31 その他のデータベース
31.1 国際連合専門機関および関連機関
Specialized agencies and related organizations
31.1.1 国際労働機関(International Labor Organization (ILO) )
ILO サイト:https://www.ilo.org/global/lang–en/index.htm
国際労働機関(ILO)は働く権利を促進し、ディーセントな雇用の機会を奨励し、社会的保護を高め、労働関連の問題に関する対話を強化する。世界の永続する平和は、社会正義を基礎としてのみ確立されるとの前提のもとに1919年に設立され、1946年に国連の最初の専門機関となった。すべての女性と男性にディーセント・ワーク(働きがいのある人間らしい仕事)の実現を目指し、労働基準を設定し、政策を発展させ、プログラムを策定する。その「国際労働基準」は、各国の担当当局が労働政策を実施する際の指針となる。また、政府がこれらの政策を効果的に実施できるように幅広い技術協力を行い、かつそうした努力を前進させるために必要な研修、教育、調査研究を行う。ILOは国際機関の中でもユニークな存在で、政策の作成にあたっては労働者と使用者の代表が政府代表と平等の発言権を持つ。ILOは三つの機関から構成される。
国際労働会議(総会)- 毎年開かれ、政府、使用者、労働者の3者代表が参加する。国際労働基準を設定するとともに、全世界にとって重要な社会問題や労働問題を討議するためのフォーラムとなる。 管理理事会 - ILOの活動に指示を与え、事業計画と予算を作成し、ILO基準が順守されていないとの苦情を審議する。 国際労働事務局 - ILOの恒久事務局である。 さらに、イタリアのトリノにある「国際研修センター」が研究と研修の機会を提供している。ILOは重要な労働政策の分野において最新の研究を刊行し、また労働統計に関しては世界でも主要な提供者である。
31.1.1.1 ILOSTAT
-
Website: https://ilostat.ilo.org/data/
検索をすると、ILOSTAT Explorer が立ち上がります。
例:Average monthly earnings of employees by sex and economic activity -- Annual - ILOSTAT Explorer
-
R パッケージ Rilostat
-
CRAN パッケージサイト:https://cran.r-project.org/web/packages/Rilostat/index.html
Rilostat: ILO Open Data via Ilostat Bulk Download Facility or SDMX Web Service
マニュアル Manual
-
活用例 Vignettes: https://ilostat.github.io/Rilostat/articles/Rilostat.html
- 基本的な機能 Essential Functionality
-
31.1.1.2 例:実質賃金(EAR_4MTH_SEX_ECO_CUR_NB_A)
install.packages("Rilostat") # 最初に一度だけインストール
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(Rilostat)検索を wage でしてみるがどうも、十分現れない。
get_ilostat_toc(search = 'wage')earnings で検索すると、現れる。検索の仕方は検討する必要がある。
get_ilostat_toc(search = 'earnings')id がわかっていればその一部を入れて検索も可能。
get_ilostat_toc(search = 'EAR_4MTH')データをダウンロード
df_ilo_wages <- get_ilostat("EAR_4MTH_SEX_ECO_CUR_NB_A", cache = FALSE)#> Rows: 353008 Columns: 12
