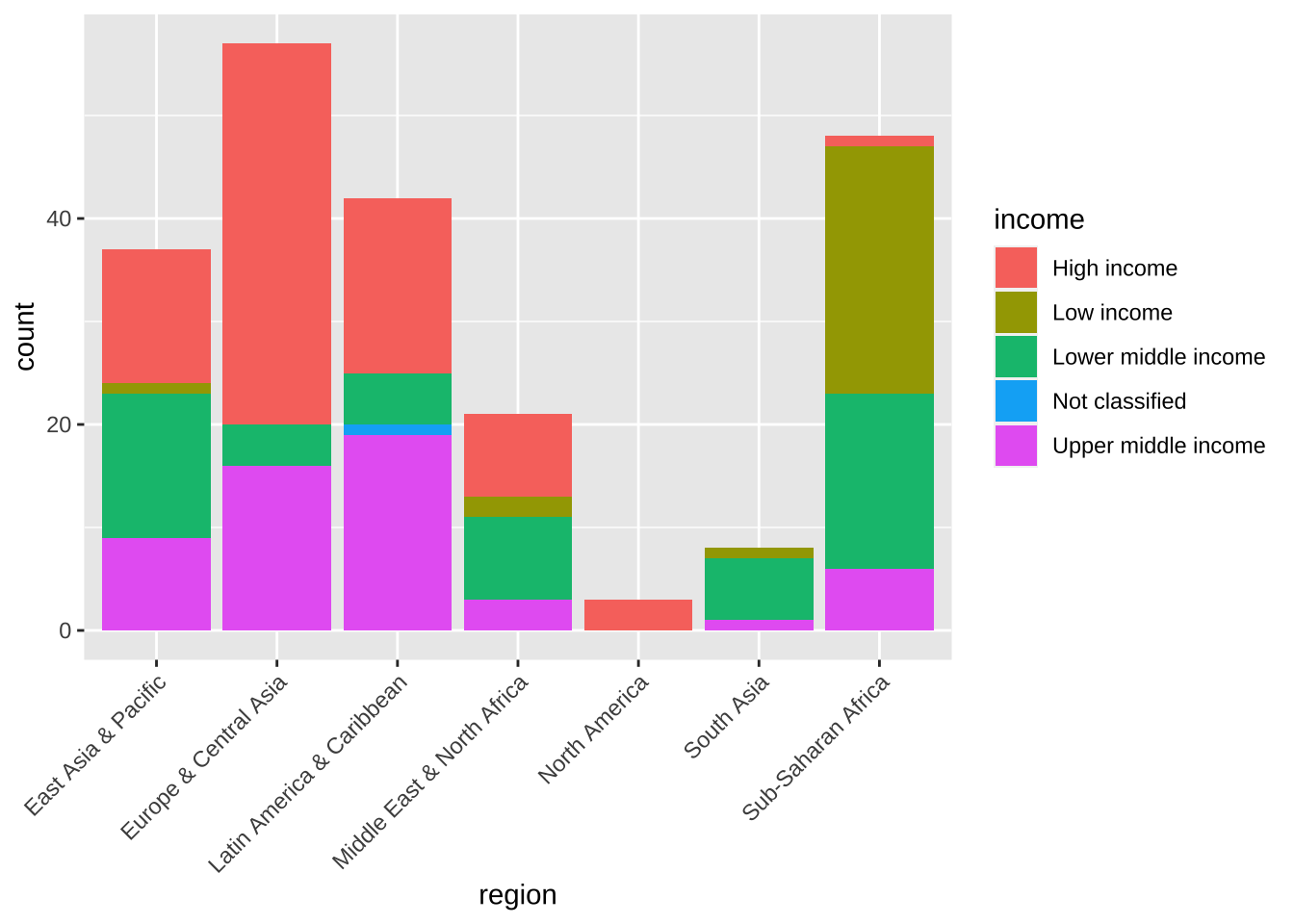
もう一つは折り返す方法です。こちらの方が、良いかもしれません。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) + geom_bar() +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8))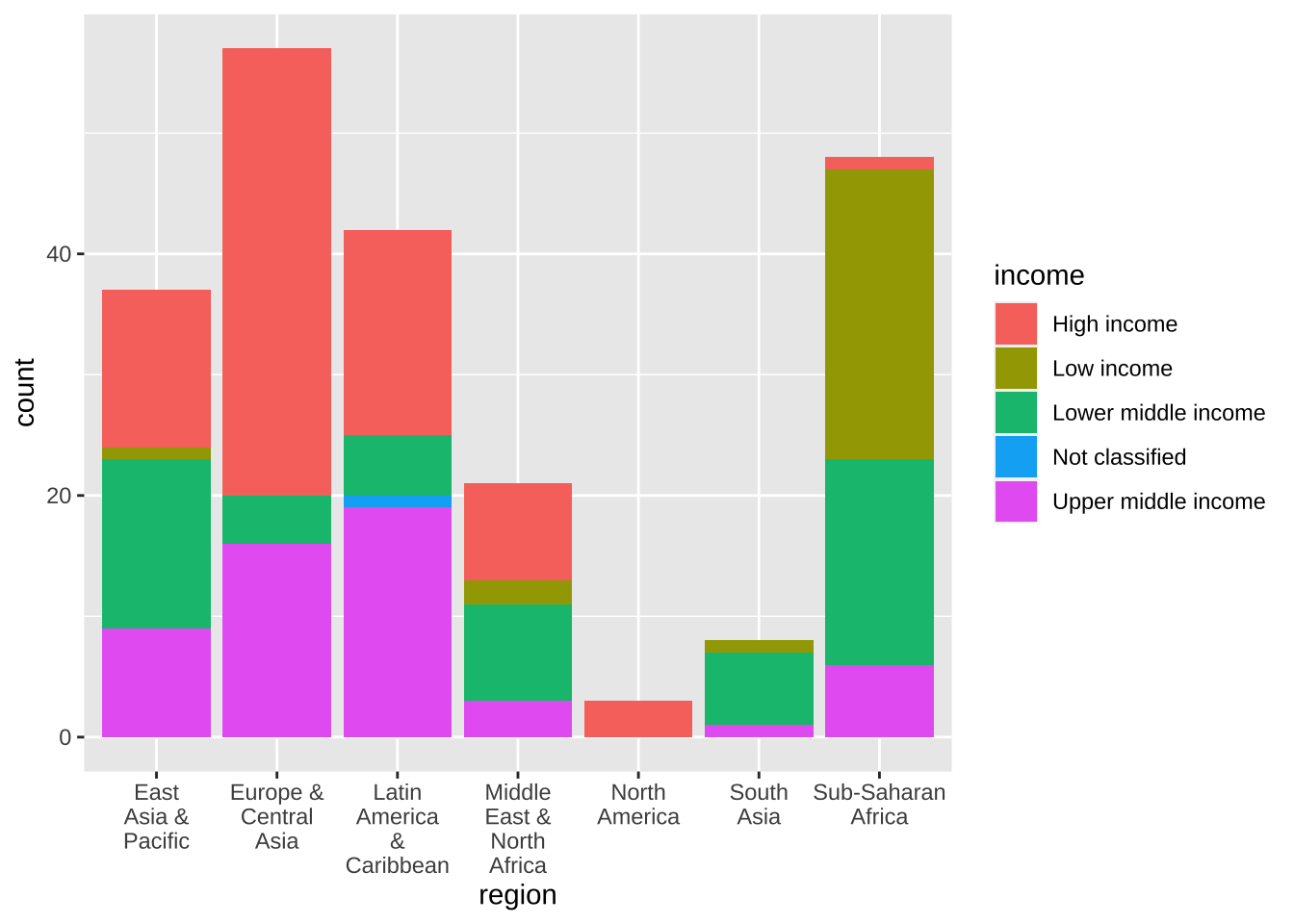
もし、fill の方の凡例(legend)も短くしたければ、次のようにします。width のあとの数字は、適切な数を選んでください。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) + geom_bar() +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) 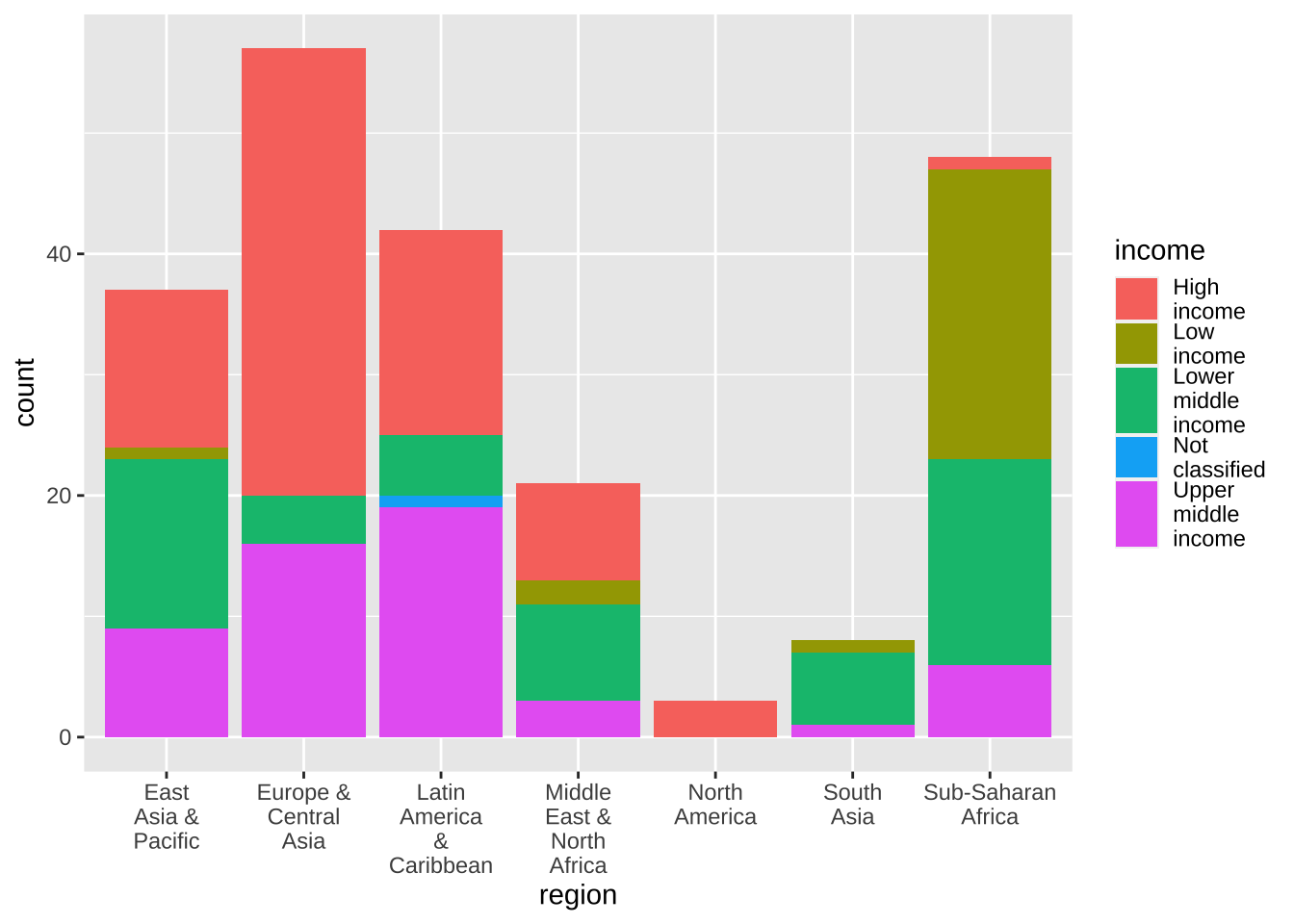
19.5.3.4 棒グラフに黒枠
変わり目が見にくければ、黒線で囲むことも可能です。どこに、color = “black” を入れるか、注意が必要です。少しその線を細目に するために、linewidth = 0.2 を加えました。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) +
geom_bar(color = "black", linewidth = 0.2) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) 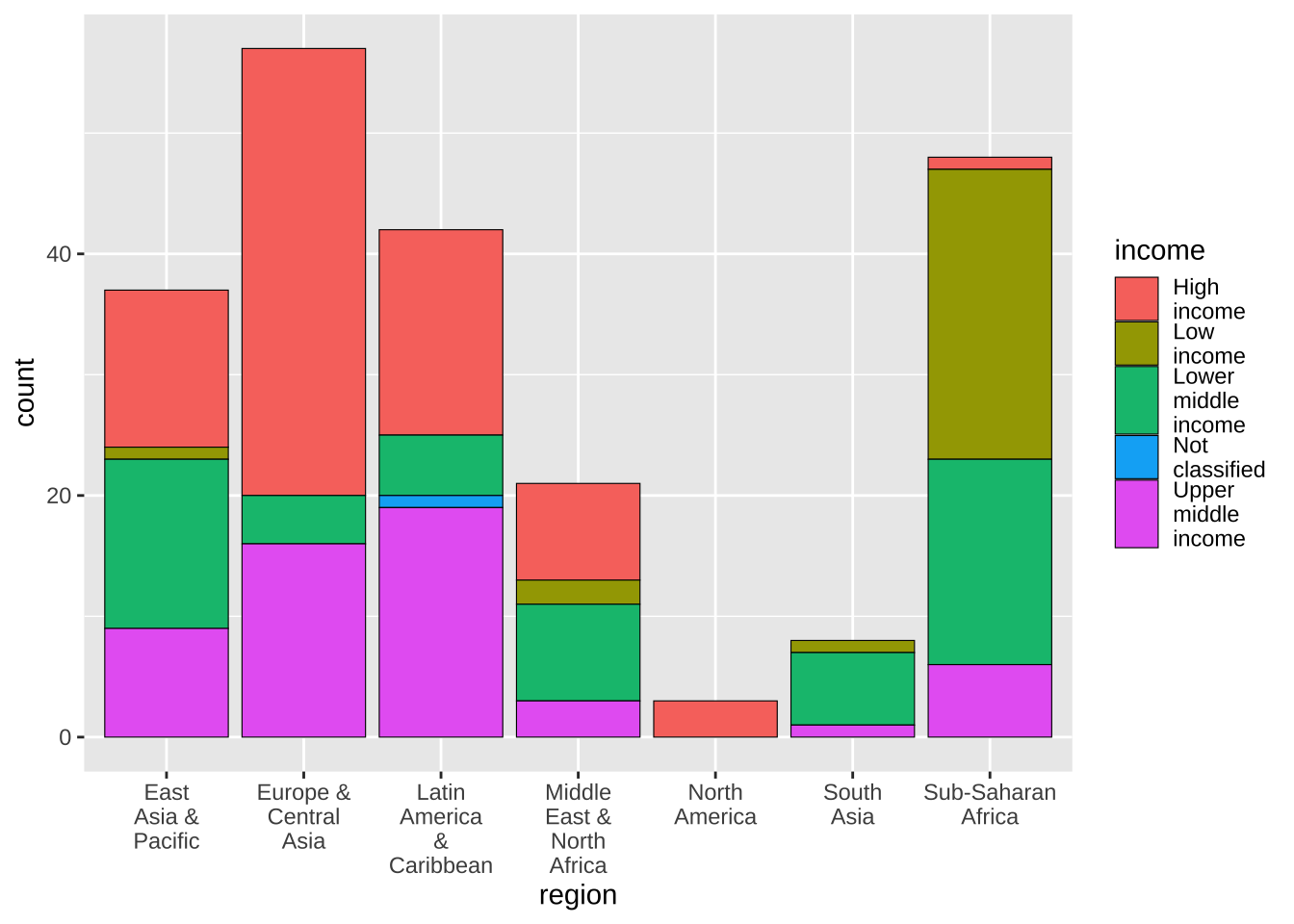
19.5.3.5 大きい順
順序は、地域のアルファベット順ですから、上のグラフで問題ありませんが、もし、大きい順、すなわち、国の数が大きい順にするとするとどうしたら良いでしょうか。少しだけ、すでに出てきた、Factor をいうものを使います。fct_infreq(region) この場合は、度数順に並べてグラフにします。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region) |>
ggplot(aes(x = fct_infreq(region), fill = income)) +
geom_bar(color = "black", linewidth = 0.2) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) 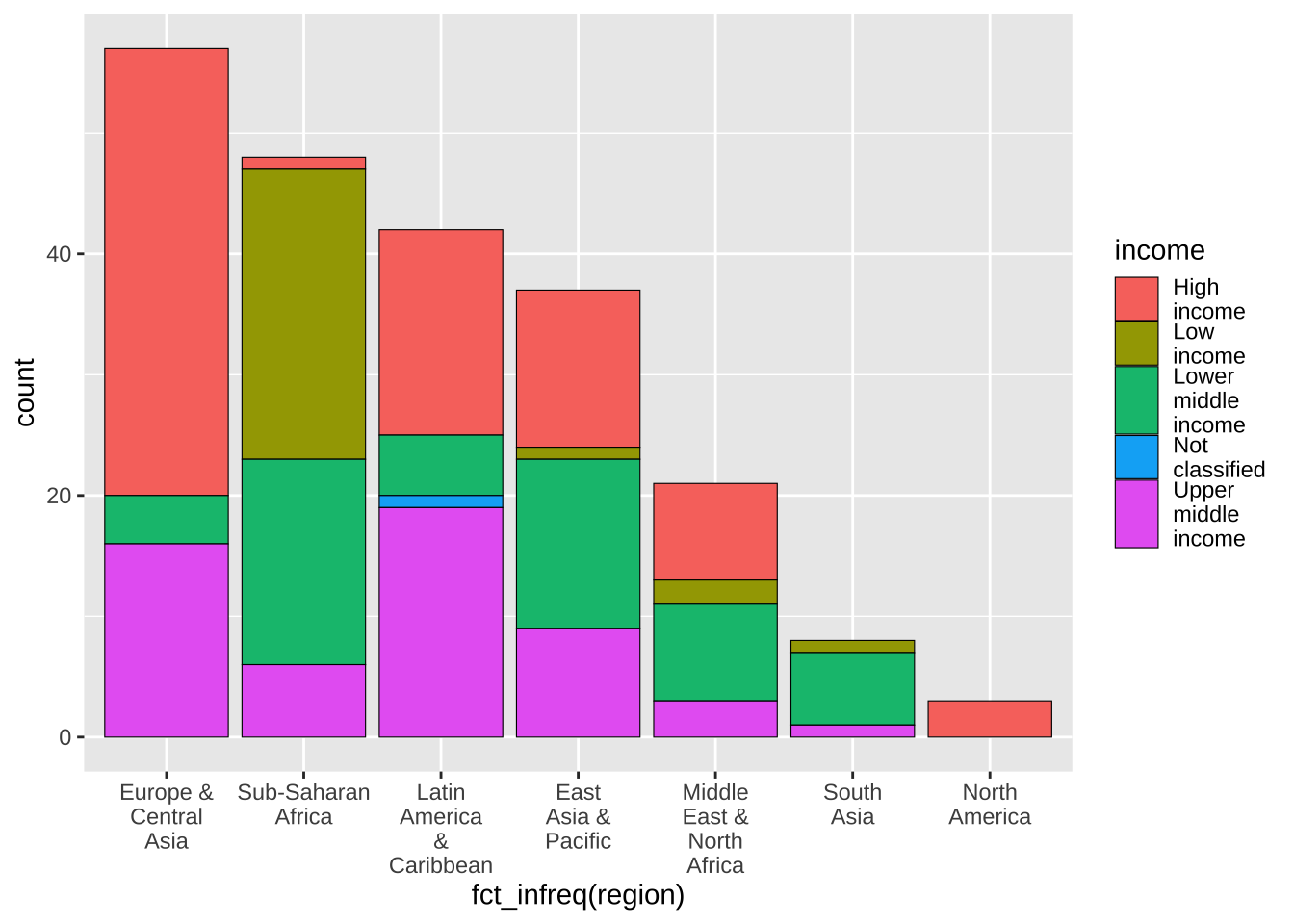
19.5.3.6 数の表示
棒グラフの上に、値を加えてみましょう。vjust の値を調節することで、ちょっと上にしたり、下にしたりできます。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region) |> mutate(n = n()) |>
ggplot(aes(x = fct_infreq(region), fill = income)) +
geom_bar(color = "black", linewidth = 0.2) +
geom_text(aes(y = n, label = n), vjust = -0.5) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8))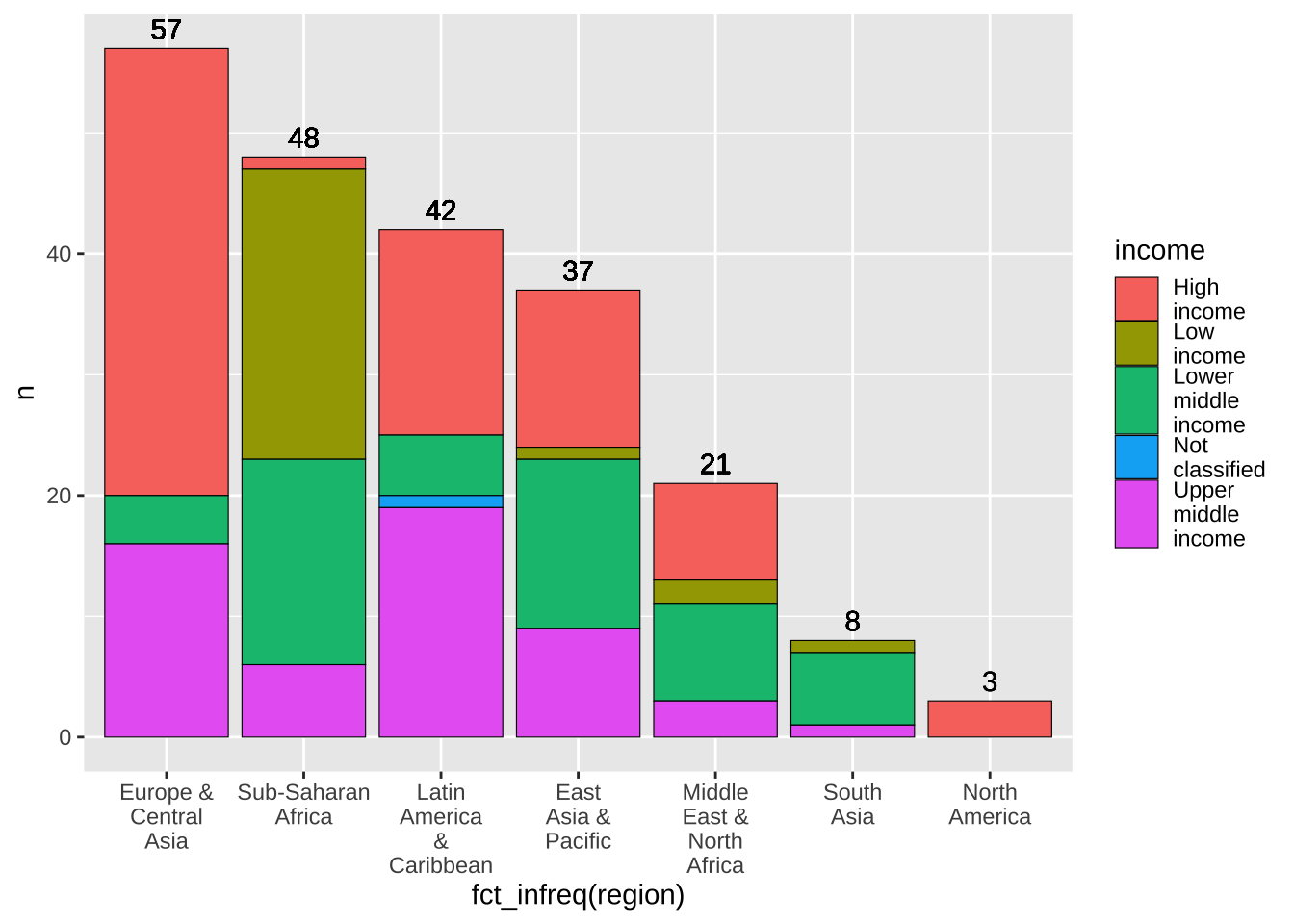
19.5.3.7 縦と横の変換
