18 変形(Transform)
ここでは、
tidyverseパッケージを構成するdplyrパッケージを用いて、データを変形することを学びます。変形とは、例えば、データのなかのある条件を満たす行や列を抽出(取り出)したり、特定の列を修正したり、データの中のいくつかの列に含まれる情報をもとに計算して、新たな列を作ったり、グループに分けたり、順番を入れ替えたりといったことです。データを集約し(まとめ)たり、グラフを作成するときにも、必要不可欠な作業です。
dplyrパッケージを用いて、二つのデータを結合することなども可能ですが、それは、あとから扱います。これも、tidyverseパッケージを構成するtidyrパッケージ による変形も、後ほど扱います。
dplyr パッケージは、tidyverse パッケージをインストールしたり、使えるように library(tidyverse) で読み込んだりするときに、一緒に読み込まれますから、あらためて、dplyr を指定する必要はありません。
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
18.1 dplyr 概要
dplyr はデータ操作の文法のようなもので、最も一般的なデータ操作に役立つ一貫したいくつかの「動詞」の役割を果たすものを提供しています。
-
select()変数をその名前によって選択 - 列の選択に対応します。 -
filter()ケースをその値によって選択 - 行の選択に対応します。 -
mutate()新しい変数を既存の値を使って定義します - 新しい列を作成することに対応しています。 -
summarise()22 たくさんの値を一つの値に集約します - 代表値(平均、メディアンなど)を求めることに対応します。 -
arrange()行の順序を変更します。 -
group_by()グループを指定した表に変換します。
さらに詳しく知りたい場合は Console(コンソールに)vignette(“dplyr”) と入れるか、こちら を参照してください。上では、一つの表について述べていますが、二つの表の扱い方は、Console(コンソール)に vignette(“two-table”) と入れるか、こちら を参照してください。二つの表の扱いについては、後から説明します。
dplyr を初めて使われる場合には、まず R for data science (2e) Transform を学ばれることをお勧めします。以下も、このサイトに沿った説明をします。
18.1.1 select: 名前とタイプによって、列(変数)を選択
| 補助関数 | 条件 | 例 |
|---|---|---|
| - | 列の除去 | select(iris, -Species) |
| : | 列の範囲 | select(iris, 1:4) |
| contains() | 指定文字列を含 | select(iris, contains(“Width”)) |
| ends_with() | 指定文字列で終わる | select(iris, ends_with(“th”)) |
| matches() | 正規表現に適合 | select(iris, matches(“S”)) |
| num_range() | 末尾の指定数値範囲 | Not applicable with iris |
| one_of() | 指定した名前に含まれる | select(iris, one_of(c(“Sepal.Width”, “Petal.Width”))) |
| starts_with() | 指定文字列で始まる | select(iris, starts_with(“Petal”)) |
「正規表現」という言葉が登場します。検索などでは基本的なものですので、ネット上で調べてください。適切に動作するかを、チェックする、正規表現チェッカーもあります。参照:Wikipedia
18.1.2 filter: 列の値の条件に適合した行の選択
| 論理作用素 | 条件 | 例 |
|---|---|---|
| > | y より大きい x | x > y |
| >= | y 以上の x | x >= y |
| < | y より小さい x | x < y |
| <= | y 以下の x | x <= y |
| == | y と等しい x | x == y |
| != | y と等しくない x | x != y |
| is.na() | 値が NA である x | is.na(x) |
| !is.na() | 値が NA でない x | !is.na(x) |
NA は、not available 値が存在しないという意味です。欠損値のことで、df_wdi などには、たくさん、NA が出てきます。欠損値の扱いも、データサイエンスにおいてはとても大切です。
18.1.3 arrange
arrange() では、選択した列の値によって、行を並び替えます。
注意点すべきは、他の、dplyr の動詞とは異なり、基本的に、グループ化は、無視し、その表全体に適用します。グループ内で並び替えをしたい場合には、グループ化した変数を指定するか、.by_group = TRUE とします。
18.1.4 mutate
新しい列を作成または、既存の列を修正、削除します。
以下は便利な補助関数の例です。Help を参照してください。利用するときに、少しずつ説明していきます。ある程度慣れてきたら、どのようなことができるかを把握しておくことは、助けになります。
+, -, log(), など:通常の数学記号を表します。
dense_rank(),min_rank(),percent_rank(),row_number(),cume_dist(), ntile():rankは、階級、順序を決めます。base::rankもあります。基本的に、同じ値があったときに、どのように順序を決めるかがそれぞれによって異なります。cumsum(),cummean(),cummin(),cummax(),cumany(),cumall(): cum は、cumulative(累計)ですから、cumsumは累計、cummean()は、その値までの平均(小計)、cummin()は、その値までの最小、cummax()その値までの最大、cumany(),cumall()は、Help を参照してください。na_if(),coalesce():na_if(x,y)は、x の中で、y と等しいものは、NA に置き換え、coalesce()は、最初の欠損していない値を返します。
18.1.5 group_by
指定した列の値によって表全体をグループ化した表を作成します。表自体が変形されるわけではありませんから、注意してください。次の、summarize と合わせて利用すると便利です。
18.1.6 summarise または summarize
値の集約 (summarize) または、集計に利用します。グループ化された表の場合には、そのグループごとに、値を集約します。
18.1.6.1 集約のための関数
summarize には、 sum(), max(), や mean() が使われますが、ベクトルに対して定義され、一つの値だけを出力する関数でであれば、なんでも使うことができます。以下は、その例です。それぞれの関数については、Help で調べてください。
特定の値 -
mean(x),median(x),quantile(x, 0.25),min(x),max(x)分布の値 -
sd(x),var(x),IQR(x),mad(x)値の位置 -
first(x),nth(x, 2),last(x)個数 -