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (10): ref_area, source, indicator, sex, classif1, cl...
#> dbl (2): time, obs_value
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.みてみる
df_ilo_wagesそれぞれ、どのような値があるか、カテゴリカルな列のみみてみる。
df_ilo_wages |> filter(ref_area == "JPN", time == 2020) |>
select(1:6) |> lapply(unique)
#> $ref_area
#> [1] "JPN"
#>
#> $source
#> [1] "DA:260"
#>
#> $indicator
#> [1] "EAR_4MTH_SEX_ECO_CUR_NB"
#>
#> $sex
#> [1] "SEX_T" "SEX_M" "SEX_F"
#>
#> $classif1
#> [1] "ECO_AGGREGATE_TOTAL" "ECO_ISIC4_TOTAL"
#> [3] "ECO_ISIC4_B" "ECO_ISIC4_C"
#> [5] "ECO_ISIC4_F" "ECO_ISIC4_G"
#> [7] "ECO_ISIC4_H" "ECO_ISIC4_I"
#> [9] "ECO_ISIC4_J" "ECO_ISIC4_K"
#> [11] "ECO_ISIC4_L" "ECO_ISIC4_M"
#> [13] "ECO_ISIC4_P" "ECO_ISIC4_Q"
#> [15] "ECO_ISIC4_R" "ECO_ISIC4_S"
#>
#> $classif2
#> [1] "CUR_TYPE_LCU" "CUR_TYPE_PPP" "CUR_TYPE_USD"classif1 と classif2 の意味を確認する必要があるので、辞書機能を使って、みてみる。
get_ilostat_dic("classif1") |> filter(grepl("ECO", classif1))
get_ilostat_dic("classif2") |> filter(grepl("CUR", classif2))一応、ECO_AGGREGATE_TOTAL と、CUR_TYPE_PPP を指標にとり、グラフを書いてみる。year が 文字列になっている部分のみ修正。
df_ilo_wages |> filter(classif1 == "ECO_AGGREGATE_TOTAL", classif2 == "CUR_TYPE_PPP", ref_area == "JPN") |> mutate(time = as.numeric(time)) |>
ggplot(aes(time, obs_value, color = sex)) + geom_line()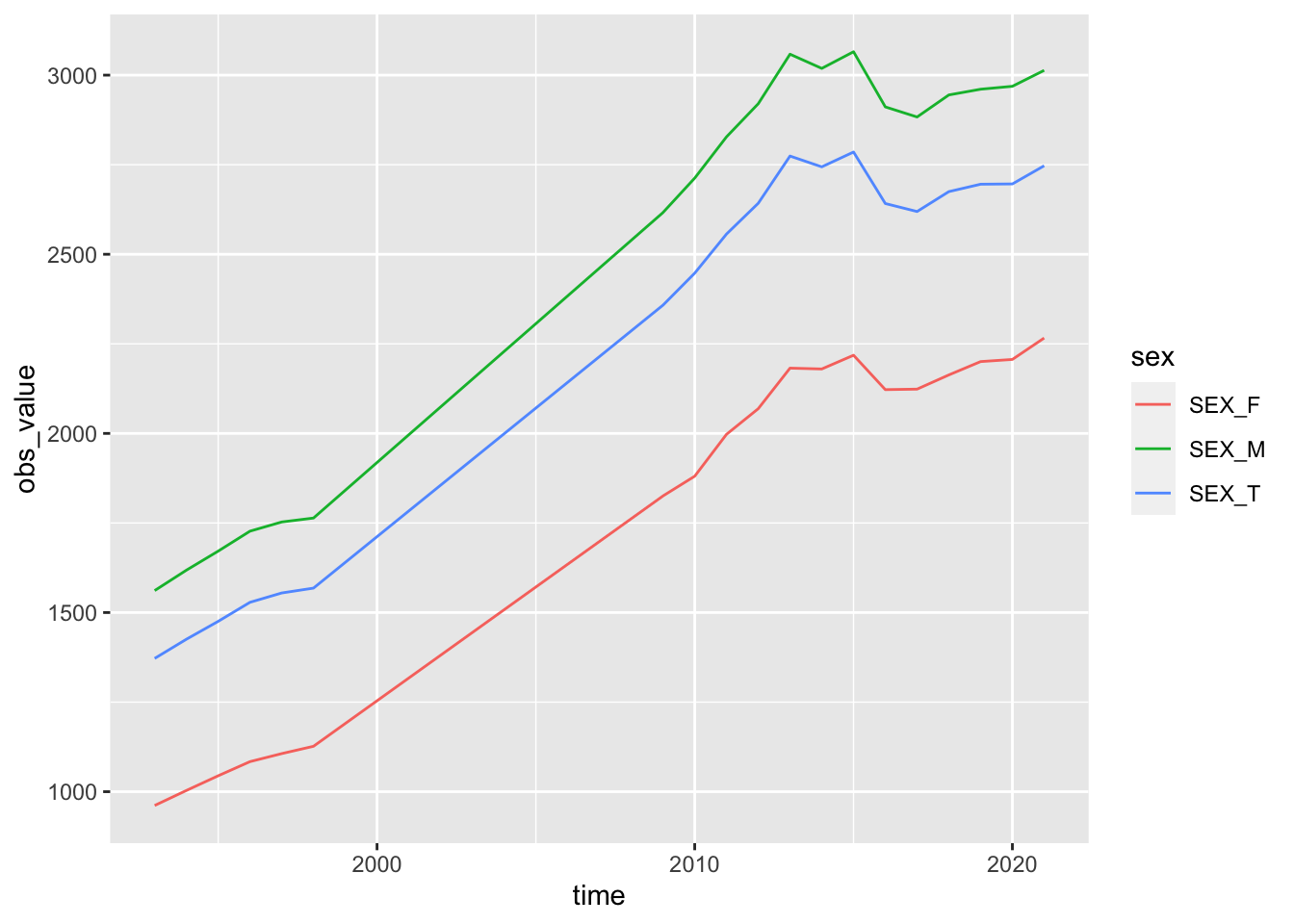
他の国の状況もみてみる。
df_ilo_wages |> filter(ref_area %in% c("JPN", "GBR", "DEU", "USA", "CHN")) |>
filter(sex == "SEX_T") |>
filter(classif1 == "ECO_AGGREGATE_TOTAL", classif2 == "CUR_TYPE_PPP") |>
mutate(time = as.numeric(time)) |>
ggplot(aes(time, obs_value, color = ref_area)) + geom_line()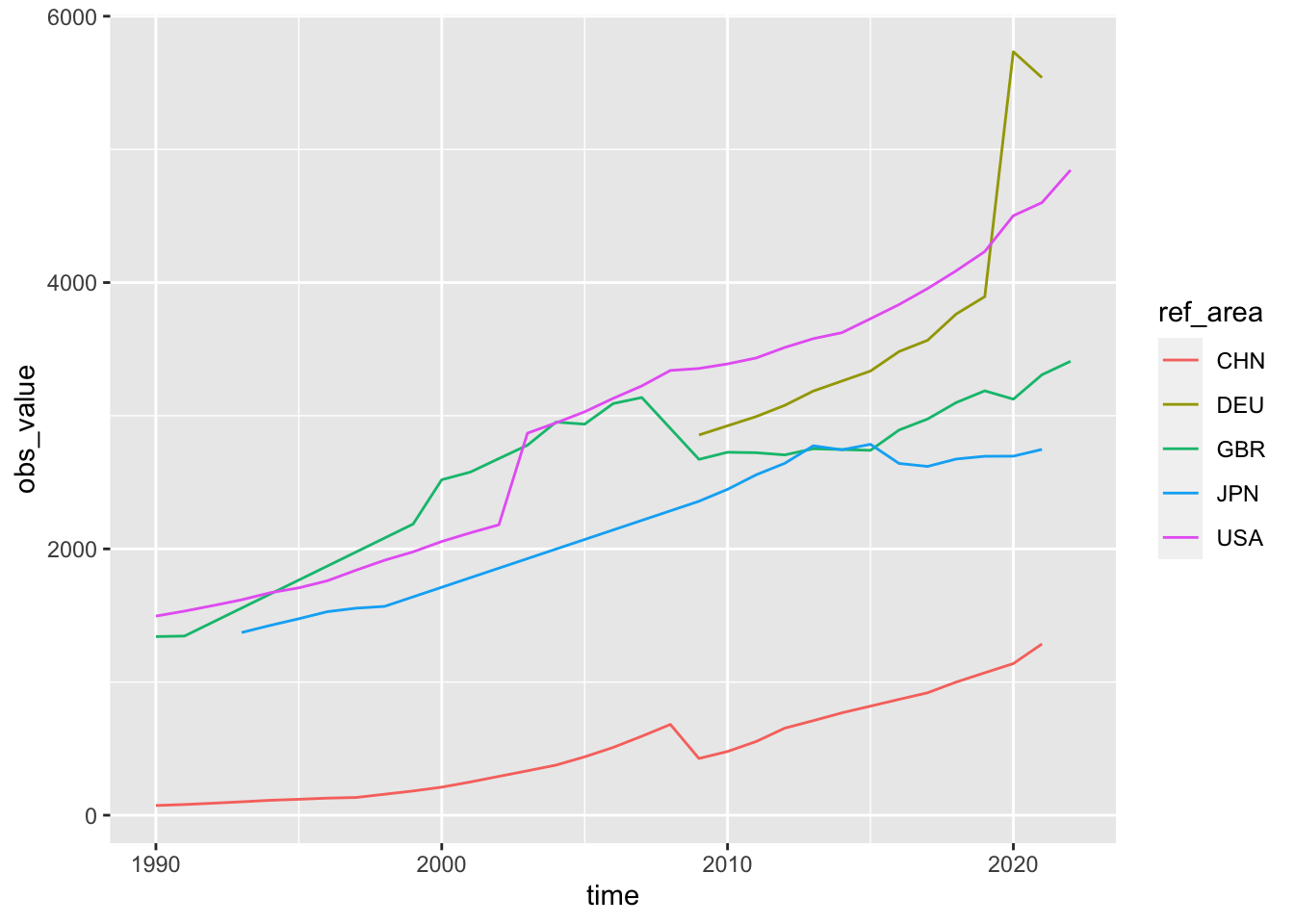
31.1.1.3 データ取得時のオプション