縦横は、x, y などの変数を入れ替えることで可能ですが、座標軸自体を逆に(flip)することも可能です。coord_flip() を使います。ただし、vjust で調節した部分は、hjust で調節する必要は生じます。
文字列の折り返しの幅も調整が必要かもしれません。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region) |> mutate(n = n()) |>
ggplot(aes(x = fct_infreq(region), fill = income)) +
geom_bar(color = "black", linewidth = 0.2) +
geom_text(aes(y = n, label = n), hjust = -0.5) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 12)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8))+
coord_flip()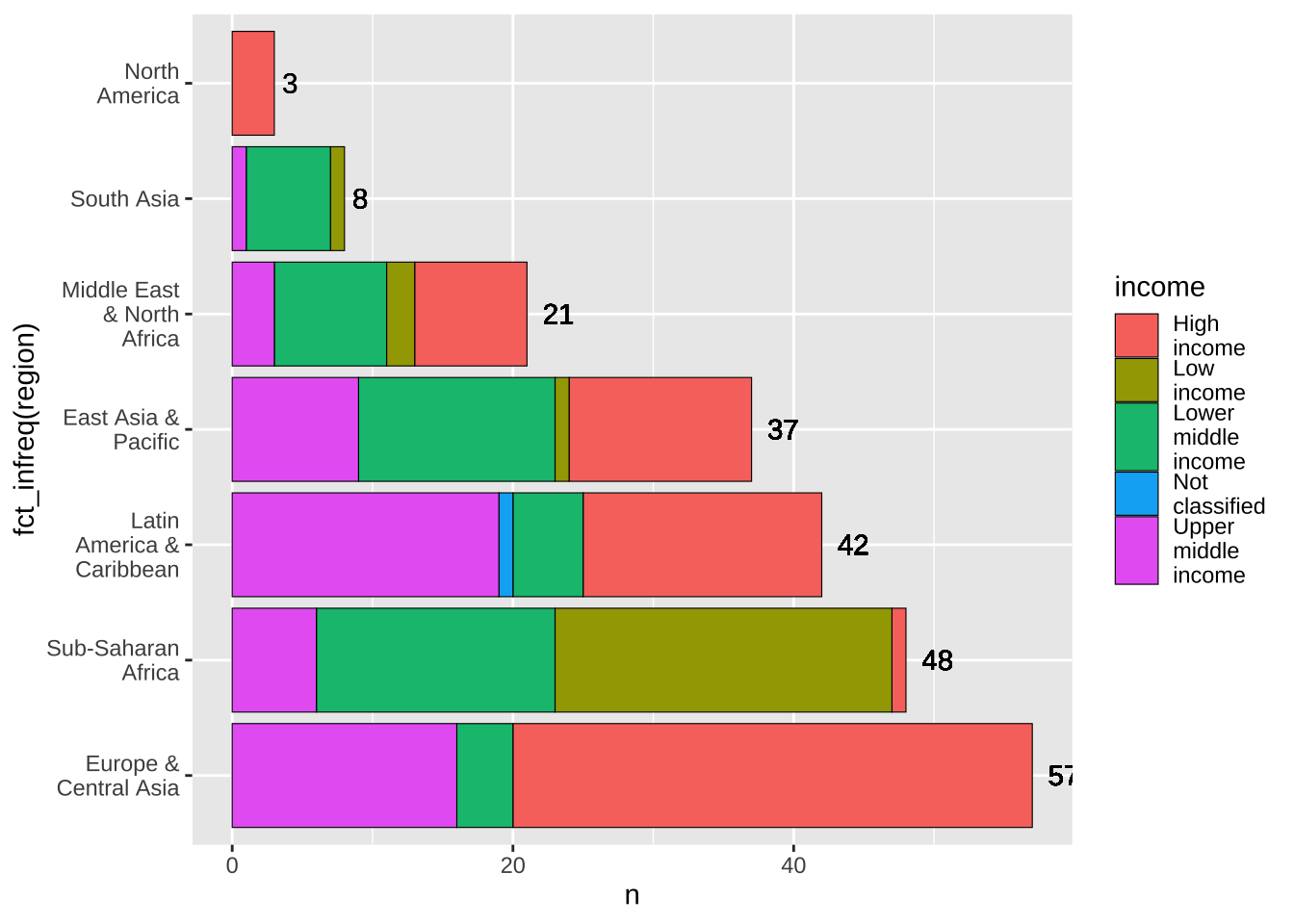
逆順に変える時は fct_rev() を被せれば解決します。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region) |> mutate(n = n()) |>
ggplot(aes(x = fct_rev(fct_infreq(region)), fill = income)) +
geom_bar(color = "black", linewidth = 0.2) +
geom_text(aes(y = n, label = n), hjust = -0.5) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 12)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8))+
coord_flip()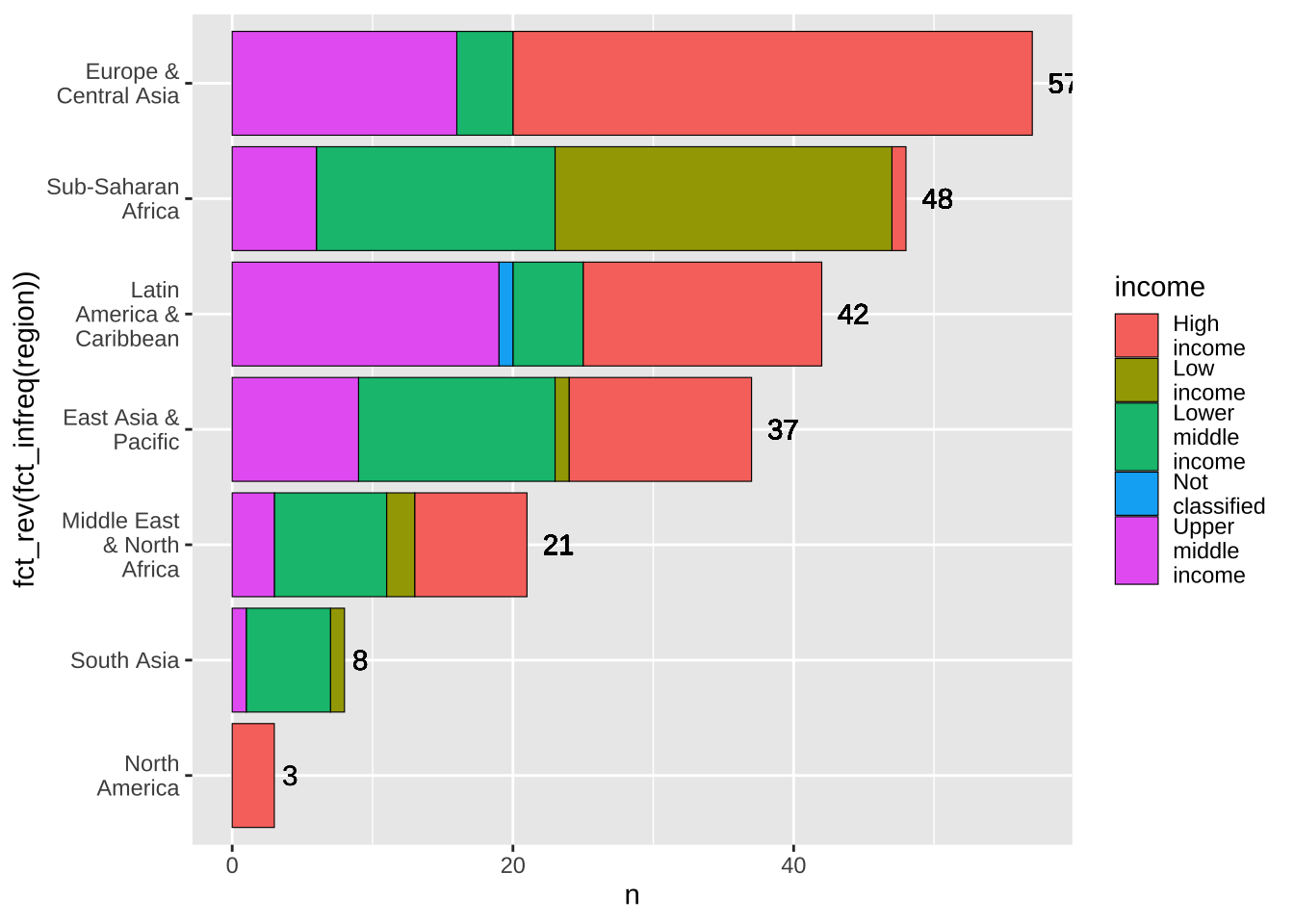
19.5.3.8 割合の表示
積み上げ型になっています。これを、割合で表示するには position = "fill" を加えます。すると、各地域ごとの、income level(収入の多寡)による国の数の割合がわかります。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) +
geom_bar(color = "black", linewidth = 0.2, position = "fill") +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) +
labs(y = "count (ratio)")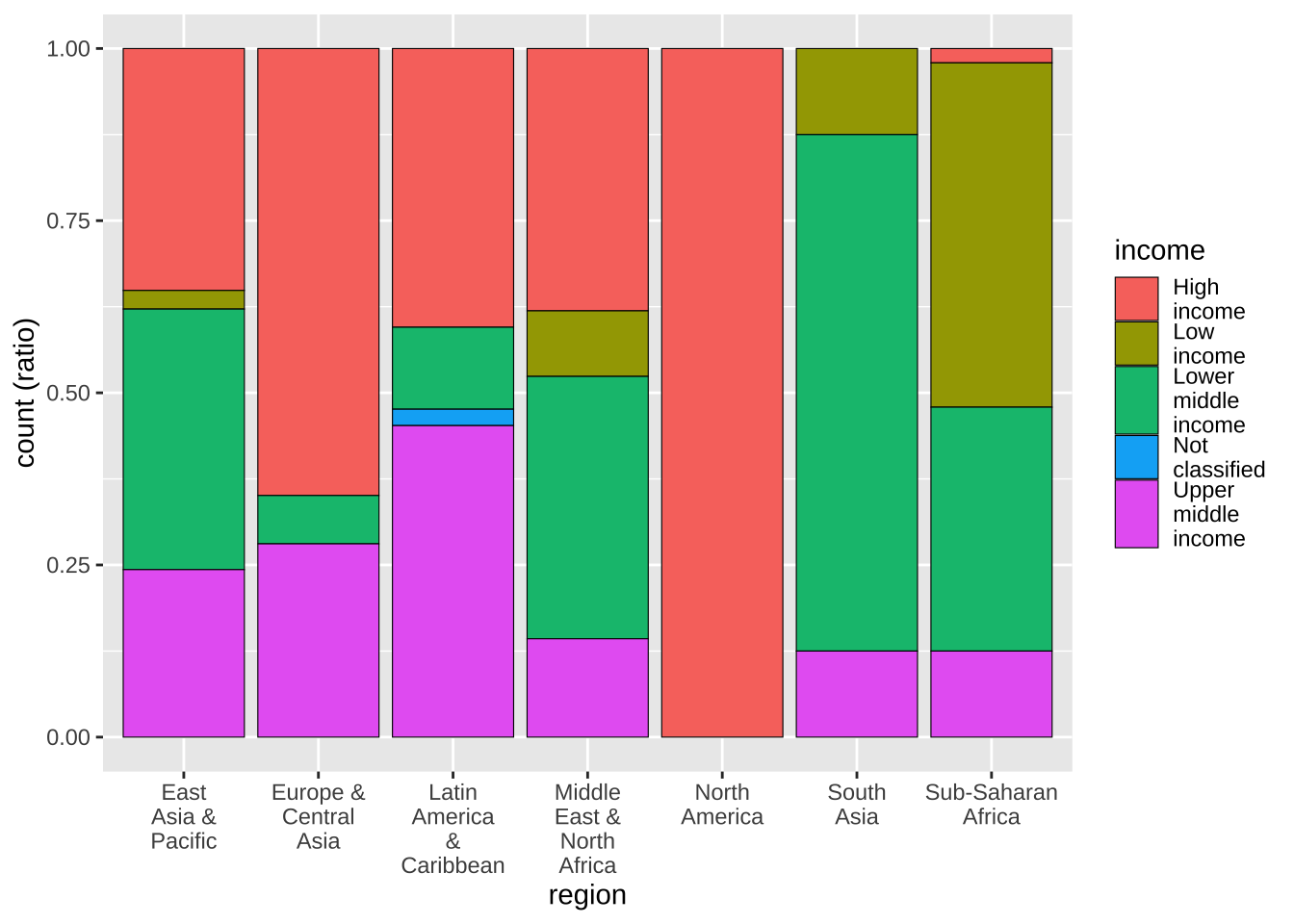
19.5.3.9 縦軸を百分率に
今度は、それを、百分率(percent)表示にしてみましょう。
labels = scales::percent_format(accuracy = 1)
まず、scales は、Tidyverse パッケージの一部ですが、読み込まれてはいないので、加えてあります。library(scales) としてあれば、省略可能です。accuracy = 1 は小数点以下を省略するもので、小数点以下一位までであれば、accuracy = 0.1 とします。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) +
geom_bar(color = "black", linewidth = 0.2, position = "fill") +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_y_continuous(labels = scales::label_percent(accuracy = 1)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) +
labs(y = "count (percent)")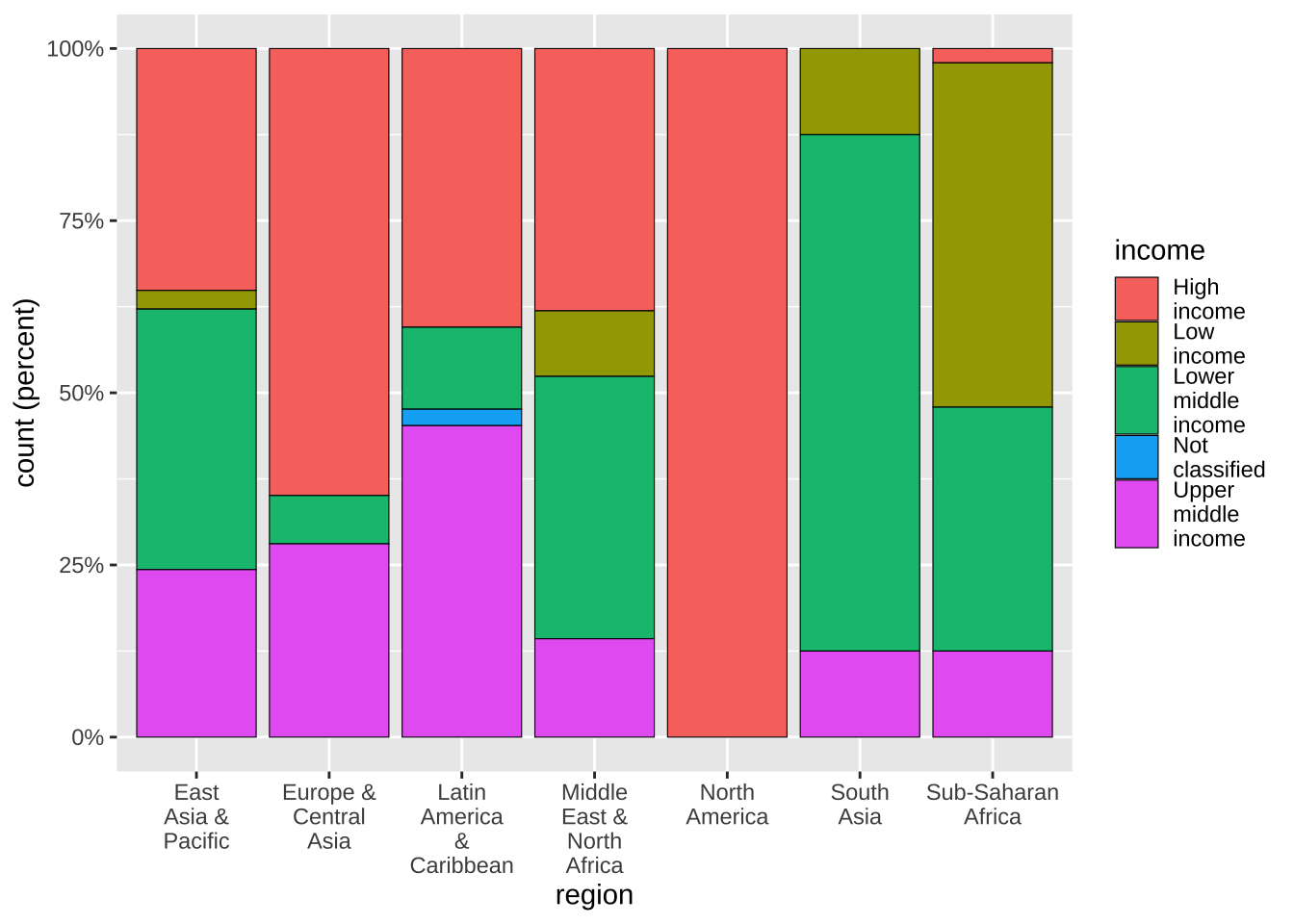
積み上げてありますが、並べることも可能です。ちょっと数が多いのでみにくいですが。
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
ggplot(aes(x = region, fill = income)) +
geom_bar(color = "black", linewidth = 0.2, position = "dodge") +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8)) 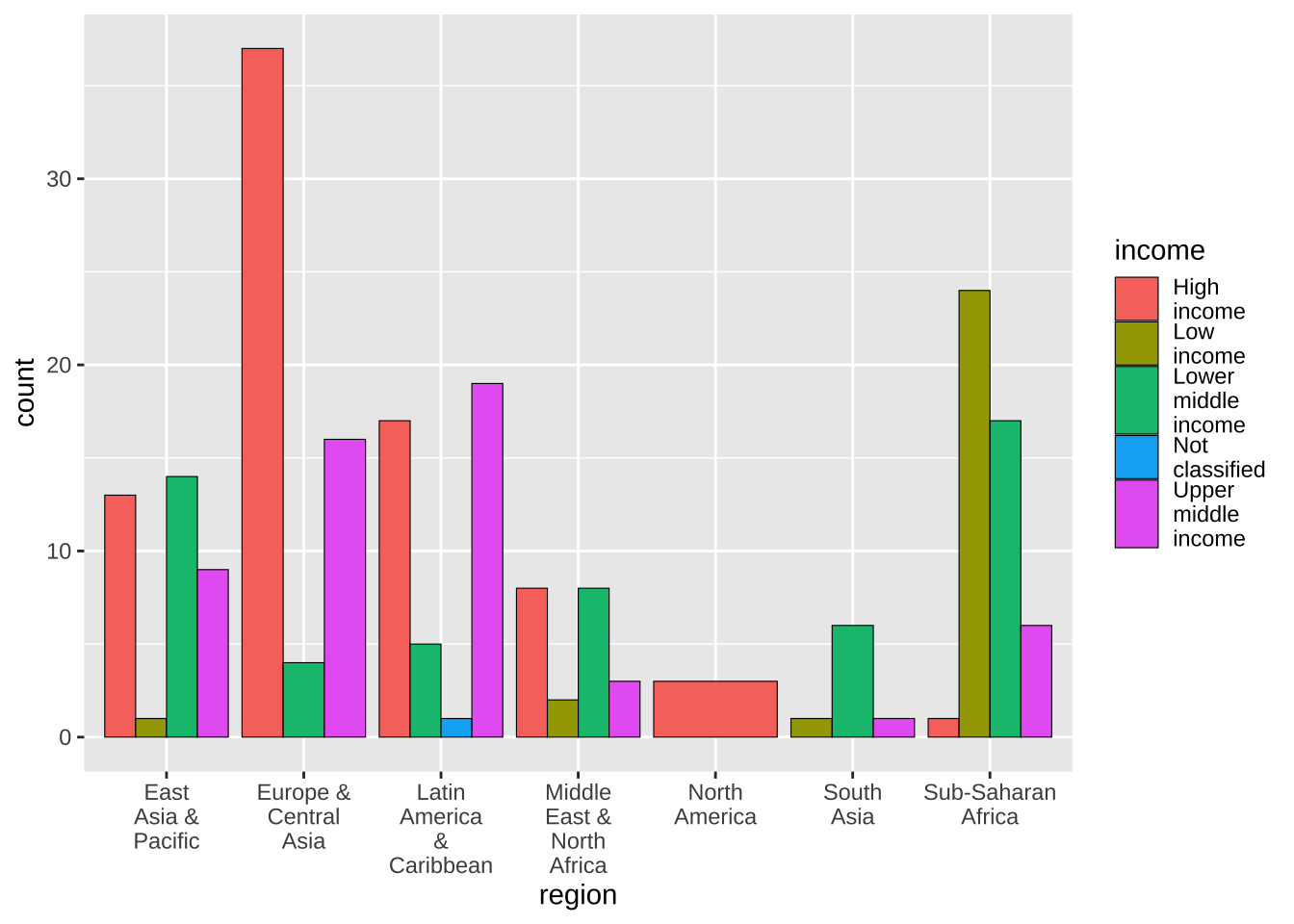
19.5.3.10 数を表示
それぞれの上に、数を加え、region ごとの国数の大きい順に並べ替えてみました。ここでは、position = position_dodge(width=0.9) を使っています。参照リンク
df_wdi_extra |> filter(income != "Aggregates", year == 2020) |>
group_by(region, income) |> mutate(n = n()) |>
ggplot(aes(x = fct_infreq(region), fill = income)) +
geom_bar(color = "black", linewidth = 0.2, position = "dodge") +
geom_text(aes(y = n, label = n), position = position_dodge(width=0.9), vjust = -0.5) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 8)) +
scale_fill_discrete(labels = function(x) str_wrap(x, width = 8))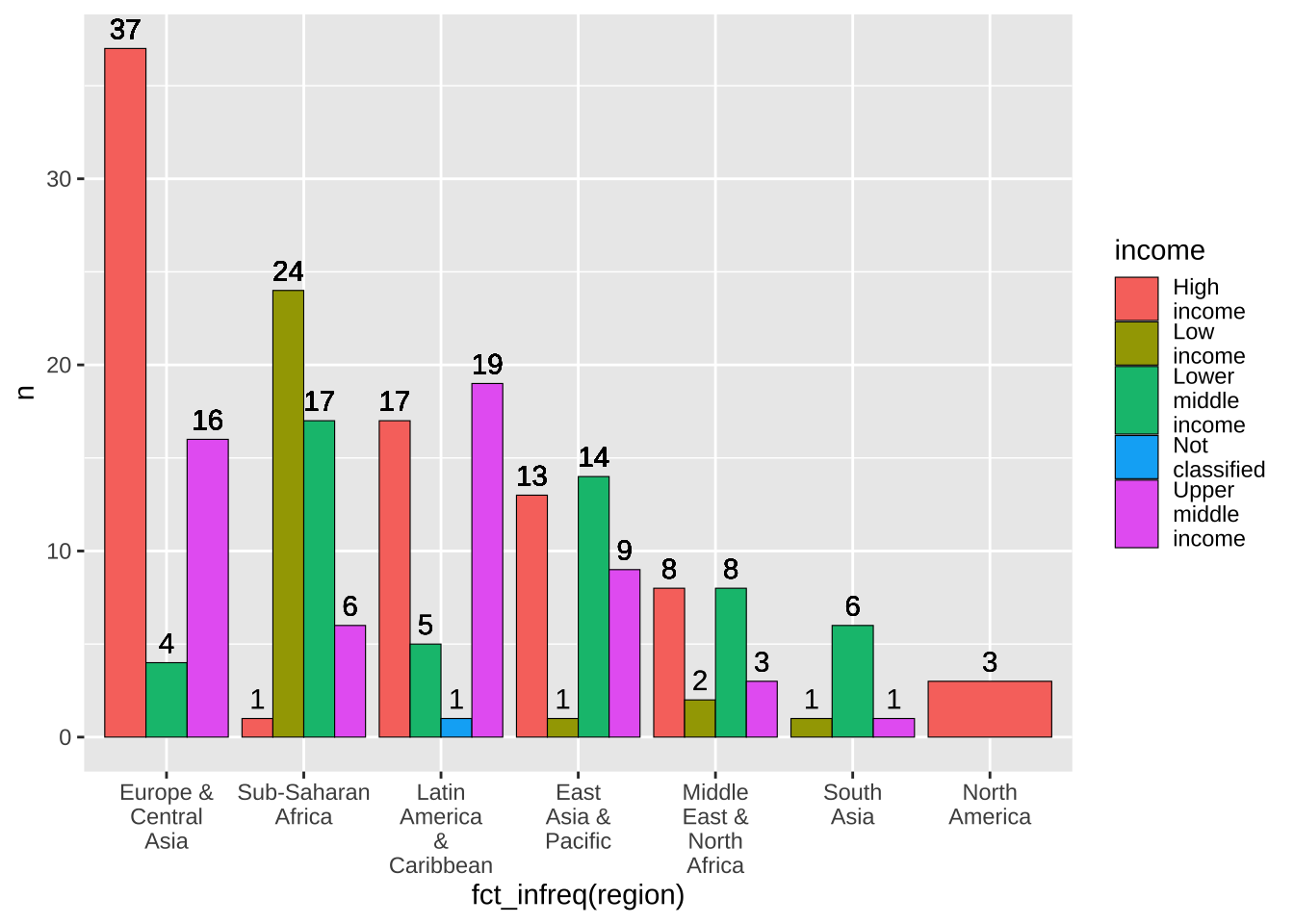
19.5.4 折線グラフと箱ひげ図(line graphs and boxplots)
WDI は時系列データですから、折れ線グラフも使います。後ほど紹介しますが、
<DATA> |> ggplot(aes(year, lifeExp)) + geom_line()と言った感じです。
まずは、失敗例から。次のコードでグラフが描けるでしょうか。
df_wdi |> ggplot(aes(year, lifeExp)) + geom_line()
#> Warning: Removed 266 rows containing missing values
#> (`geom_line()`).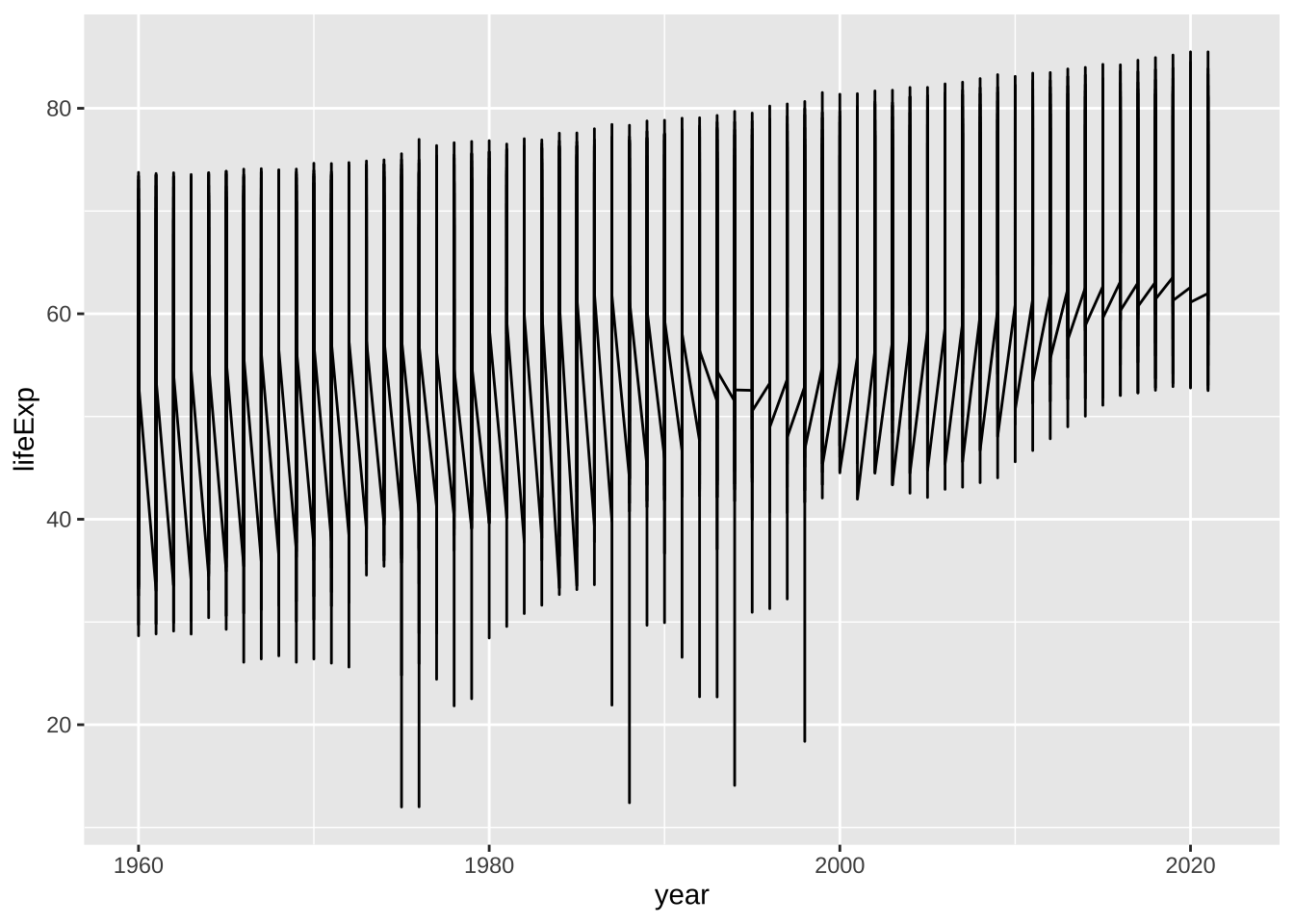
何が起こっているかわかりますか。これは、鋸の刃グラフ(saw-tooth chart)と言われる標準的な失敗例です。
ggplot(df_wdi, aes(x = year, y = lifeExp)) + geom_boxplot()
#> Warning: Continuous x aesthetic
#> ℹ did you forget `aes(group = ...)`?