Import Data with an Option
type = “both” とすると、指標の内容も書かれていて、get_ilostat_dic() を使わなくて良いが、余分なものが多くて見にくい面もある。
df_ilo_wages_both <- get_ilostat("EAR_4MTH_SEX_ECO_CUR_NB_A", type = "both", cache = FALSE)
df_ilo_wages_both
colnames(df_ilo_wages_both)
#> [1] "ref_area" "ref_area.label"
#> [3] "source" "source.label"
#> [5] "indicator" "indicator.label"
#> [7] "sex" "sex.label"
#> [9] "classif1" "classif1.label"
#> [11] "classif2" "classif2.label"
#> [13] "time" "obs_value"
#> [15] "obs_status" "obs_status.label"
#> [17] "note_classif" "note_classif.label"
#> [19] "note_indicator" "note_indicator.label"
#> [21] "note_source" "note_source.label"
colnames(df_ilo_wages)
#> [1] "ref_area" "source" "indicator"
#> [4] "sex" "classif1" "classif2"
#> [7] "time" "obs_value" "obs_status"
#> [10] "note_classif" "note_indicator" "note_source"31.1.1.4 例:所得の労働分配率
labor share of income
get_ilostat_toc(search = 'income')
id_income <- get_ilostat_toc(search = 'income') |> pull(id) |> unique()
id_income
#> [1] "SDG_1041_NOC_RT_A" "LAP_2GDP_NOC_RT_A"
#> [3] "LAP_2LID_QTL_RT_A" "LAP_2FTM_NOC_RT_A"SDG_1041_NOC_RT_A: SDG indicator 10.4.1 - Labour income share as a percent of GDP (%)
df_sdg_lis <- get_ilostat("SDG_1041_NOC_RT_A", cache = FALSE) |>
mutate(time = as.numeric(time))
df_sdg_lisLAP_2GDP_NOC_RT_A: Labour income share as a percent of GDP -- ILO modelled estimates, Nov. 2021 (%)
df_income_dist <- get_ilostat("LAP_2GDP_NOC_RT_A", cache = FALSE) |>
mutate(time = as.numeric(time))
df_income_distLAP_2LID_QTL_RT_A: Labour income distribution – ILO modelled estimates, Nov. 2021 (%)
df_labor_income_share <- get_ilostat("LAP_2LID_QTL_RT_A", cache = FALSE) |>
mutate(time = as.numeric(time))
df_labor_income_shareLAP_2FTM_NOC_RT_A: Gender income gap, ratio of women’s to men’s labour income – ILO modelled estimates, Nov. 202
df_gender_income_gap <- get_ilostat("LAP_2GDP_NOC_RT_A", cache = FALSE) |>
mutate(time = as.numeric(time))
df_gender_income_gap4つの指標一度に取ることも可能。
df_income <- get_ilostat(c("SDG_1041_NOC_RT_A", "LAP_2GDP_NOC_RT_A", "LAP_2LID_QTL_RT_A", "LAP_2FTM_NOC_RT_A"), cache = FALSE) |>
mutate(time = as.numeric(time))
df_income
df_income$indicator |> unique()
#> [1] "SDG_1041_NOC_RT" "LAP_2GDP_NOC_RT" "LAP_2LID_QTL_RT"
#> [4] "LAP_2FTM_NOC_RT"
id_income
#> [1] "SDG_1041_NOC_RT_A" "LAP_2GDP_NOC_RT_A"
#> [3] "LAP_2LID_QTL_RT_A" "LAP_2FTM_NOC_RT_A"
df_income |> filter(ref_area == "JPN", time == 2020) |> select(2,3,4,7) |>
lapply(unique)
#> $source
#> [1] "XA:1843"
#>
#> $indicator
#> [1] "SDG_1041_NOC_RT" "LAP_2GDP_NOC_RT" "LAP_2LID_QTL_RT"
#>
#> $classif1
#> [1] NA "QTL_DECILE_01" "QTL_DECILE_02"
#> [4] "QTL_DECILE_03" "QTL_DECILE_04" "QTL_DECILE_05"
#> [7] "QTL_DECILE_06" "QTL_DECILE_07" "QTL_DECILE_08"
#> [10] "QTL_DECILE_09" "QTL_DECILE_10"
#>
#> $obs_status
#> [1] NA "M"
get_ilostat_dic("classif1") |> filter(grepl("QTL_DECILE", classif1))
df_income |> filter(ref_area == "JPN", indicator == "SDG_1041_NOC_RT") |>
ggplot(aes(time, obs_value)) + geom_line()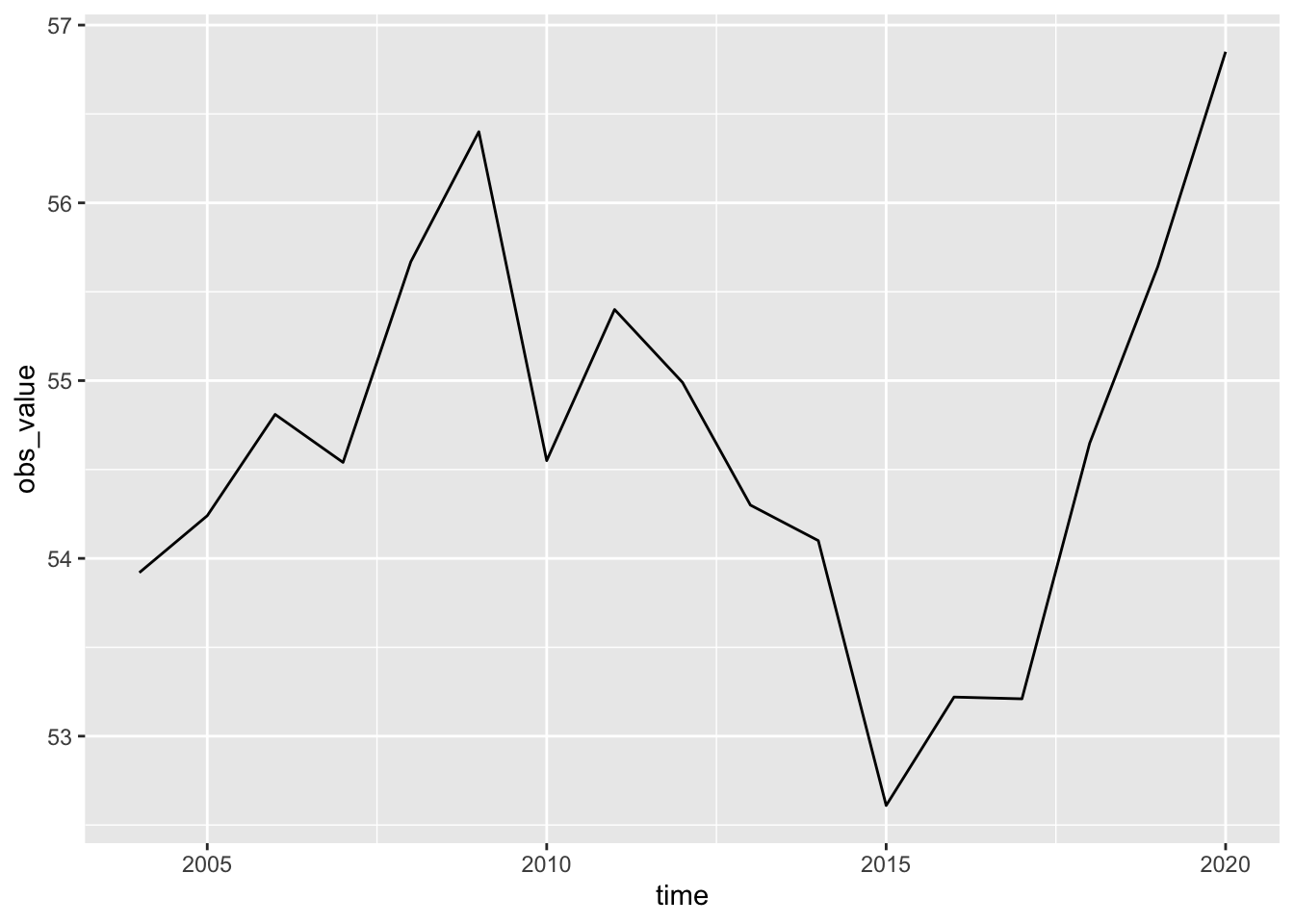
df_income |> filter(ref_area == "JPN", indicator == "LAP_2GDP_NOC_RT") |>
ggplot(aes(time, obs_value)) + geom_line()
2つの指標とも同じようです。
df_income |> filter(ref_area == "JPN", indicator != "LAP_2LID_QTL_RT") |>
ggplot(aes(time, obs_value, col = indicator)) + geom_line()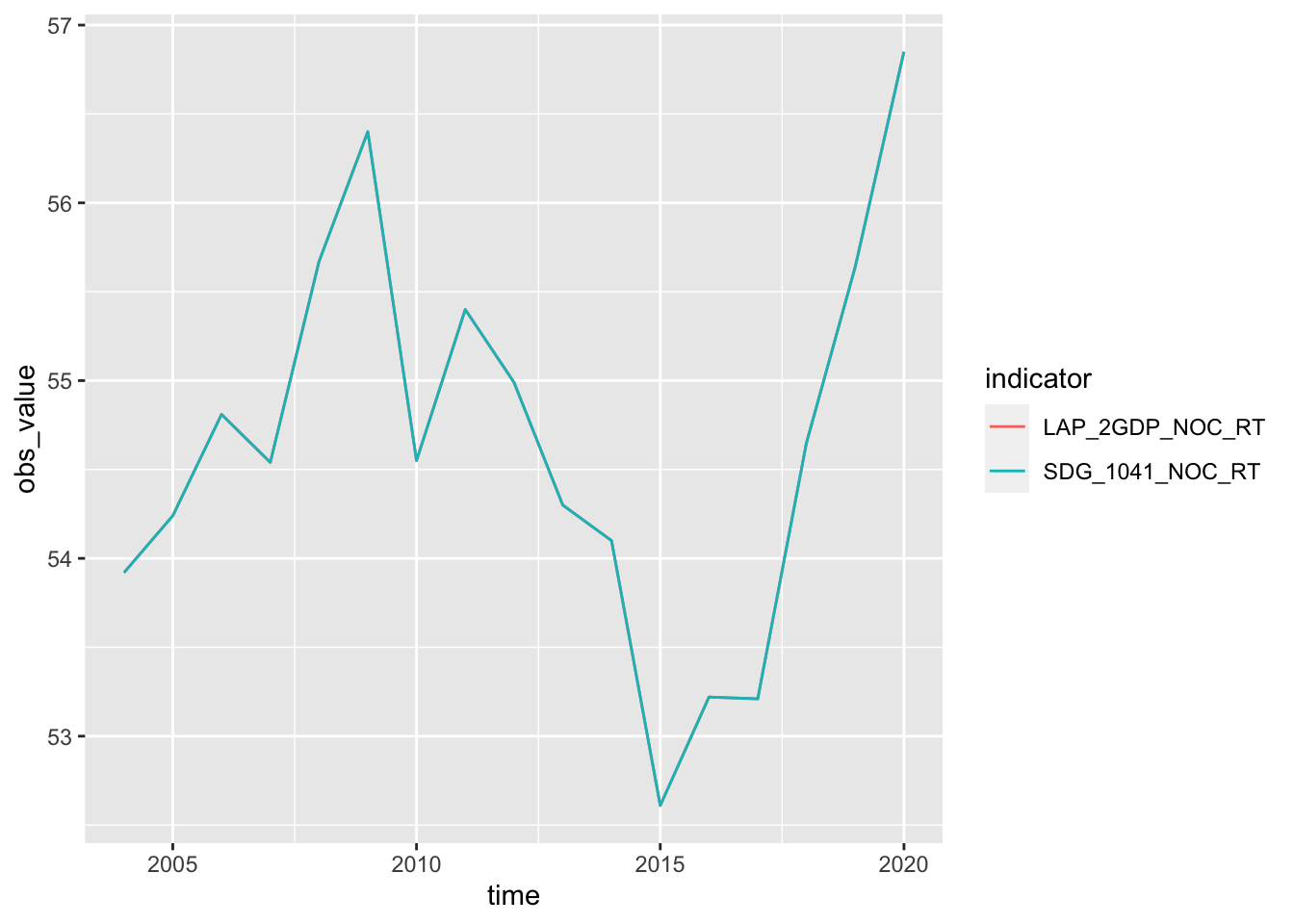
df_income |> filter(ref_area == "JPN", indicator == "LAP_2LID_QTL_RT") |>
ggplot(aes(time, obs_value, col = classif1)) + geom_line()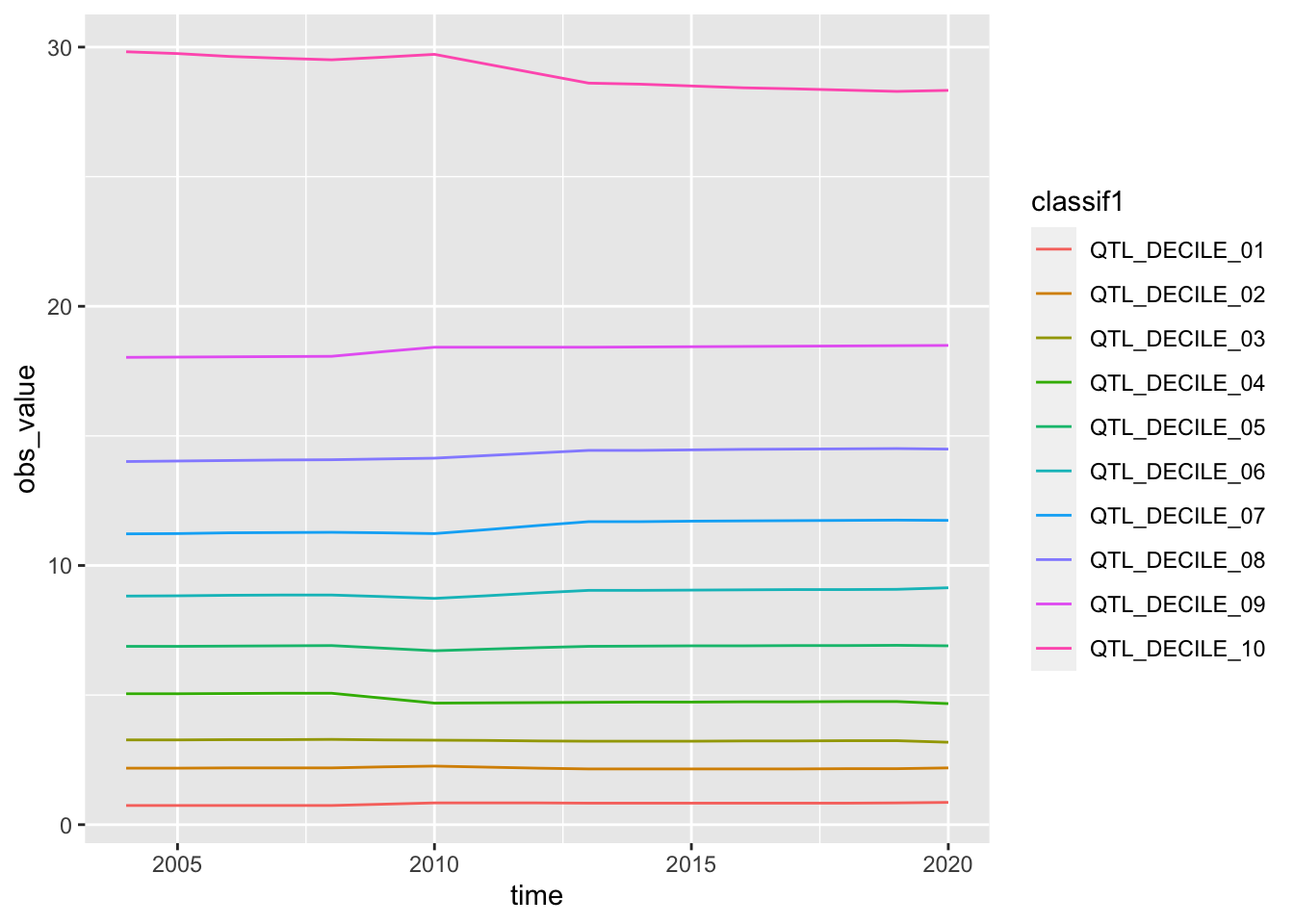