#> Warning: Removed 892 rows containing non-finite values
#> (`stat_boxplot()`).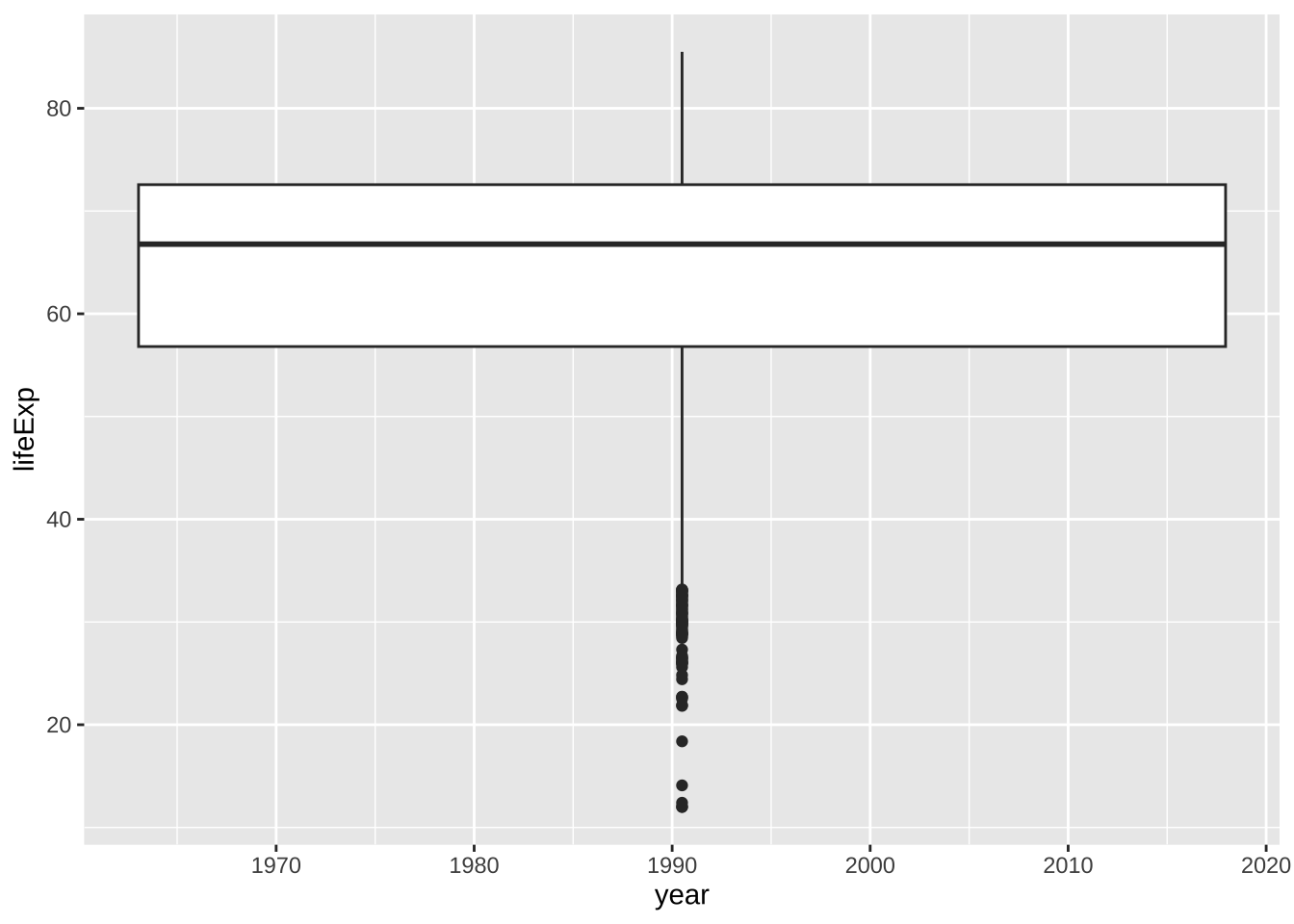
これも期待した箱ひげ図にはなっていません。年は、カテゴリーではなく、数値データですね。
次のようにすると少しマシになります。
ggplot(df_wdi, aes(y = lifeExp, group = year)) + geom_boxplot()
#> Warning: Removed 892 rows containing non-finite values
#> (`stat_boxplot()`).
19.5.4.0.1 Box Plot
ggplot(df_wdi, aes(x = as_factor(year), y = lifeExp)) + geom_boxplot()
#> Warning: Removed 892 rows containing non-finite values
#> (`stat_boxplot()`).
とはいえ、数が多すぎますね。色もつけてみましょう。塗りつぶしは、fill 枠の線に色をつけるのは、color ですから、ここでは、fill を使います。
df_wdi_extra |> filter(income != "Aggregates") |>
filter(year %in% c(1960, 1980, 2000, 2020)) |>
ggplot(aes(x=as_factor(year), y = lifeExp, fill = income)) +
geom_boxplot()
#> Warning: Removed 37 rows containing non-finite values
#> (`stat_boxplot()`).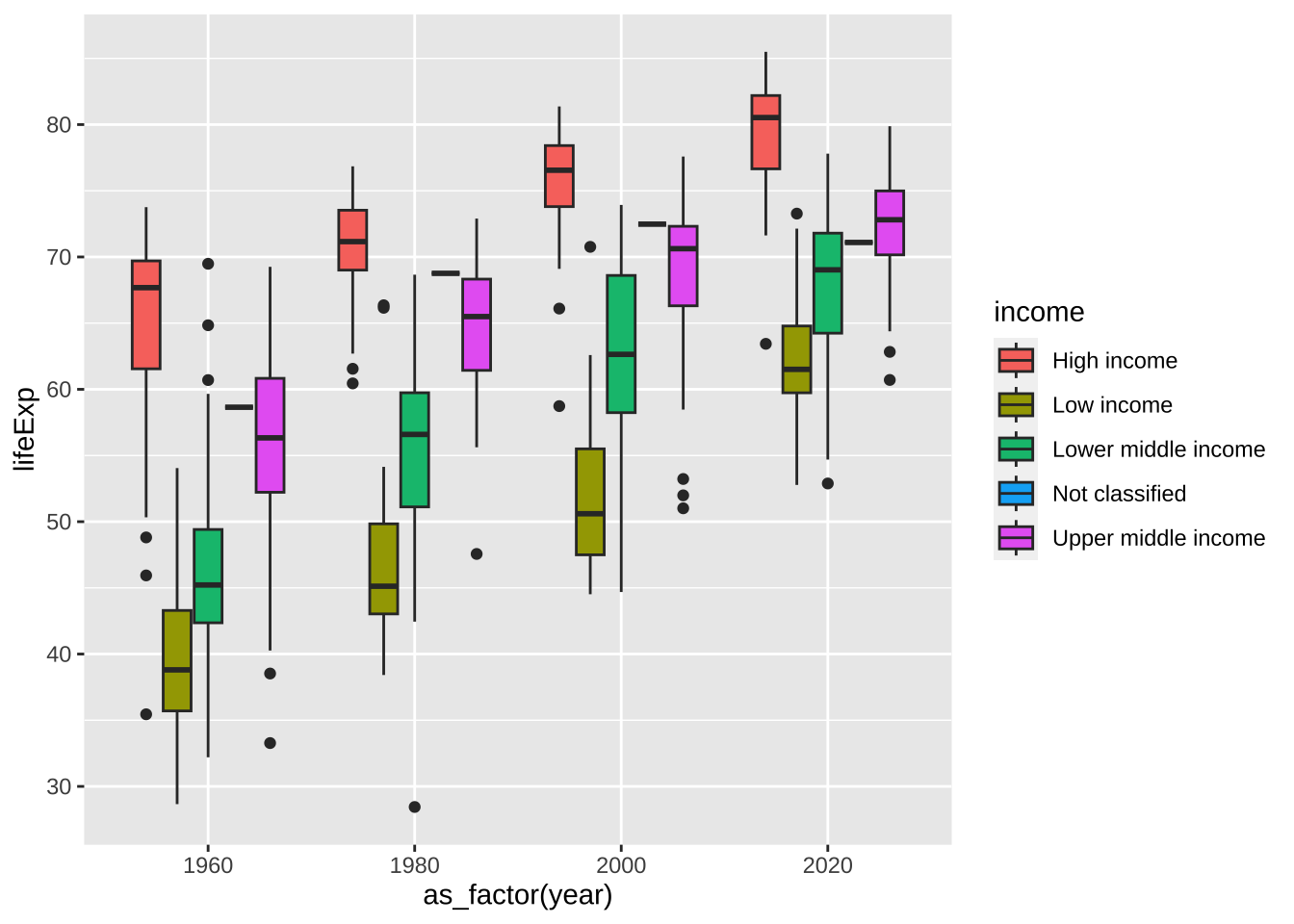
折線グラフの例としては次のようなものがあります。
df_lifeExp <- df_wdi_extra |> filter(region != "Aggregates") |>
group_by(region, year) |>
summarize(mean_lifeExp = mean(lifeExp), median_lifeExp = median(lifeExp), max_lifeExp = max(lifeExp), min_lifeExp = min(lifeExp), .groups = "keep")
df_lifeExp %>% ggplot(aes(x = year, y = mean_lifeExp, color = region)) +
geom_line()
#> Warning: Removed 243 rows containing missing values
#> (`geom_line()`).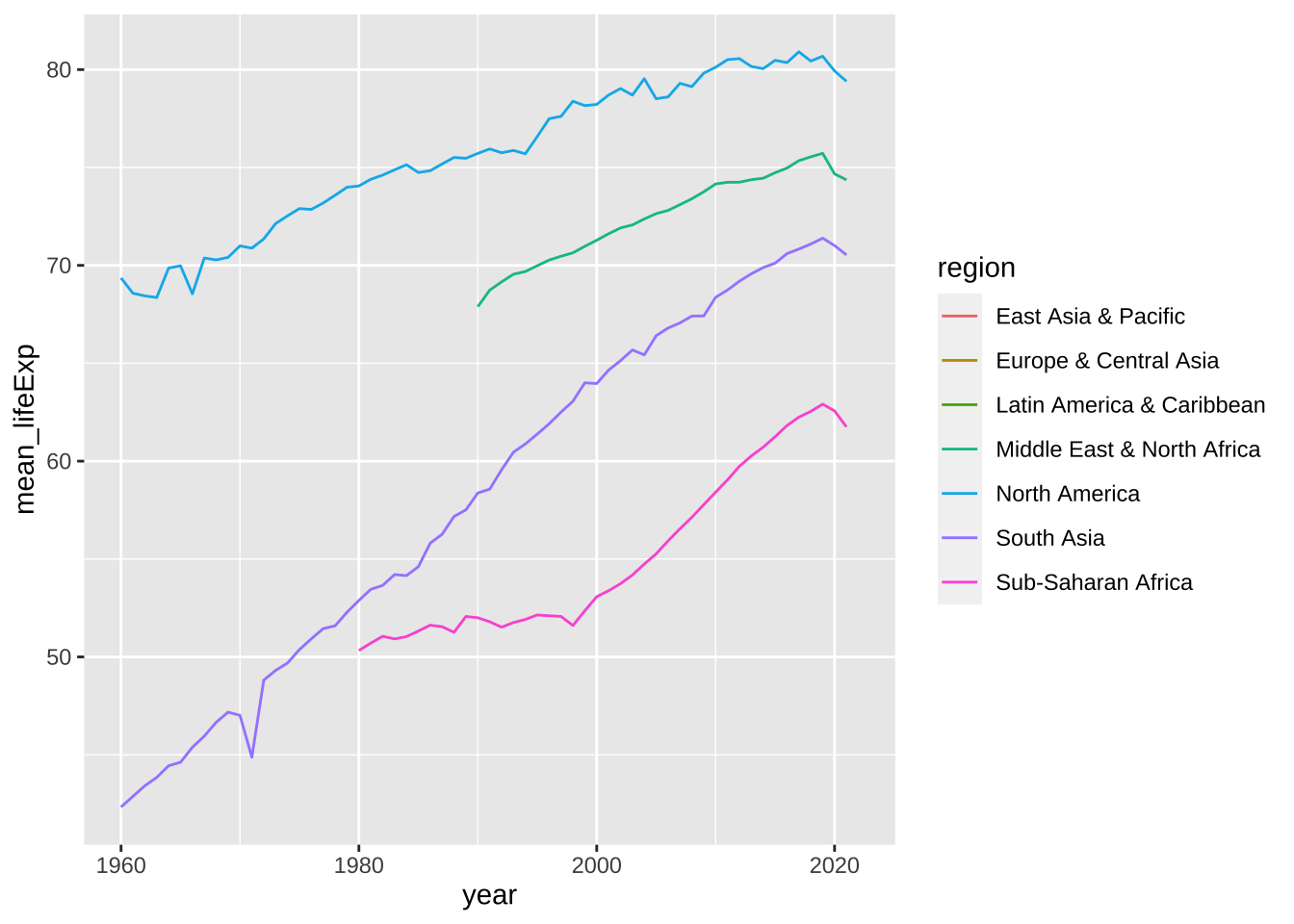
df_lifeExp %>% ggplot(aes(x = year, y = mean_lifeExp, color = region, linetype = region)) +
geom_line()
#> Warning: Removed 243 rows containing missing values
#> (`geom_line()`).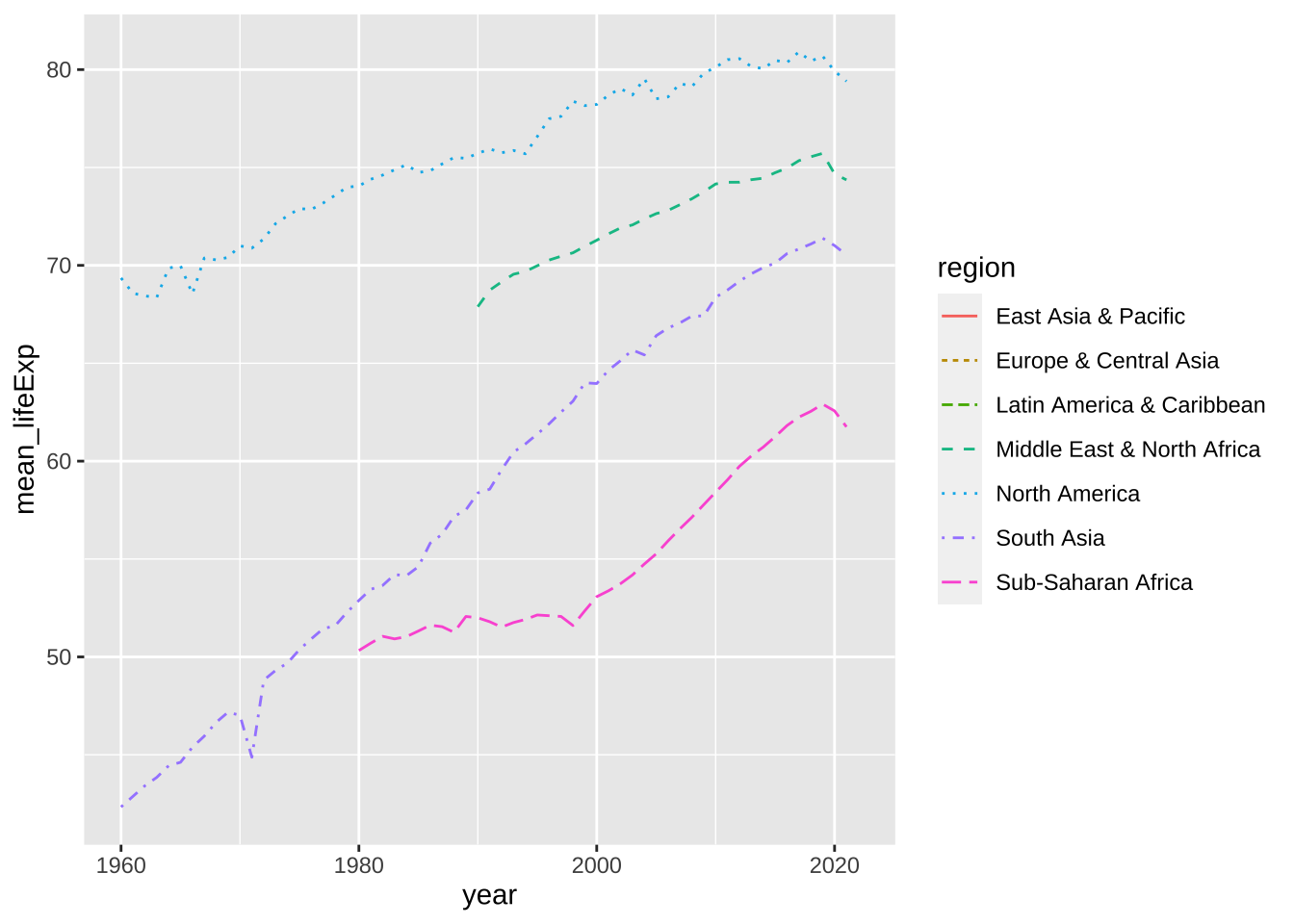
df_lifeExp %>% ggplot() +
geom_line(aes(x = year, y = mean_lifeExp, color = region)) +
geom_line(aes(x = year, y = median_lifeExp, linetype = region))
#> Warning: Removed 243 rows containing missing values (`geom_line()`).