df_income |> filter(ref_area == "JPN", indicator == "LAP_2LID_QTL_RT") |>
ggplot(aes(time, obs_value, fill = classif1)) + geom_area(col = "black", linewidth = 0.2)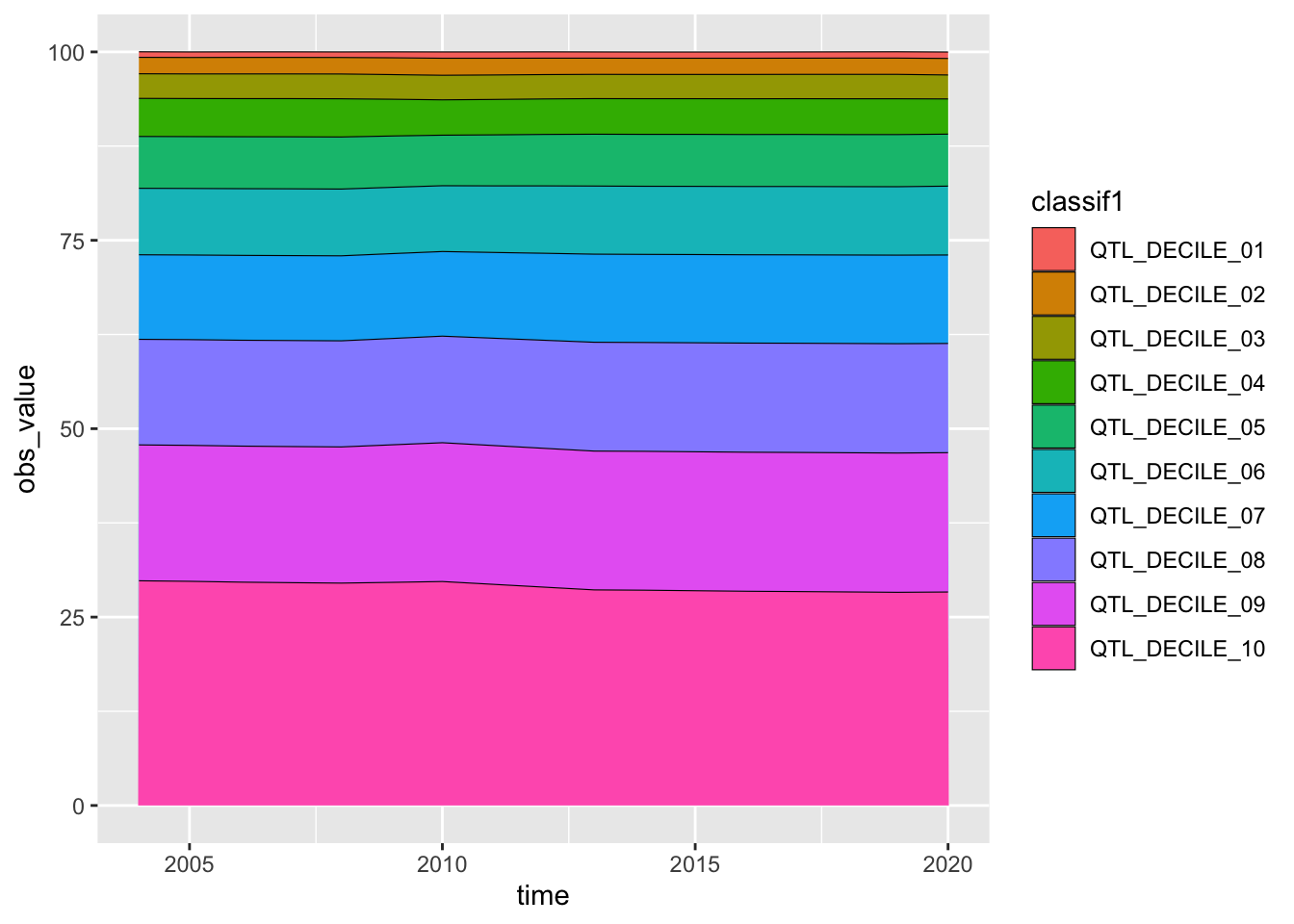
df_income |> filter(ref_area == "JPN", indicator == "LAP_2LID_QTL_RT") |>
ggplot(aes(time, obs_value, fill = fct_rev(classif1))) + geom_area(col = "black", linewidth = 0.2)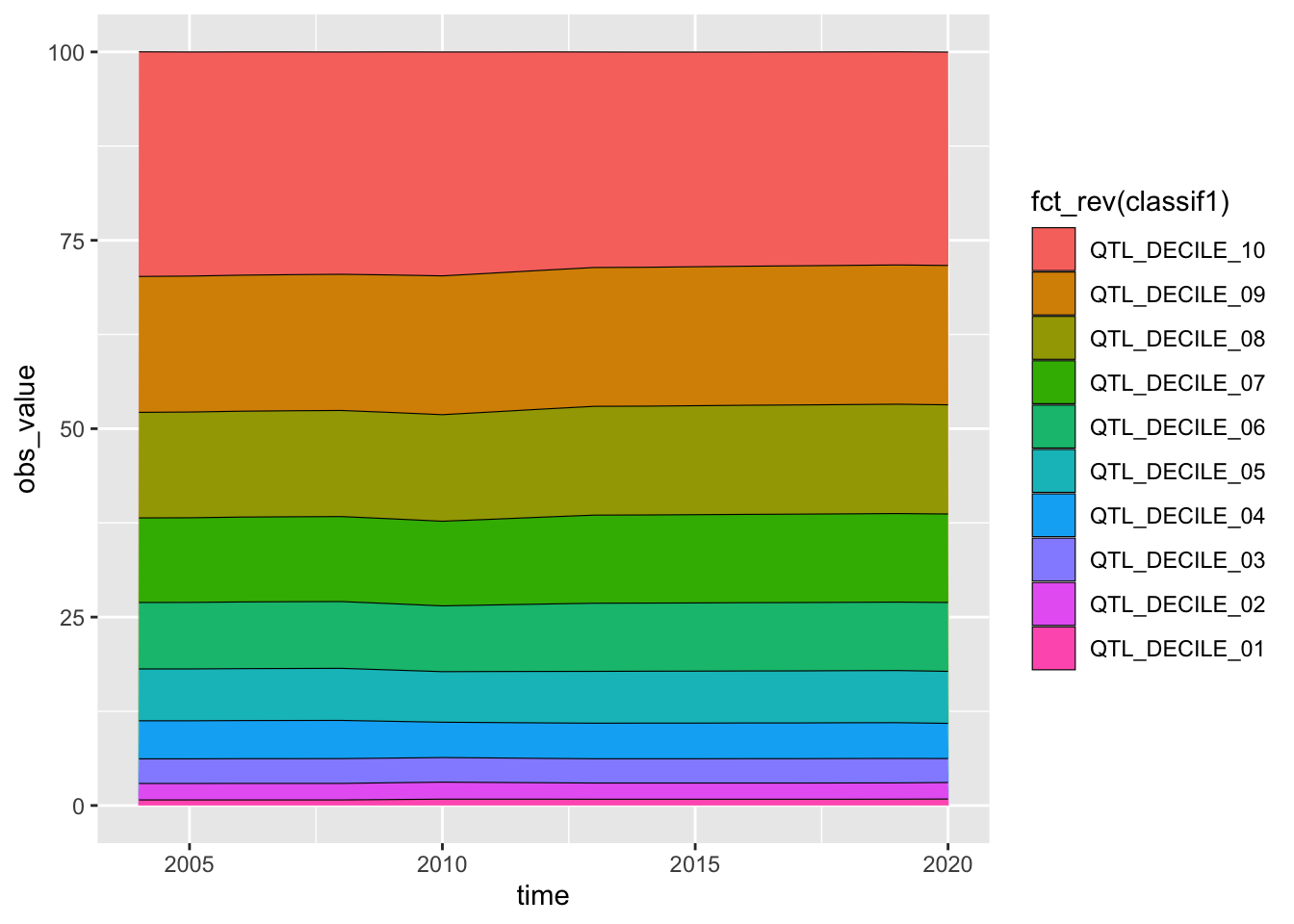
他の機能も確認する必要あり。
31.1.2 国連児童基金(UNICEF: United Nations Children’s Fund)
データサイト:https://data.unicef.org
31.1.3 世界保健機関(WHO: World Health Organization)
世界保健機関は1948年に設立され、国連システムの中にあって保健について指示を与え、調整する機関である。WHOは、グローバルな保健問題についてリーダーシップを発揮し、健康に関する研究課題を作成し、規範や基準を設定する。また、証拠に基づく政策選択肢を明確にし、加盟国へ技術的支援を行い、健康志向を監視、評価する。その政策決定機関は世界保健総会で、毎年開かれ、194全加盟国の代表が出席する。執行理事会は保健の分野で技術的に資格のある34人のメンバーで構成される。
WHO ホームページ:https://www.who.int
Data at WHO:https://www.who.int/data
31.1.4 国際通貨基金(IMF: International Monetary Fund)
ホームページ:https://www.imf.org/en/home
日本語ホームページ:https://www.imf.org/ja/Home
IMF データ:https://www.imf.org/en/Data、
データサイト:https://data.imf.org/?sk=388dfa60-1d26-4ade-b505-a05a558d9a42
国際通貨基金(IMF)は、生産性や雇用創出、健全な経済に必要不可欠となる金融の安定と国際通貨協力を促す経済政策を支援することで、全ての加盟国190か国が持続的な成長と繁栄を実現するための取り組みを行っています。 IMFは、加盟国によって運営され、加盟国政府に対して責任を負っています
業務
IMFは3つの重要な任務があります。国際通貨協力の強化、貿易の拡大・経済成長の促進、繁栄を損なう政策の抑制、の3つです。任務を達成するため、IMF加盟国は互いに、また他の国際機関と協力して働いています。
31.1.4.1 R Package
imfr: https://github.com/christophergandrud/imfr
2022年までは、CRAN に登録されたパッケージでした。詳細は、上の GitHub ページを参照してください。
31.2 世界の国の政府機関
31.2.1 米国:DATA.GOV
The Home of the U.S. Government’s Open Data: https://data.gov/
31.2.2 米国国勢調査:United States Census Bureau
Explore Census Data: https://data.census.gov
31.3 ClinicalTrials.gov
ClinicalTrials.gov is a place to learn about clinical studies from around the world.
31.5 Kagle
Kagle Home: https://www.kaggle.com
Kagle Datasets: https://www.kaggle.com/datasets
31.6 Gapminder
31.6.1 パッケージ Gapminder を使って
gapminder: Data from Gapminder: https://cran.r-project.org/web/packages/gapminder/index.html
Gapminder Data: https://www.gapminder.org/data/
すでに、dplyr をつかった変形で確認しましたが、簡単に、データを見ておきましょう。
glimpse(df_gm)
#> Rows: 1,704
#> Columns: 6
#> $ country <fct> "Afghanistan", "Afghanistan", "Afghanist…
#> $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia…
#> $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982…
#> $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, …
#> $ pop <int> 8425333, 9240934, 10267083, 11537966, 13…
#> $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, …
summary(df_gm)
#> country continent year
#> Afghanistan: 12 Africa :624 Min. :1952
#> Albania : 12 Americas:300 1st Qu.:1966
#> Algeria : 12 Asia :396 Median :1980
#> Angola : 12 Europe :360 Mean :1980
#> Argentina : 12 Oceania : 24 3rd Qu.:1993
#> Australia : 12 Max. :2007
#> (Other) :1632
#> lifeExp pop gdpPercap
#> Min. :23.60 Min. :6.001e+04 Min. : 241.2
#> 1st Qu.:48.20 1st Qu.:2.794e+06 1st Qu.: 1202.1
#> Median :60.71 Median :7.024e+06 Median : 3531.8
#> Mean :59.47 Mean :2.960e+07 Mean : 7215.3
#> 3rd Qu.:70.85 3rd Qu.:1.959e+07 3rd Qu.: 9325.5
#> Max. :82.60 Max. :1.319e+09 Max. :113523.1
#>
unique(df_gm$year)
#> [1] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 2002
#> [12] 200731.6.1.0.1 Box Plot
ggplot(df_gm, aes(x = as_factor(year), y = lifeExp)) + geom_boxplot()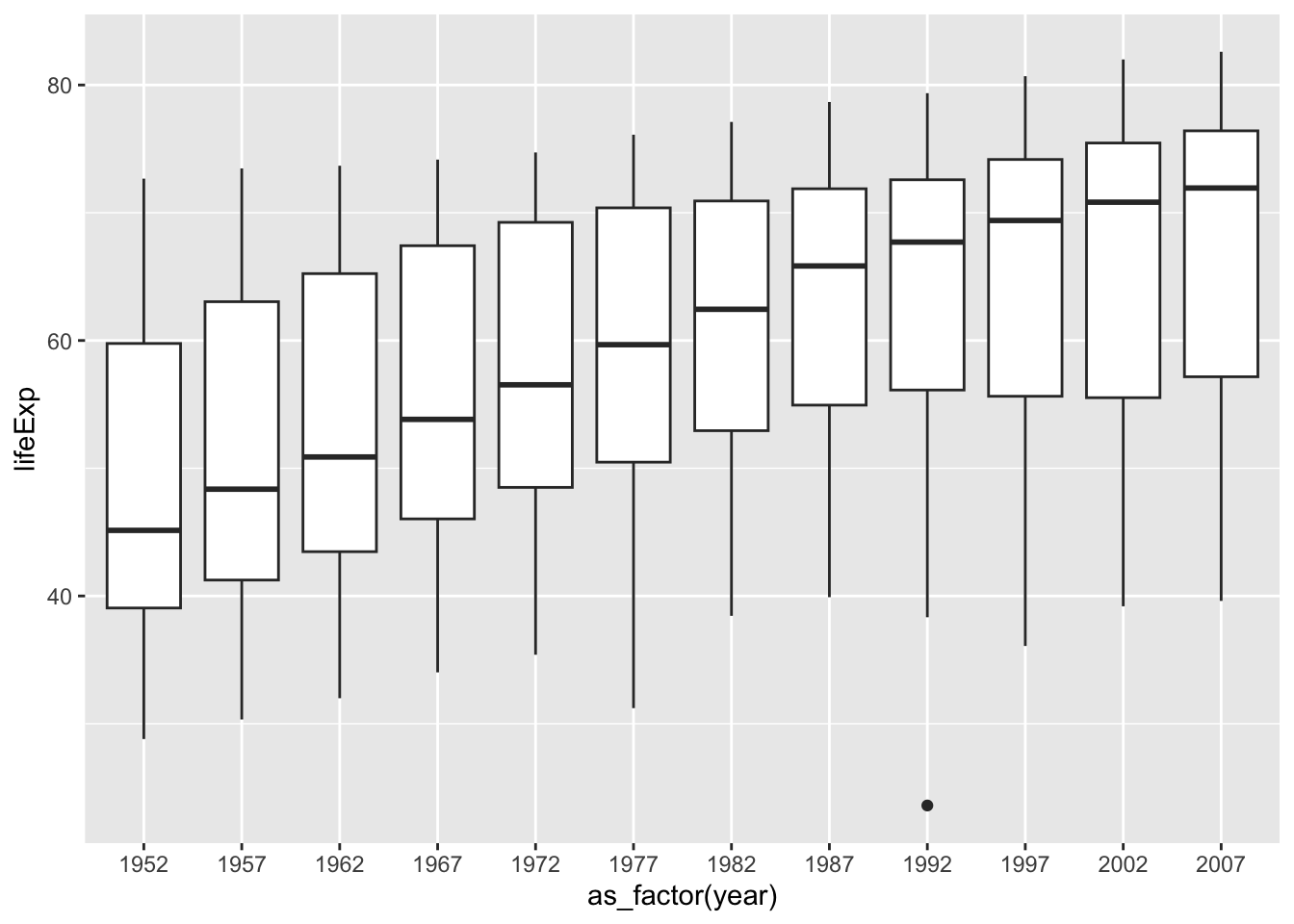