#> Removed 243 rows containing missing values (`geom_line()`).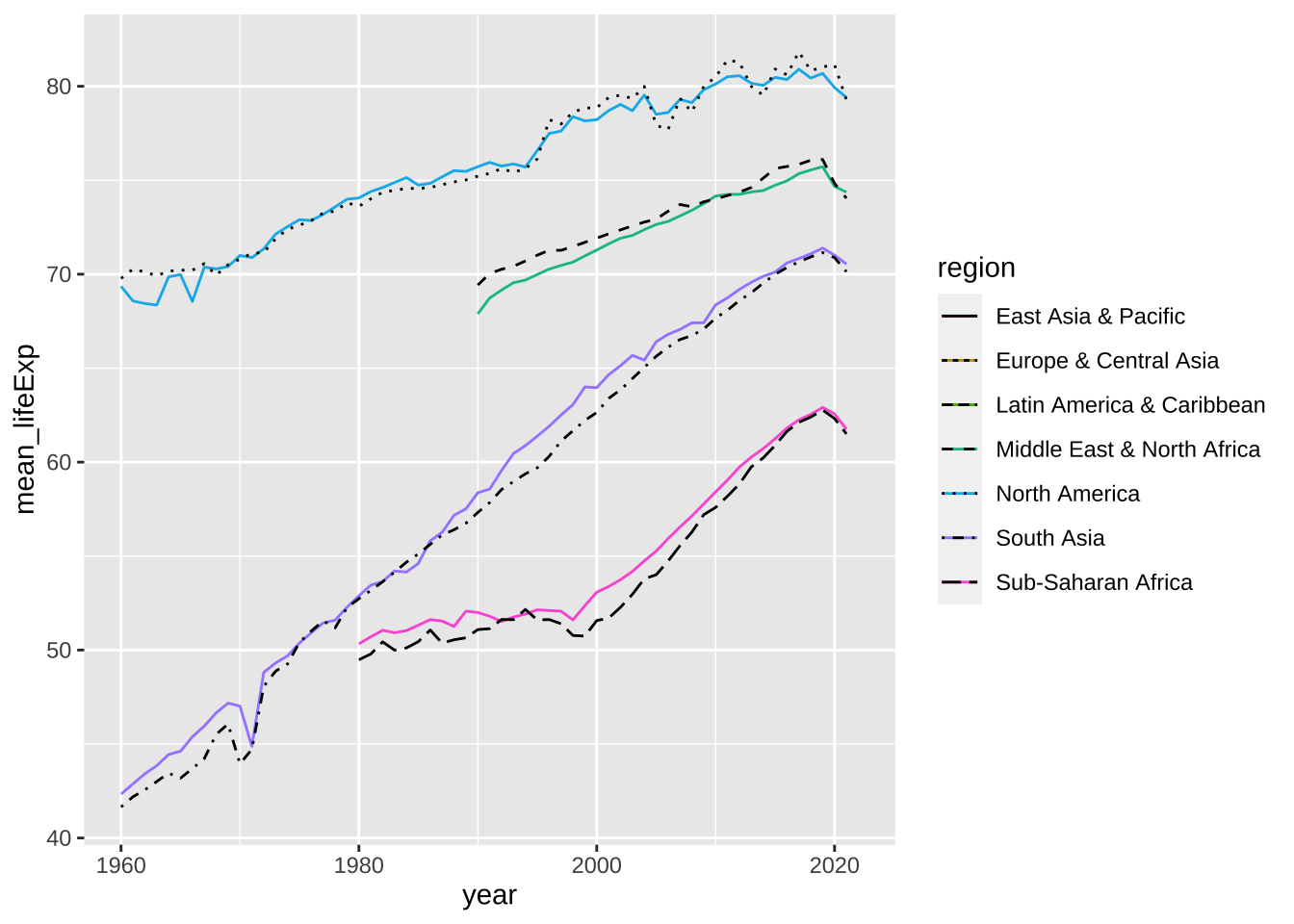
19.5.5 人口と一人当たりの国内総生産
まず、出生時の平均寿命を見てみましたが、他の指標についてみてみましょう。他には、人口(population)と、一人当たりの 国内総生産(GDP per Capita)の指標がそれぞれ、pop と、gdpPercap という変数名で含まれています。
まずは、簡単に、地域ごとの経年変化を見てみましょう。平均を計算してという方法もありますが、集計したものもデータの中にあるので、上で作った、region 名も使って、それで、グラフを書いてみましょう。
df_wdi_extra |> filter(region == "Aggregates") |>
filter(country %in% regions) |> drop_na(pop) |>
ggplot(aes(year, pop, color = country)) + geom_line() +
labs(title = "Populations of Regions", color = "region")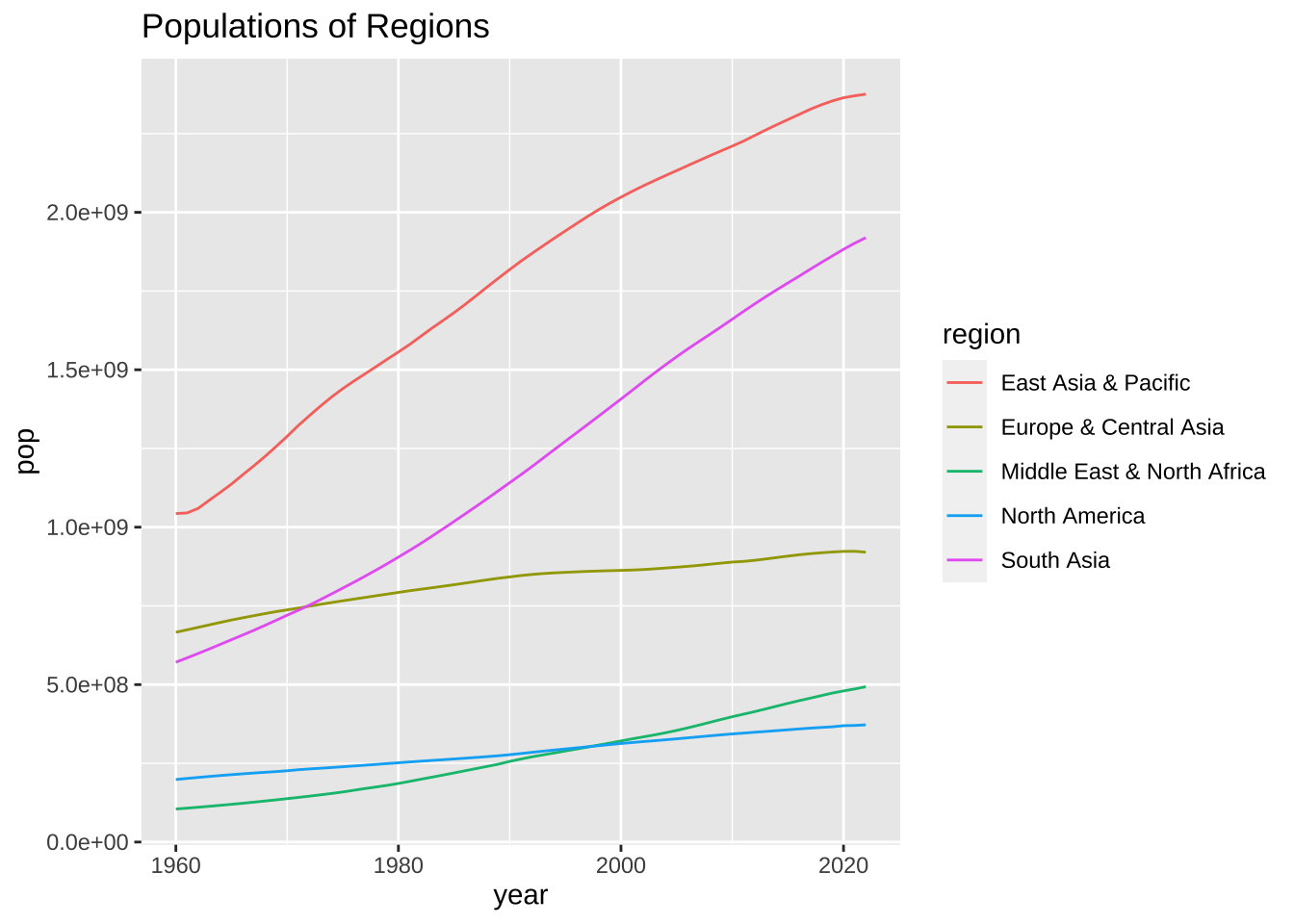
df_wdi_extra |> filter(region == "Aggregates") |>
filter(country %in% regions) |> drop_na(gdpPercap) |>
ggplot(aes(year, gdpPercap, color = country)) + geom_line() +
labs(title = "GDP per Capita of Regions", color = "region")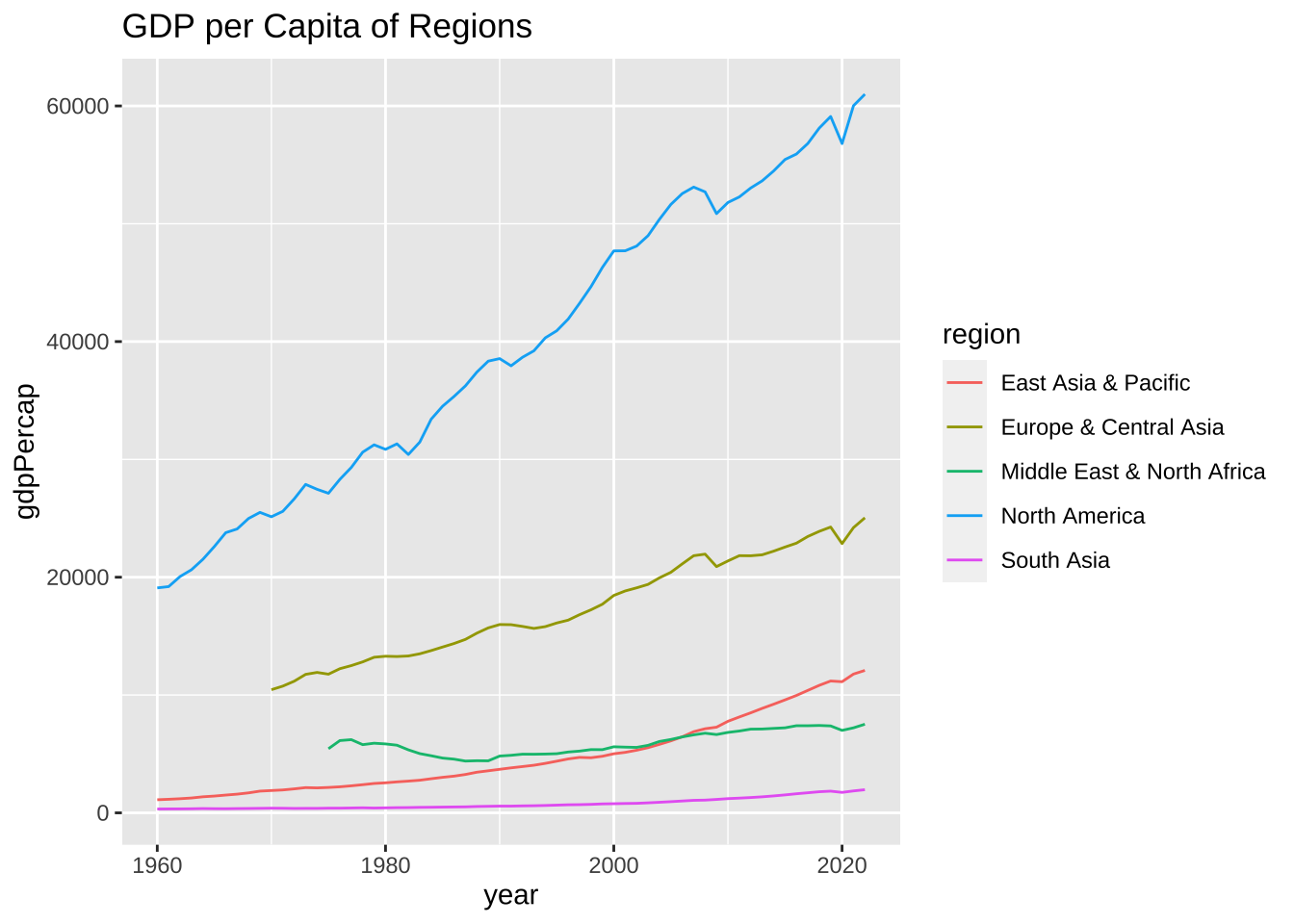
大体、期待したものが描けたかと思います。では、箱ひげ図はどうでしょうか。何年かを切り取り、年毎の地域ごとの分布を見てみましょう。古いものは地域によってはデータがなさそうですから、1980年と、2020年にしましょう。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(factor(year), pop, fill = region)) + geom_boxplot() +
labs(title = "Population Distributions by Regions", x = "year", fill = "region")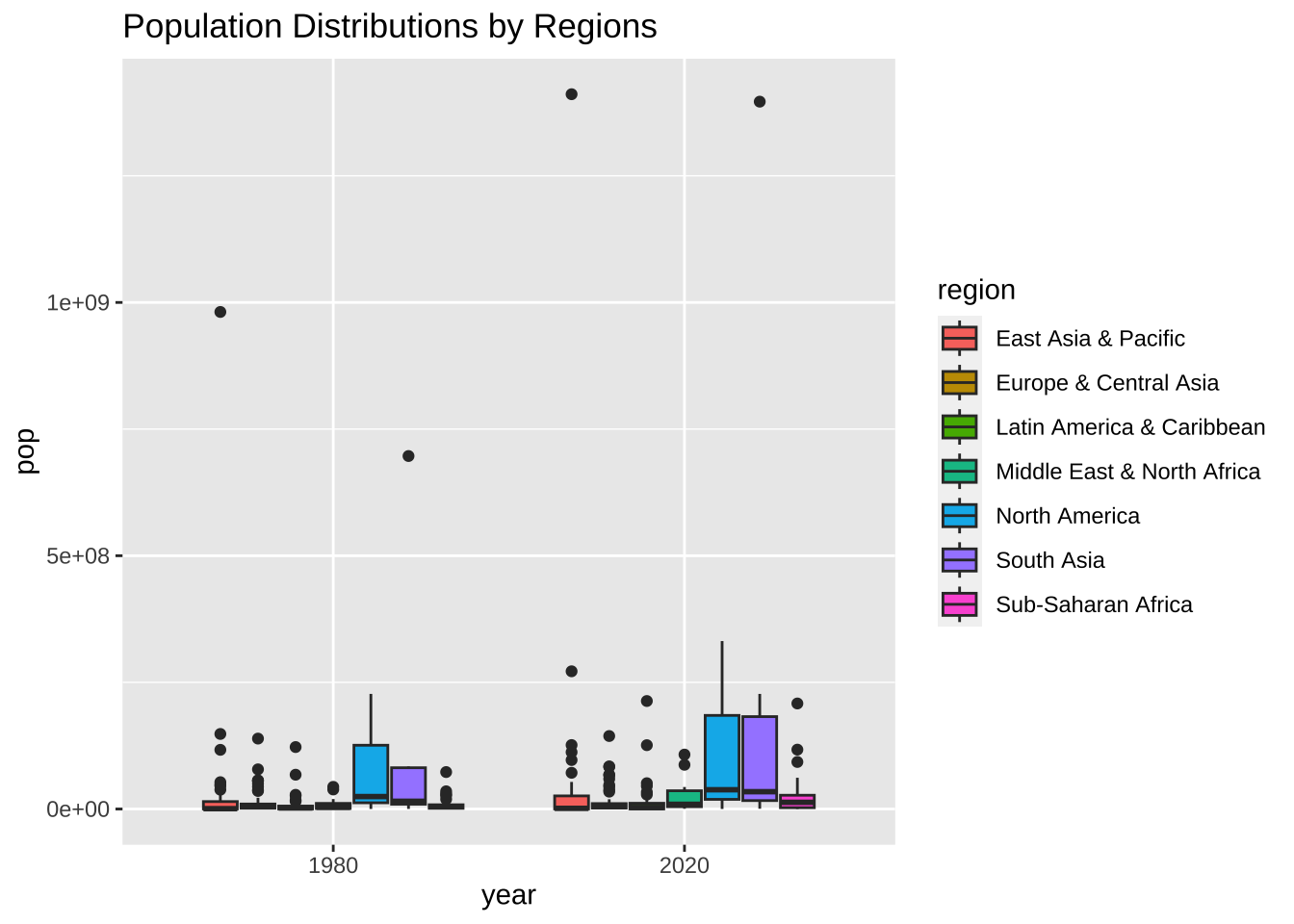
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(gdpPercap) |>
ggplot(aes(factor(year), gdpPercap, fill = region)) + geom_boxplot() +
labs(title = "GDP per Capita Distribution by Regions", x = "year", fill = "region")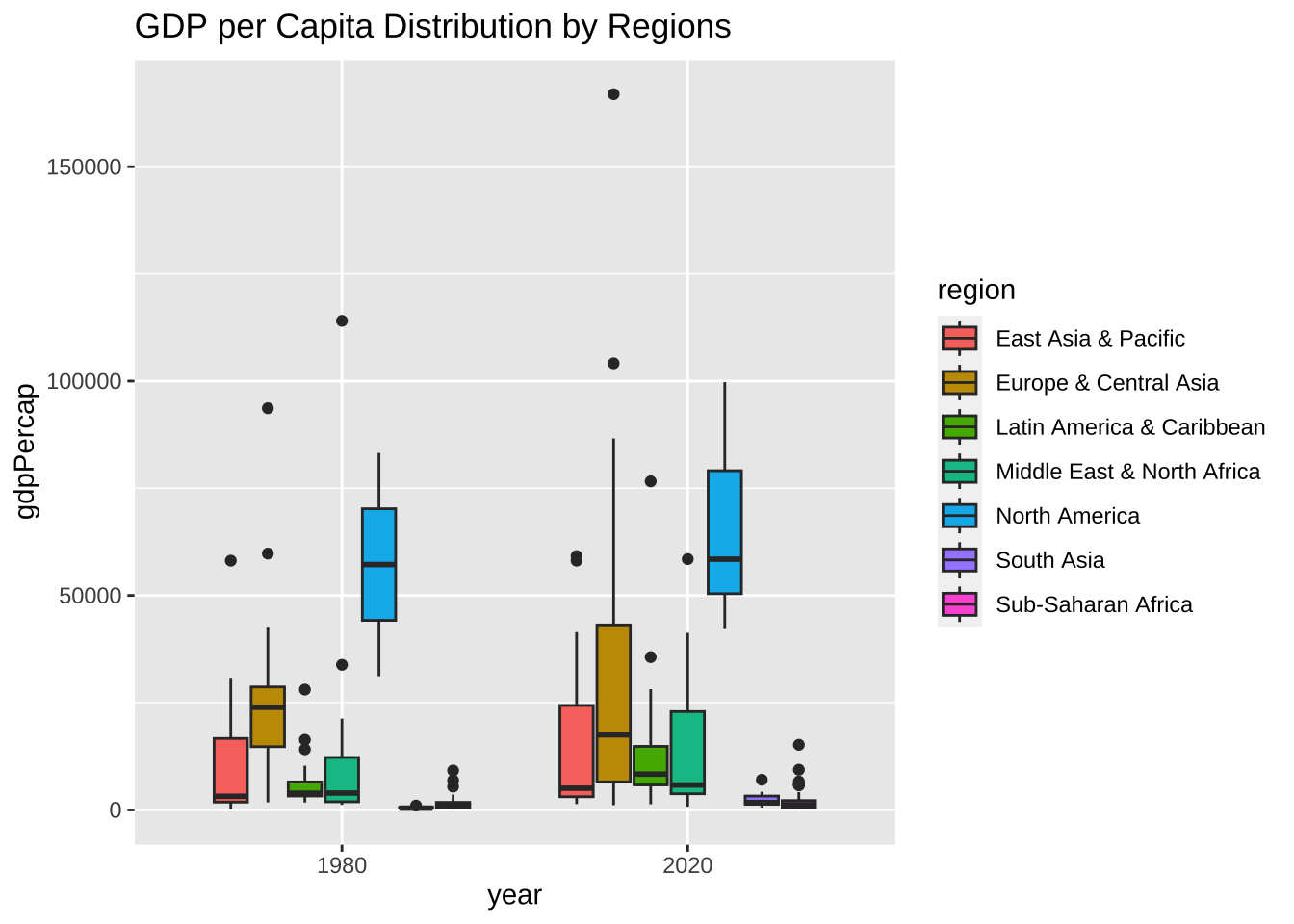
一応、期待したものが表示されたようですが、どうも、下の方が固まっていて、見にくいですね。特に人口のほうは、問題がありそうです。Y 軸でみると、指数表示になっています。小さな国から、人口の多い国までありますから、かなり、幅があるのでしょうね。
両方とも、log10 で表示してみましょう。変形 dplyr のところで使いました。1,000 だと 3、10,000 だと4、100,000 だと 5、1,000,000 だと 6、10,000,000 だと 7、100,000,000 だと 8 と、零の数が表示されるのでした。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(factor(year), pop, fill = region)) + geom_boxplot() +
scale_y_log10() +
labs(title = "Population Distributions by Regions",