fill や color を追加してみましょう。
df_gm %>% filter(year %in% c(1952, 1987, 2007)) %>%
ggplot(aes(x=as_factor(year), y = lifeExp, fill = continent)) +
geom_boxplot()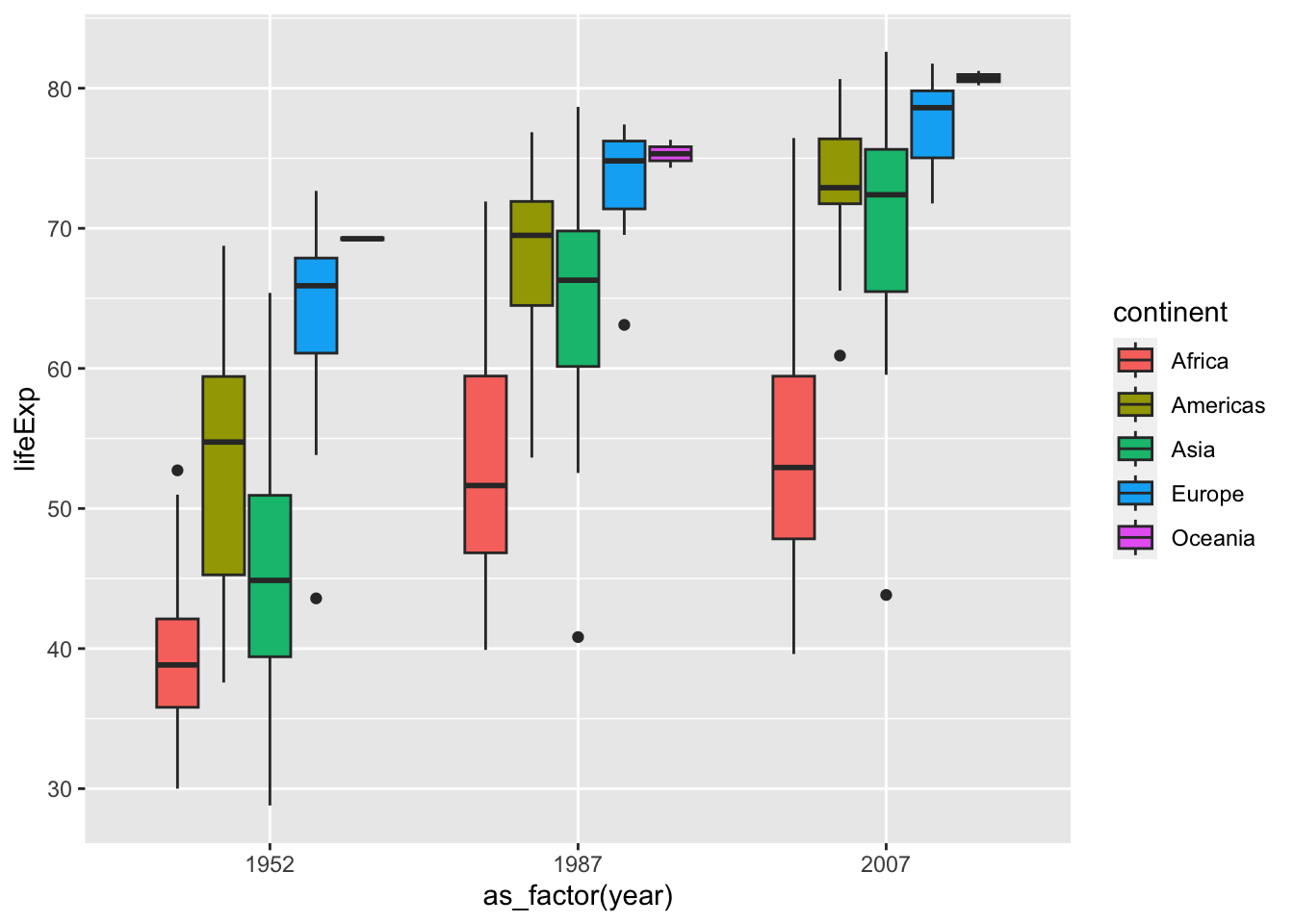
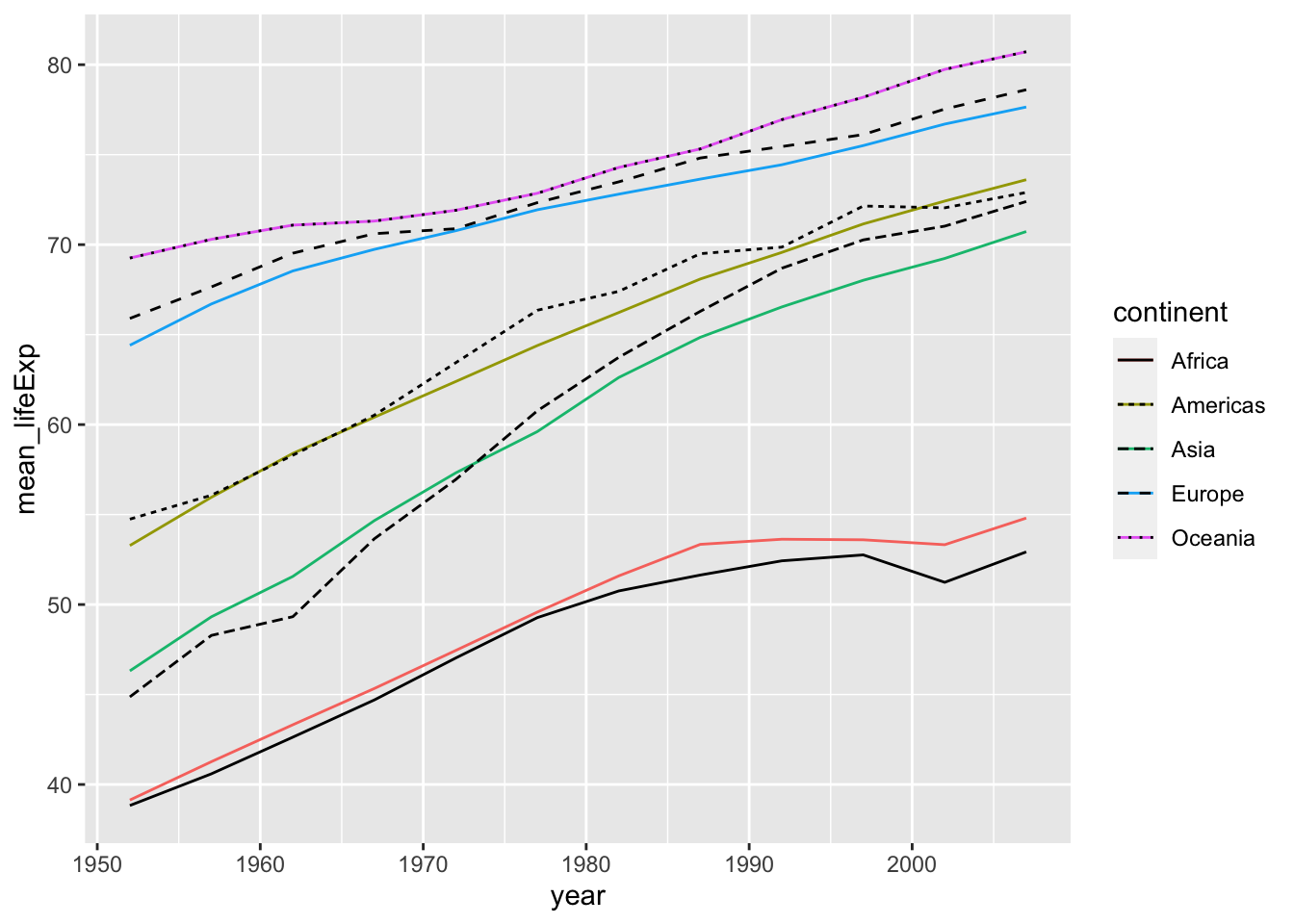
折れ線グラフの例です。
df_lifeExp <- df_gm %>%
group_by(continent, year) %>%
summarize(mean_lifeExp = mean(lifeExp), median_lifeExp = median(lifeExp), max_lifeExp = max(lifeExp), min_lifeExp = min(lifeExp), .groups = "keep")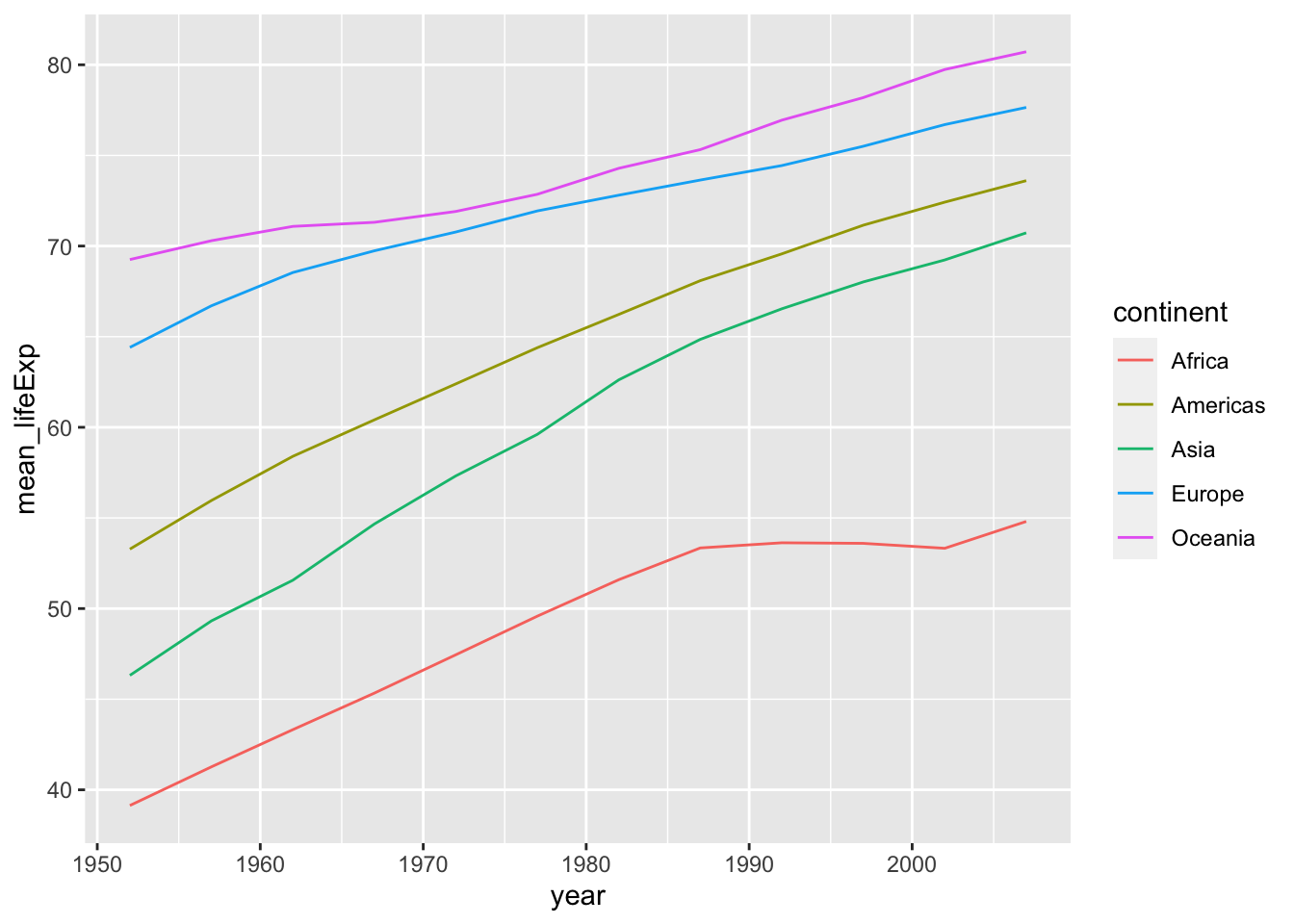
df_lifeExp %>% ggplot(aes(x = year, y = mean_lifeExp, color = continent, linetype = continent)) +
geom_line()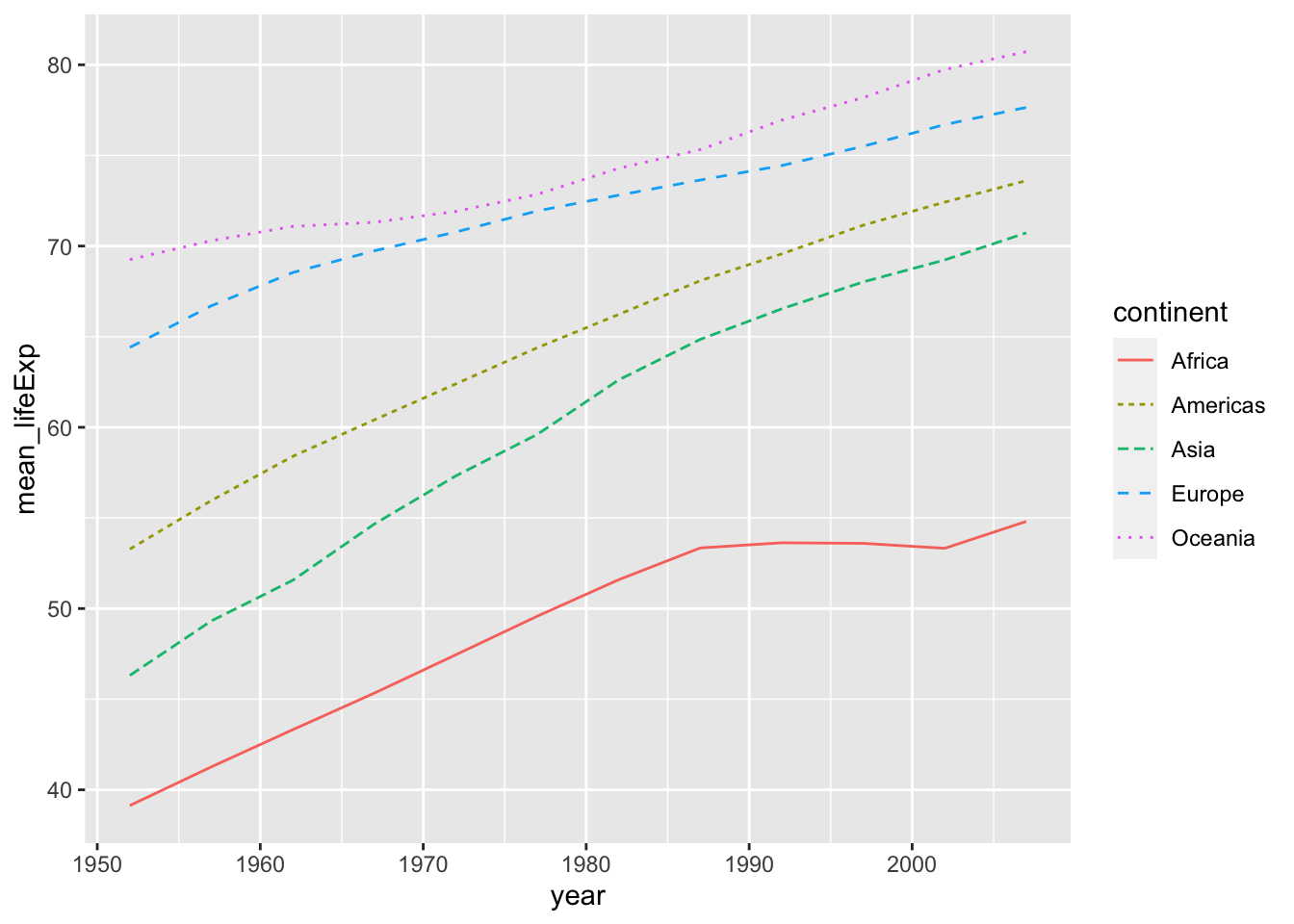
df_lifeExp %>% ggplot() +
geom_line(aes(x = year, y = mean_lifeExp, color = continent)) +
geom_line(aes(x = year, y = median_lifeExp, linetype = continent))