x = "year", y = "pop in log10", fill = "region")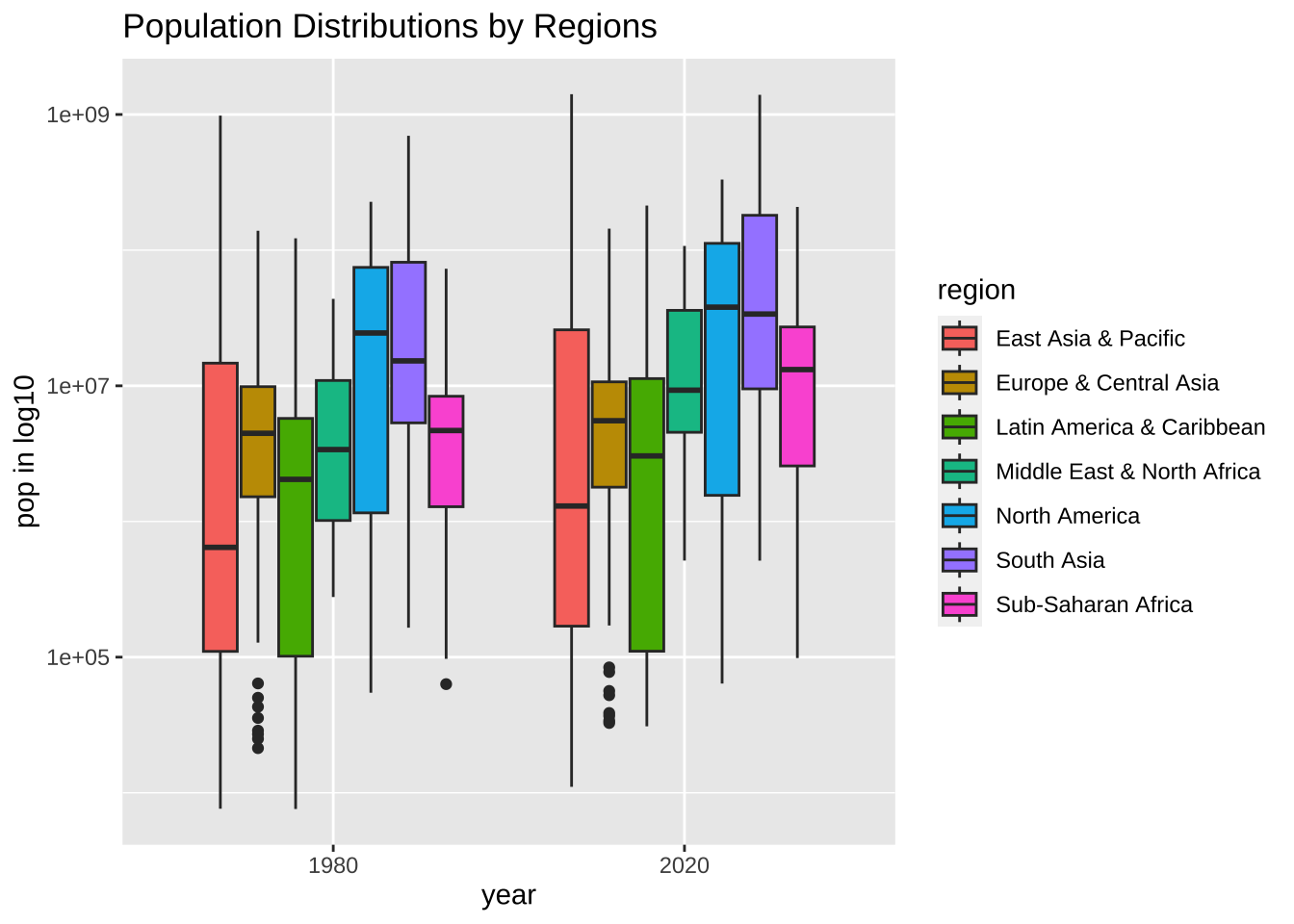
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(gdpPercap) |>
ggplot(aes(factor(year), gdpPercap, fill = region)) + geom_boxplot() +
scale_y_log10() +
labs(title = "GDP per Capita Distributions by Regions",
x = "year", y = "gdpPercap in log10", fill = "region")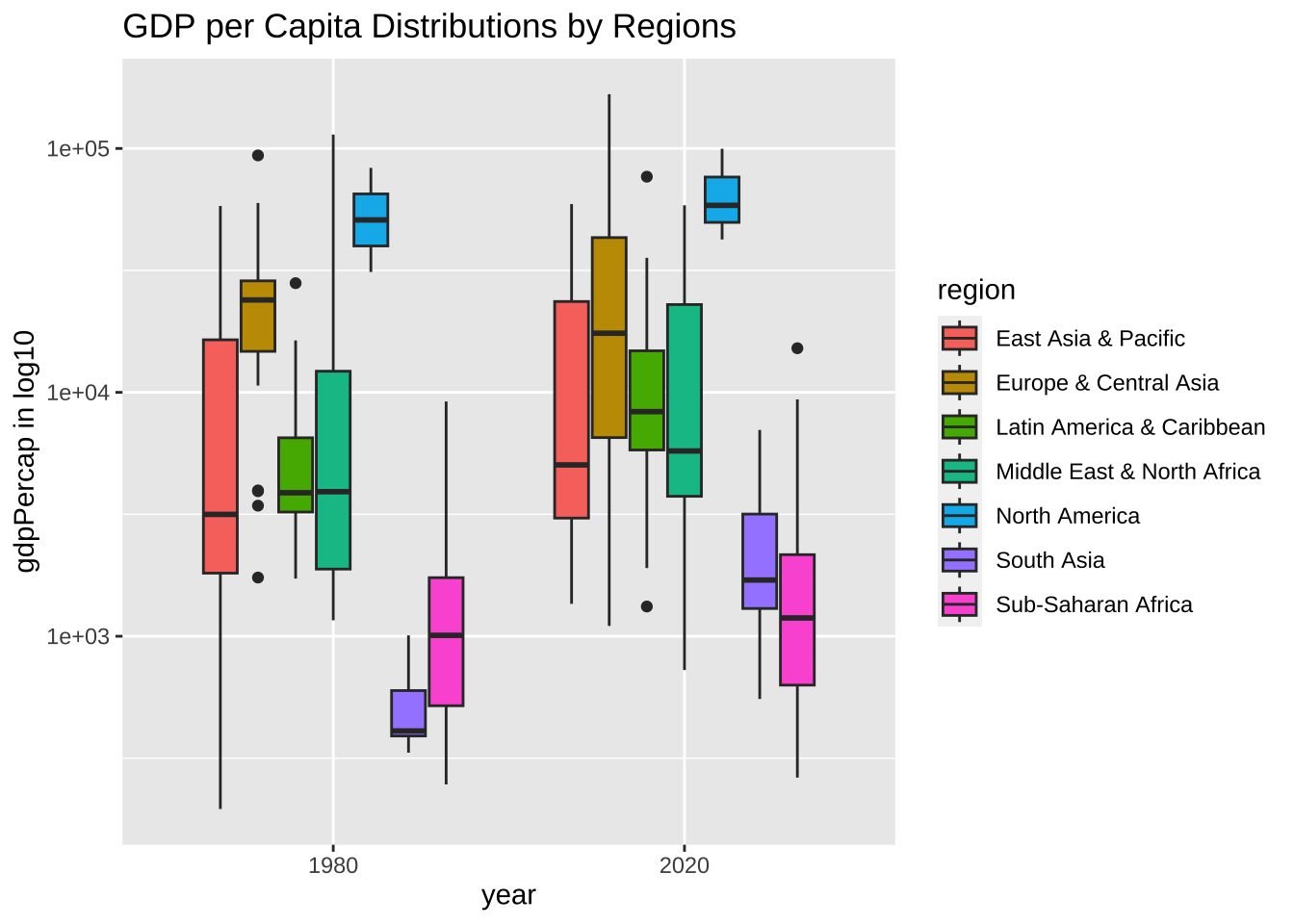
少しみやすいですかね。実は、log10 で表示する仕方はもう一つあります。座標軸を等間隔にしないで、log10 の切り方に変える方法です。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(factor(year), pop, fill = region)) + geom_boxplot() +
coord_trans(y = "log10") +
labs(title = "Population Distributions by Regions",
x = "year", y = "pop in log10", fill = "region")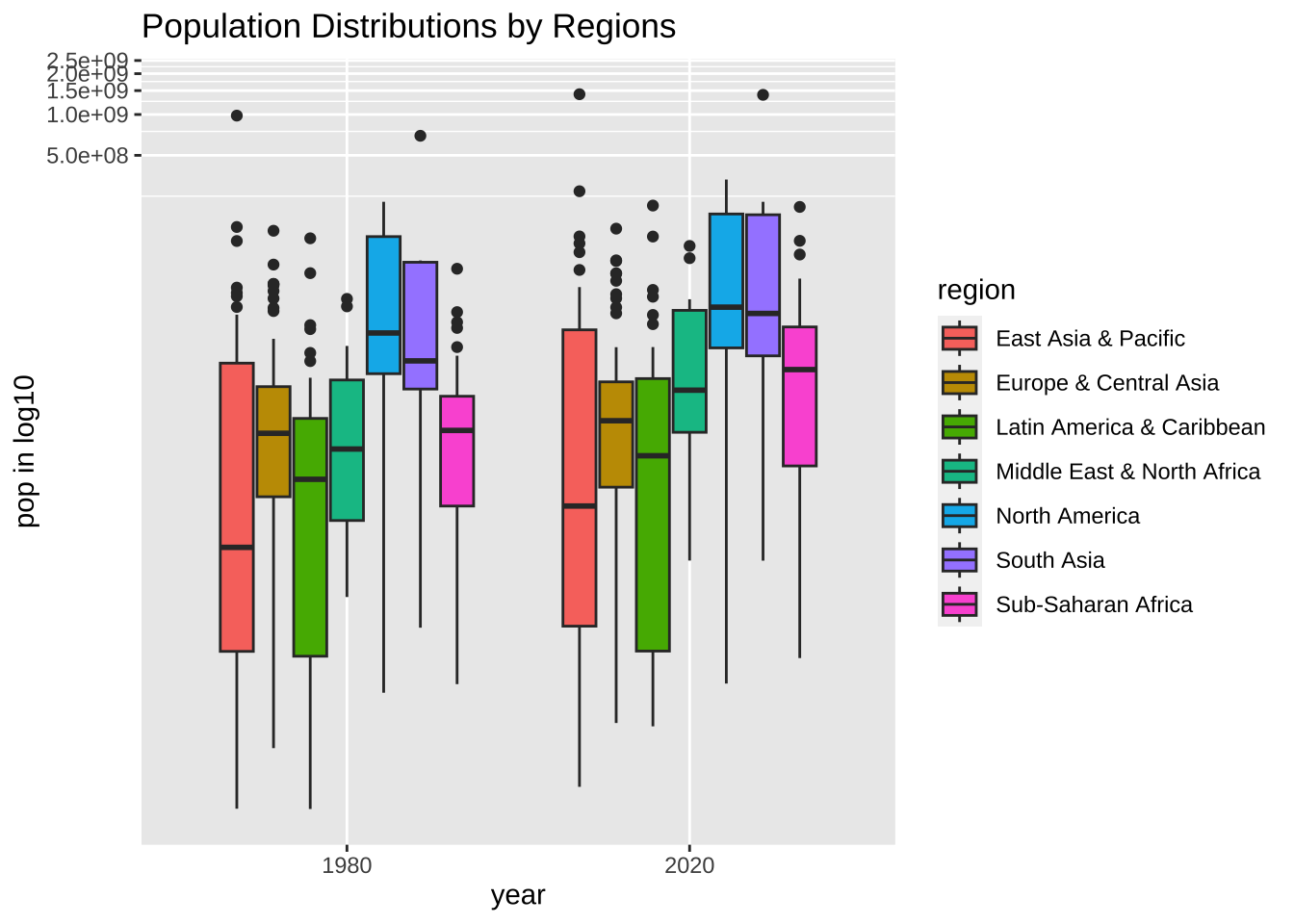
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(factor(year), pop, fill = region)) + geom_boxplot() +
coord_trans(y = "log10") +
labs(title = "Population Distributions by Regions",
x = "year", y = "pop in log10", fill = "region")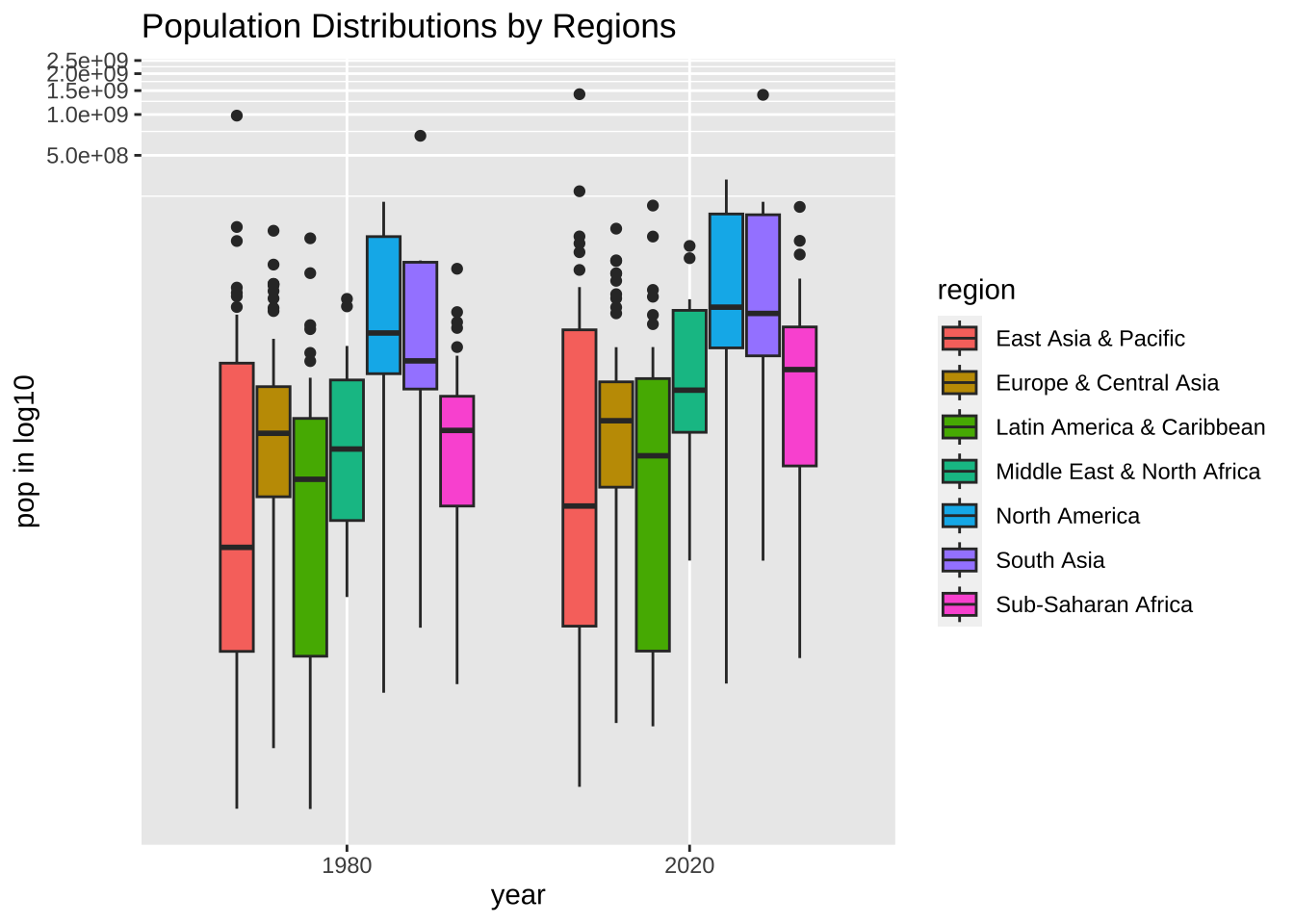
指数表示は避けたいということでしたら、次のようにすることも可能です。日本語にすることも可能です。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(factor(year), pop, fill = region)) + geom_boxplot() +
scale_y_log10(breaks = c(1e5, 1e7, 1e9), labels = c("10^5", "10^7", "10^9")) +
labs(title = "Population Distributions by Regions",
x = "year", y = "pop", fill = "region")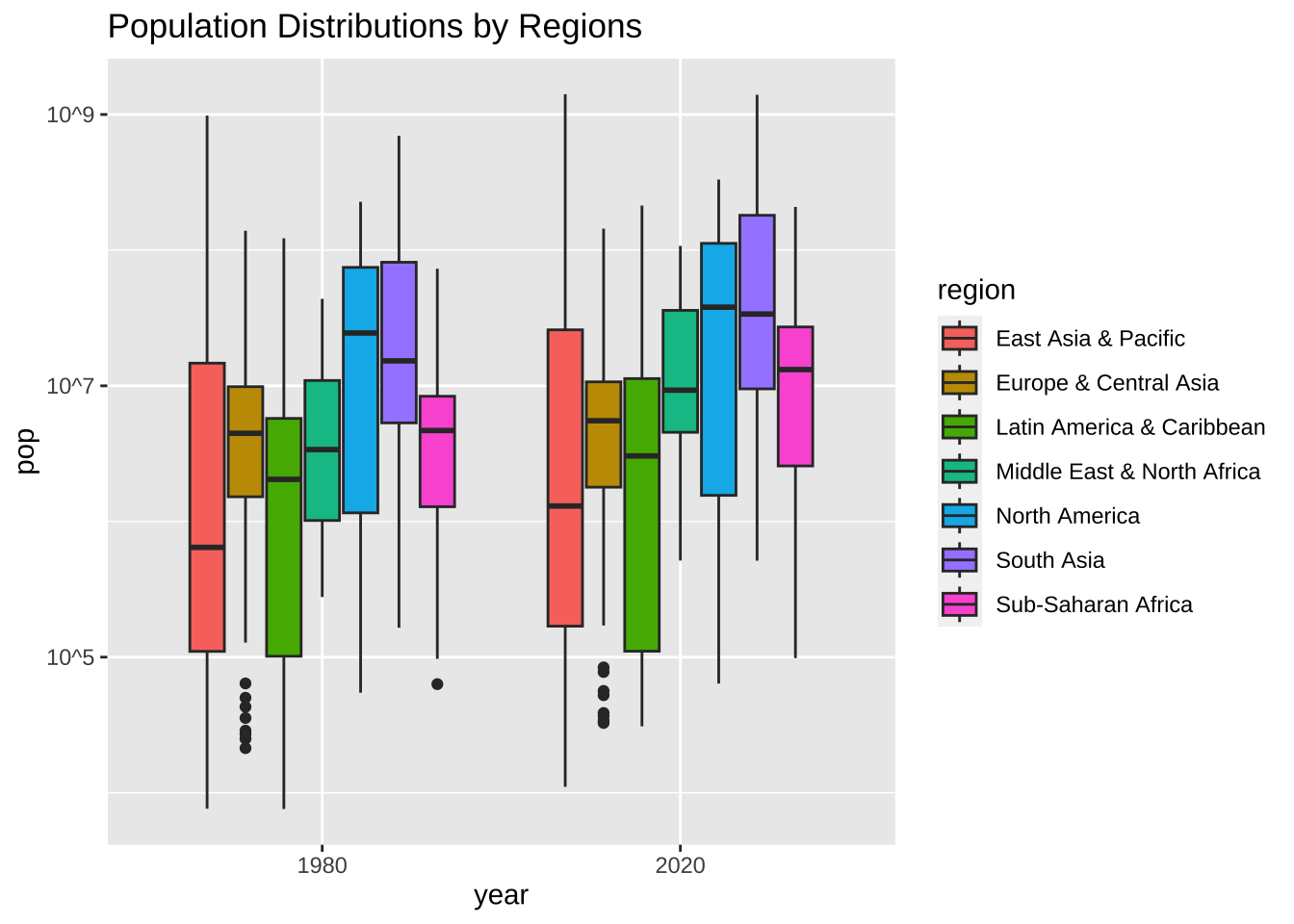
まずは、地域ごとに変化を見るにはどうしたら良いでしょうか。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(region, pop, fill = factor(year))) + geom_boxplot() +
scale_y_log10(breaks = c(1e5, 1e7, 1e9), labels = c("10^5", "10^7", "10^9")) +
labs(title = "Population Distributions by Regions",
x = "region", y = "pop", fill = "year")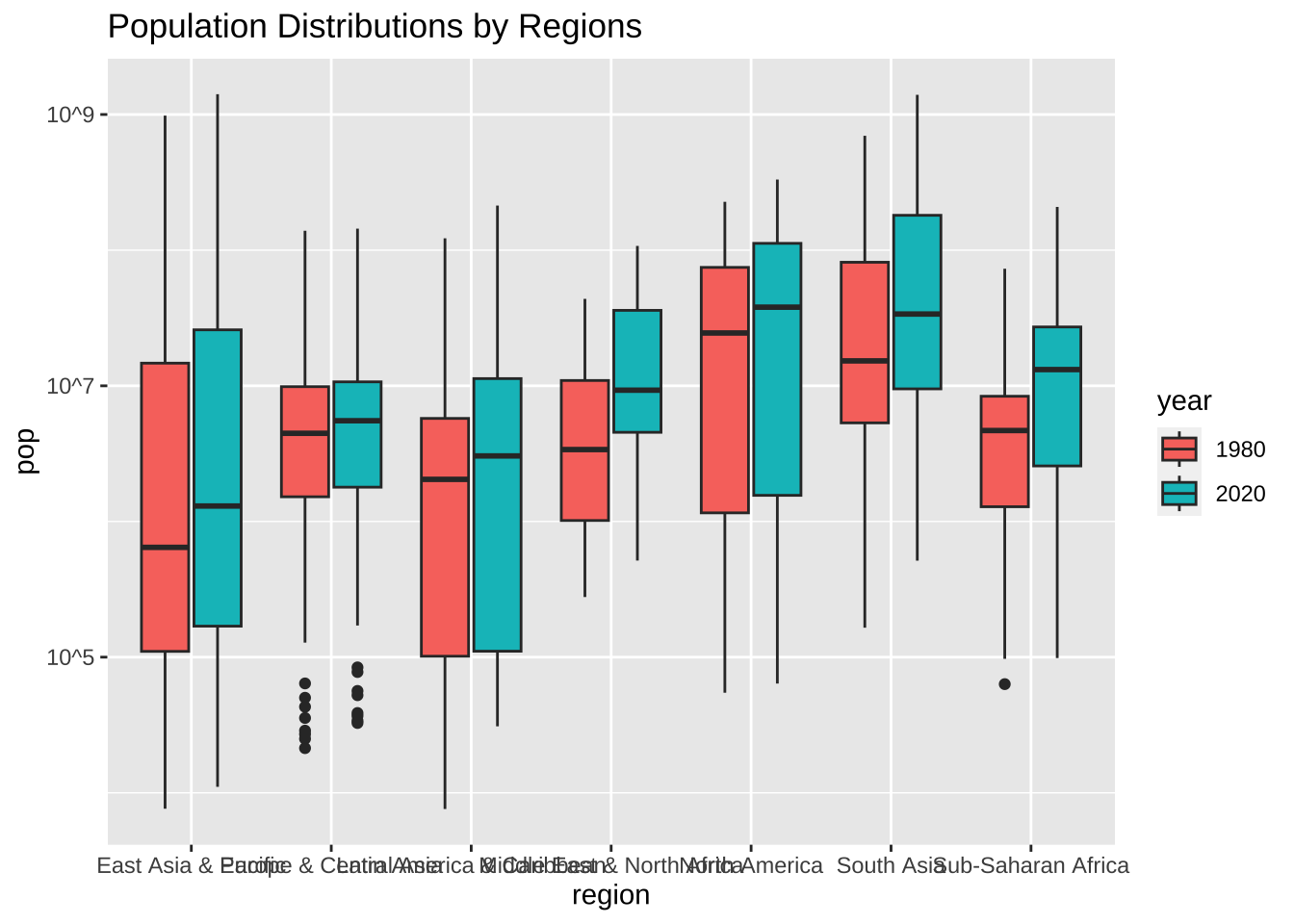
地域名が重なっているところがありますね。
df_wdi_extra |> filter(region != "Aggregates", year %in% c(1980, 2020)) |>
drop_na(pop) |>
ggplot(aes(region, pop, fill = factor(year))) + geom_boxplot() +
scale_x_discrete(labels = function(x) str_wrap(x, width = 20)) +
scale_y_log10(breaks = c(1e5, 1e7, 1e9), labels = c("10^5", "10^7", "10^9")) +
labs(title = "Population Distributions by Regions",
x = "region", y = "pop", fill = "year")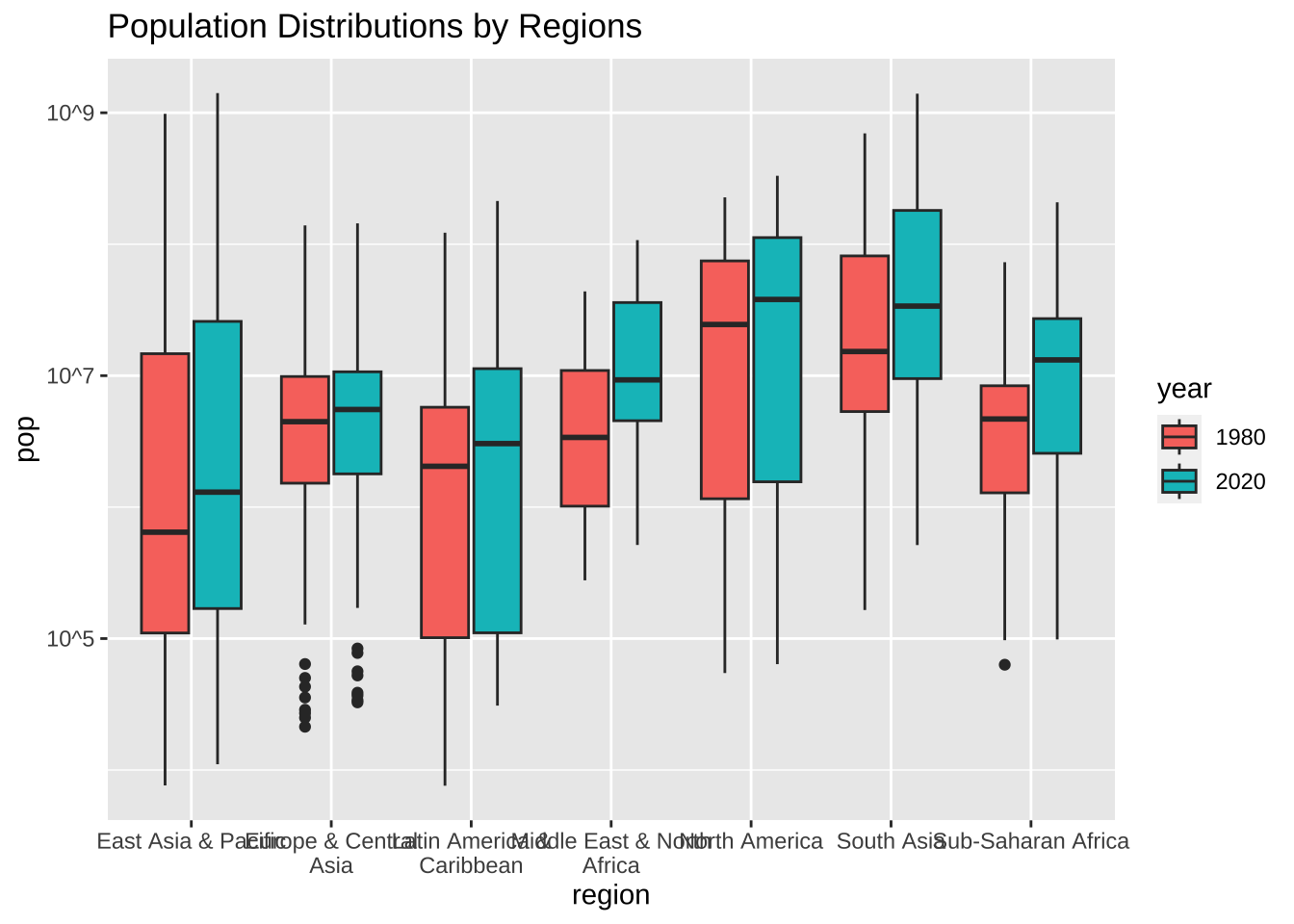
19.5.6 散布図
df_wdi_extra |> filter(year == 2021) |> drop_na(pop, gdpPercap) |>
ggplot(aes(pop, gdpPercap, color = region)) +
geom_point() + scale_x_log10() + scale_y_log10()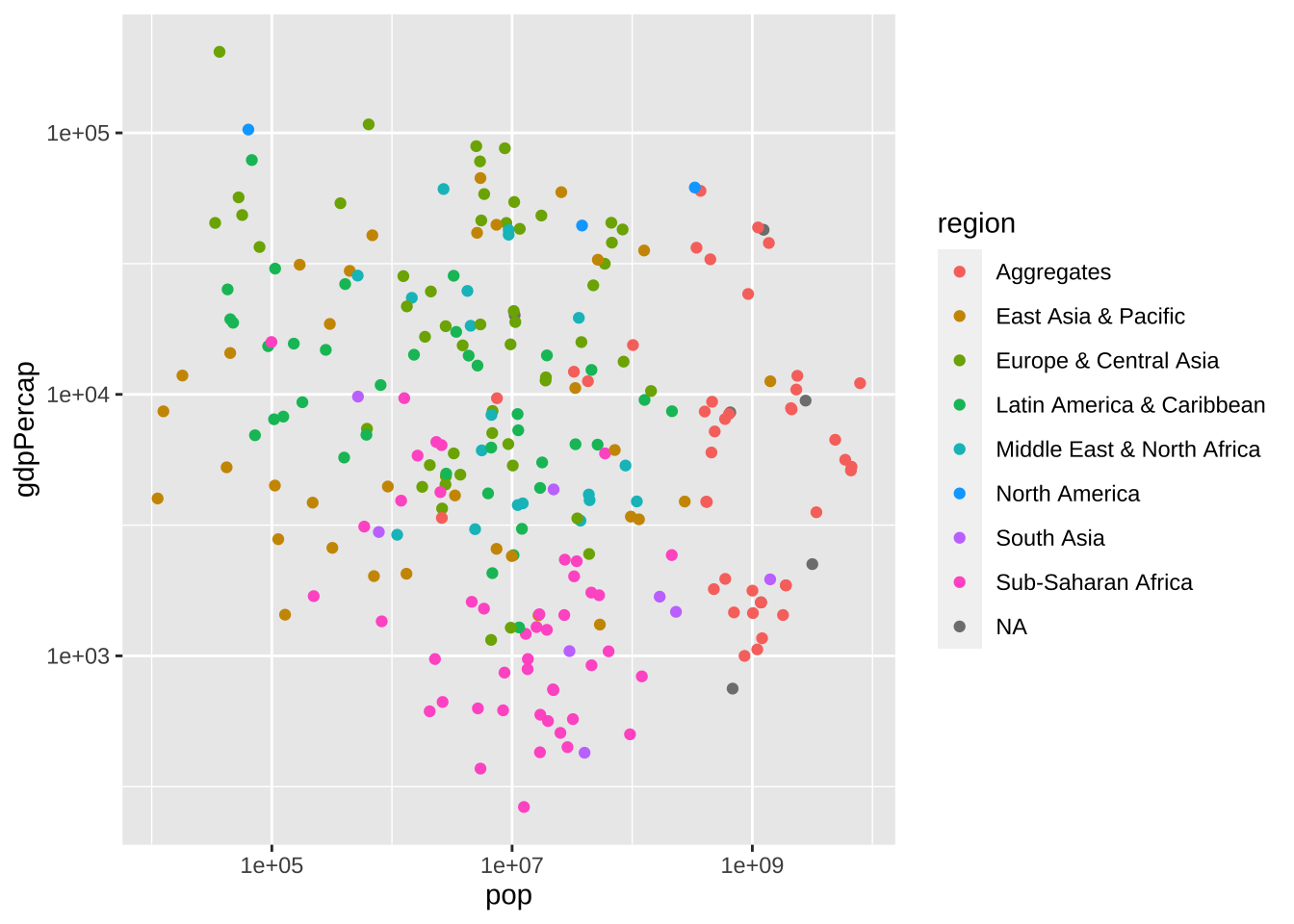
どうでしょうか。何か、発見はありますか。
19.5.7 世界地図
世界地図については、別の箇所で述べますが、簡単に説明しておきます。
maps パッケージ: https://CRAN.R-project.org/package=maps
まずは、地図データが必要です。ここでは、maps パッケージを使い、ggplot2 の geom_map() を使います。この世界地図は、たくさんの情報を持っています。region が、ほぼ国に対応しています。long と lat は、緯度と経度の情報で、国ごとに、境界線情報を、線で結ぶように、順序もつけて、与えています。あとで、df_wdi_extra と結合するために、共通の情報が必要なので、iso2c 情報を付け加えておきます。ここで使う、iso.alpha() は、maps パッケージの関数です。
library(maps)
#>
#> Attaching package: 'maps'
#> The following object is masked from 'package:purrr':
#>
#> map
worldmap <- map_data('world') |> mutate(iso2c = iso.alpha(region, n=2))
worldmapdf_wdi をそのまま組み込むとあまりに、列数が多くなるので、必要な部分だけ取り出し、それを、wdi_short とし、それから、iso2c, lifeExp, pop, gdpPercap, income, region を取り出します。region は、worldmap にも入っているので、違う名前にしておきます。
最初に準備したように、地図にも、iso2c がありますから、それを共通の鍵として、二つの表を結合します。表の結合は、次の章で学びます。
出来上がったのが、map_wdi です。つまり、地図データに、WDI の情報を加えたものです。
wdi_short <- df_wdi_extra |> filter(year == 2022, region != "Aggregates") |>
select(iso2c, lifeExp, pop, gdpPercap, income, wdi_region = region)
map_wdi <- worldmap |>
left_join(wdi_short, by = "iso2c")
map_wdi
map_wdi |> mutate(income_level = factor(income, levels = c("High income", "Upper middle income", "Lower middle income", "Low income", "Not classified", NA))) |>
ggplot() +
geom_map(aes(long, lat, map_id = region, fill = income_level), map = worldmap, col = "black", size = 0.1) +
labs(title = "2022 Income Level of the World")
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2
#> 3.4.0.
#> ℹ Please use `linewidth` instead.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where
#> this warning was generated.
#> Warning in geom_map(aes(long, lat, map_id = region, fill =
#> income_level), : Ignoring unknown aesthetics: x and y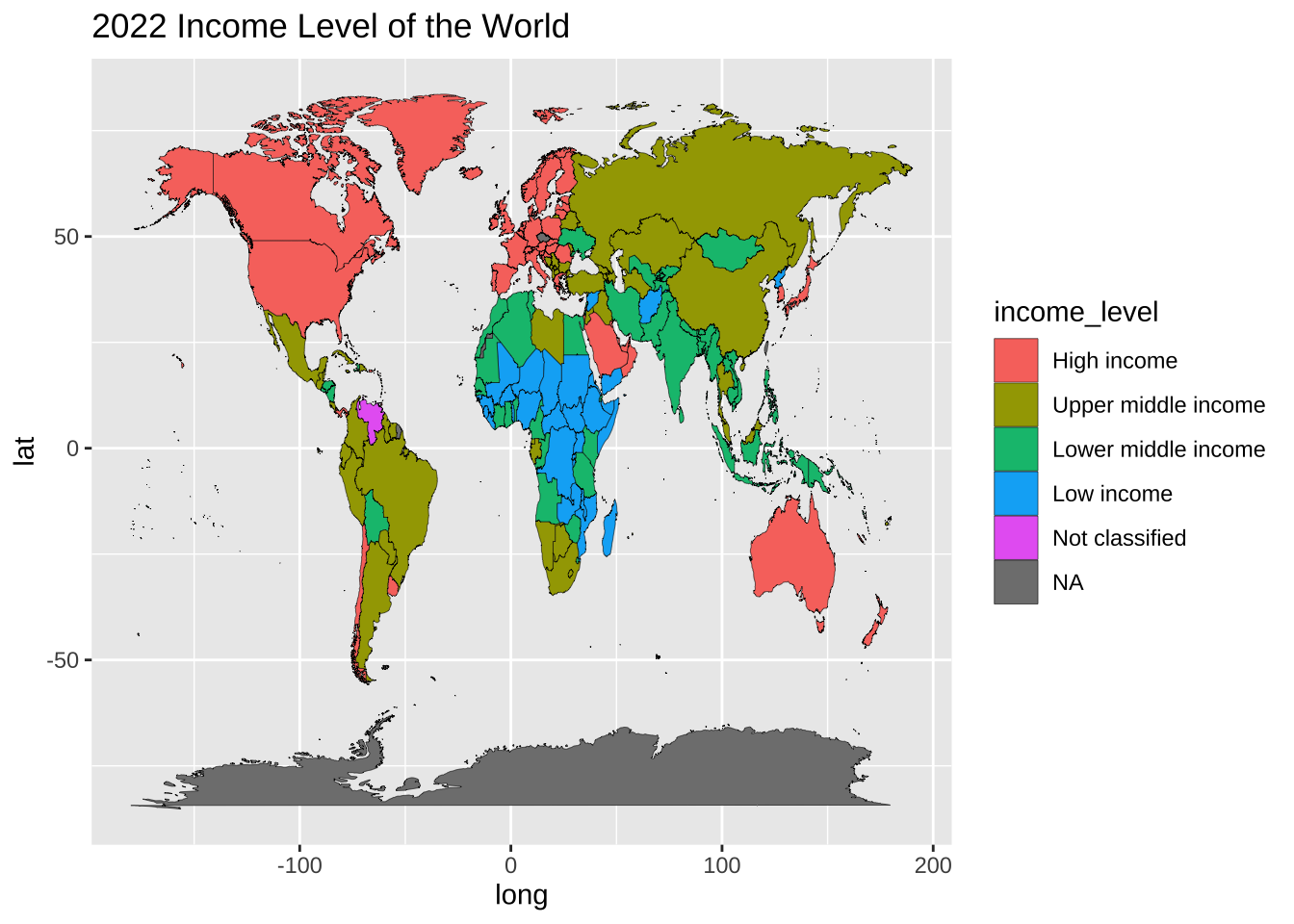
map_wdi |>
ggplot() +
geom_map(aes(long, lat, map_id = region, fill = wdi_region), map = worldmap, col = "black", size = 0.1) +
labs(title = "Regions of World in WDI")
#> Warning in geom_map(aes(long, lat, map_id = region, fill =
#> wdi_region), : Ignoring unknown aesthetics: x and y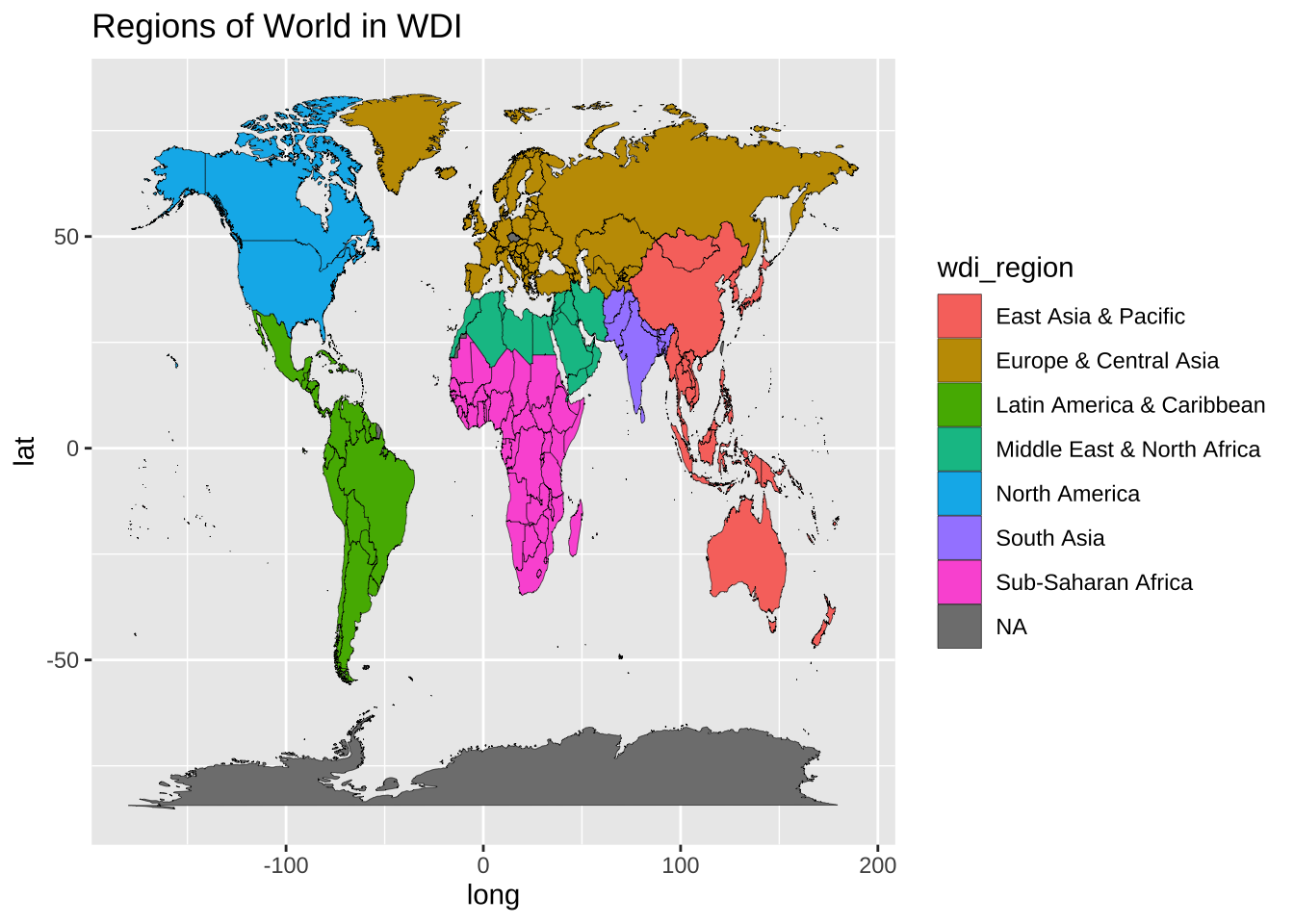
map_wdi |>
ggplot() +
geom_map(aes(x=long, y=lat, map_id = region, fill = log10(pop)), map = worldmap, col = "black", size = 0.1) +
labs(title = "2022 Population of the World by Country", fill = "pop in log10")
#> Warning in geom_map(aes(x = long, y = lat, map_id = region,
#> fill = log10(pop)), : Ignoring unknown aesthetics: x and y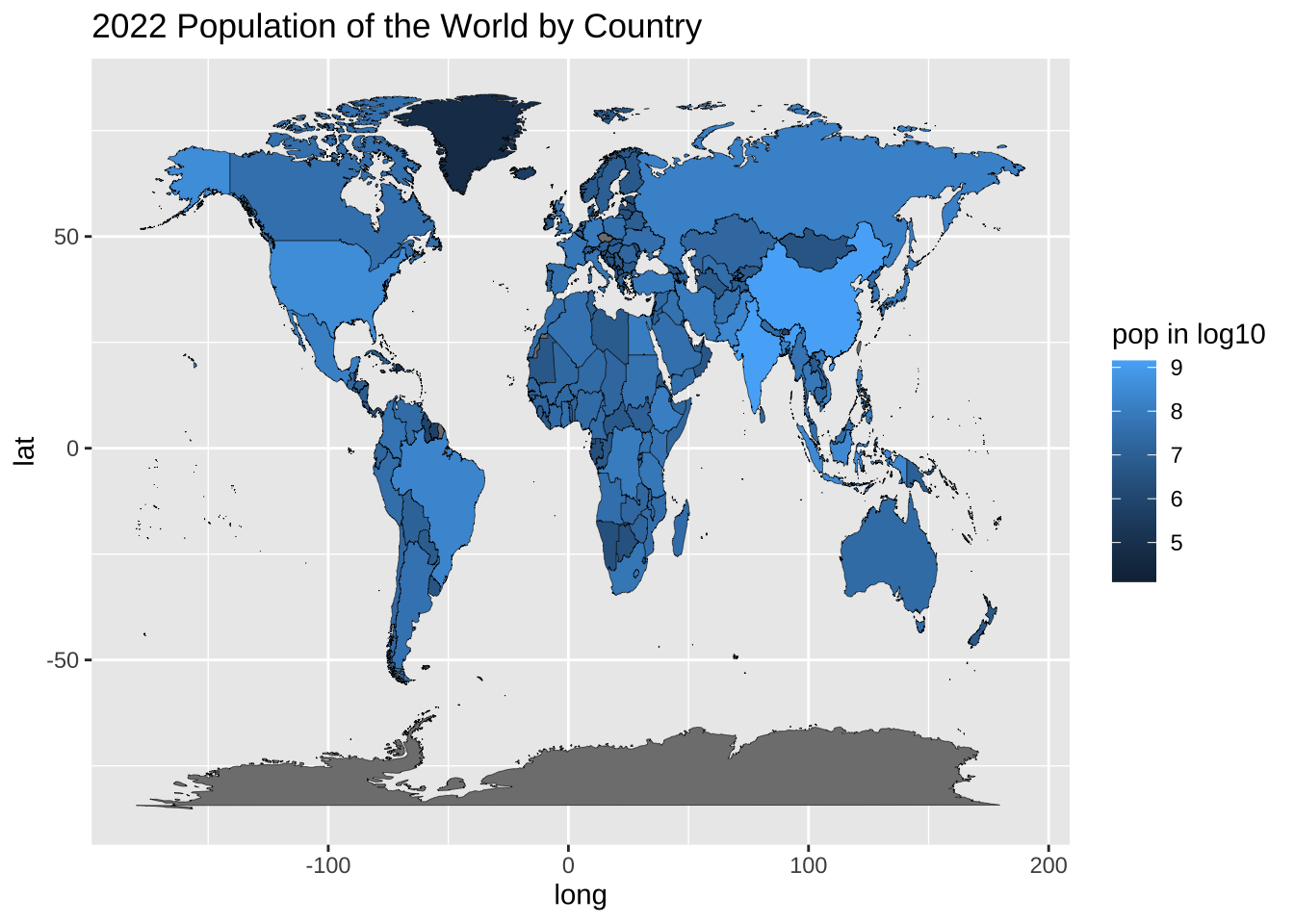
map_wdi には、他にも情報が入っていますから、さまざまな地図が描けますね。
19.6 まとめ
いくつかの、geom 関数について説明してきました。
geom_point, geom_boxplot, geom_histogram, geom_freqpoly, geom_density, geom_bar, geom_col, geom_text, geom_line, geom_smooth, geom_map
他にも、いろいろな geom 関数があります。
描画についての一般的なことをまとめておきましょう。
描画の原理(Grammar of Graphics)
Ggplot2 は、描画の原理という理論に則って設計されています。
一つ一つが層(Layer)になっていって、それを定めていくことで、描画(グラフを描いていくこと)をするという設計思想になっています。
データ:Data
変数の対応:Aestics(絵を飾る要素): Mapping
幾何的関数:Geom Functions
統計的処理方法:Stat Option
配置の選択:Position Option
座標の選択:Coordinate Function
尺度関数:Scale Function
テーマ関数:Theme Function
簡易的に表現すると、全体として次のようなコードになるというものです。すでに、実例をみてきましたから、おおまかなことは理解できるかと思います。このような設計思想を理解すると、コードを書く時にも、順に頭のなかで構成していくこともできるので、論理的に考えることができます。
ただ、あまり、理論にこだわるのは、ハードルを高くするだけだと思いますので、ここでは、設計思想の背景には、そんなものがあるのかぐらいに理解してくださればよいと思います。
ggplot (data = <DATA> ) +
<GEOM_FUNCTION> (mapping = aes( <MAPPINGS> ),
stat = <STAT> , position = <POSITION> ) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION> +
<SCALE_FUNCTION> +
<THEME_FUNCTION>最初にデータを指定します。パイプを使うことも可能です。
幾何関数は一つに限る必要はありませんが、まず、変数の対応を
mapping = aes()で、定義し、それに、統計処理が必要な時は、stat として加え、場所指定をする時には、position として加えます。座標系を指定します。
座標軸の物差しを指定します。
全体のテーマなどを最後に指定します。
ここで紹介した、GEOM 関数については、書きました。その中の、aes() の中身も、いくつか紹介しました。GEOM 関数により、少し変わりますね。たとえば、x, y, color, fill, shape, などです。
STAT の部分は、まだ紹介していませんが、POSITION は、初期値の “stack” と “dodge” を少しだけ説明しました。座標系(coord_trans)、座標軸(scale_x_discrete, scale_fill_discrete, scale_y_continuous, scale_y_log10, scale_colour_manual)、テーマ(theme, labs)も少しだけ例に出てきました。詳しくは、また、他の個所で説明します。
すべてを学習することはできませんが、どのような機能が必要かを考えて、例をみると、見当がつきやすいかもしれません。参考文献の早見表をわたしは、時々みています。
19.6.1 参考文献
-
早見表 Cheat Sheet in RStudio: https://www.rstudio.com/resources/cheatsheets/
‘Quick R’ by DataCamp: https://www.statmethods.net/management
19.7 練習
19.7.1 Posit Primers https://posit.cloud/learn/primers
データの視覚化:Visualize Data – r4ds: Explore, II
探索的データ分析:Exploratory Data Analysis
棒グラフ:Bar Charts
度数分布:Histograms
箱ひげ図:Boxplots and Counts
散布図:Scatterplots
折れ線グラフと地図:Line plots and maps
点データの重なり:Overplotting
さまざまな調整:Customize plots