n_distinct(x),n()(引数なし:表またはグループのサイズ)論理値の数または割合 -
sum(!is.na(x)), mean(y == 0)
条件文で値を指定することも可能です。
注: quantile(分位数) と quartile(四分位数):分位数はデータセットを任意の個数の等しい部分に分割するための値を示し、四分位数はデータセットを4つの等しい部分に分割するための特定の値。
18.1.7 パイプ(Pipe)%>% |>
pipe in R は、すでに説明してましたが、ここにまとめておきます。
%>% は、tidyverse パッケージで、関数のチェーン化を行うために使用されるパイプ演算子ですが、R 4.1 以降は、|> が、R に組み込まれた、ネイティブなパイプライン演算子になっています。tidyverse を使っているときは、どちらを使うことも可能ですが、|> を使うことをお勧めします。R の versoin を確認するには、コンソール(Console)で、R.Version() または、R.version$version.string とします。
18.1.7.1 備考
パイプを使うコードで、複数行にまたがるときは、
|>の後で、改行してください。次の行に続くことがわかります。実際には、
tidyverseの%>%と、R に組み込まれた|>とは多少異なるようです。こちらの記事をご覧ください。本書では、|>を使いますが、注意が必要な場合は、コメントします。
18.2 例から学ぶ dplyr, I
18.2.1 Data iris
R 起動時に読み込まれる、datasets の中の、iris (あやめのデータ)を使い、いくつかの例を示します。iris は、何もしなくてもそのまま使えますが、もし、下の結果と違う場合には、すでに、iris を使い、変形などをしている可能性がありますから、そのときは、下のコードを実行してください。
df_iris <- datasets::iris確認します。
head(df_iris)
str(df_iris)
#> 'data.frame': 150 obs. of 5 variables:
#> $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
#> $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
#> $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
#> $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
#> $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...df_iris データは、名前のついた5個の変数(列)Sepal.Length, Sepal.Width, Petal.Length, Petal.Width, Species があり、それぞれ、150の値(observations (obs.) 観察値)からなっています。5番目の Species は、三つのレベルのファクター(factor)setosa, versicolor ともう一つ virginica からなっていることがわかります。unique は、ベクトル型の変数(今の場合は、iris の Species という列)の中の異なる値を抽出します。ファクター(factor)は、ある分け方がされているという意味です。いずれ説明します。
unique(df_iris$Species)
#> [1] setosa versicolor virginica
#> Levels: setosa versicolor virginica
18.2.3 select 1 - 第 1, 2, 5 列を抽出
第1列、第2列、第5列を、c(1,2,5) で表しています。列名で指定することもできます。
head(select(df_iris, c(1,2,5))) としてありますから、その最初の6行を表示していますが、新しい変数を割り当ててはいませんから、df_iris 自体は変更されていません。
head(df_iris)第1列、第2列、第5列を選んだものを、あとから使いたいときは、新しい名前をつける必要があります。以下同様ですが、この場合だけ、df_iris125 という名前(object name)をつけておきましょう。
18.2.3.1 パイプ(Pipe) |> を使ったコード
最初の例では head(select(df_iris, c(1,2,5))) としました。head の引数として、 select(df_iris, c(1,2,5)) を使ったからです。しかし、慣れてくると、順番に関数を適用することを表現するには、 パイプを使うのも便利です。パイプでは、直前の出力が次の関数の第一引数として引き継がれるというルールになっています。以下のようになります。
もちろん、select(c(1,2,5)) でも同じ結果が得られます。より、詳しく知りたい場合には、Help に |> と入れて説明を読んでください。
In the following, we use pipes.
18.2.7 filter - 値による抽出
Species の列の値が、virginica であるものだけを抽出します。== とイコールが二つであることと、文字列の場合には、半角の引用符(double quote)でくくります。‘verginica’ でも同じです。(列名に空白や、特殊記号が含まれているときには、back tick と呼ばれる、反対向きの引用符で括ります。あとからその必要が生じたときに説明します。)
filter(df_iris, Species == "virginica")
18.2.8 arrange - 昇順、降順
次の例では、Sepal.Length の値の、昇順(小さい順)にし、同じ値の中では、Spepal.Width の降順(大きい順 (desc は descending order からとったもの)にします。Sepal.Length の値が、4.4 の部分の、Sepal.Width の値をみてください。
18.2.9 mutate - rank(階級)
小さい順に順序付けて新しい列を作成し、その順序で表示します。順序付も様々な種類があります。ここでは、同じ値のときには、同じ階級にしています。下の出力を右の方を見てください。1, 2, 2, 2, 5, … となっています。
18.2.10 group_by and summarize
グループにわけて、グループごとに、平均を求めています。
df_iris |>
group_by(Species) |>
summarize(sl = mean(Sepal.Length), sw = mean(Sepal.Width),
pl = mean(Petal.Length), pw = mean(Petal.Width))- mean:
mean()ormean(x, na.rm = TRUE)- 相加平均 (average) - median:
median(),median(x, na.rm = TRUE)- 中央値(mid value)
以下のリンクには、もう少し例が書かれています。
18.3 dplyr の参考文献
より詳しい説明は、教科書の該当箇所を見てください。
18.3.1 RStudio Primers: 対話型の演習問題
- Work with Data – r4ds: Wrangle, I
18.4 例から学ぶ dplyr, II
18.4.1 df_wdi, df_wdi_extra
前の章の Tidyverse で読み込み、概観した、世界開発指標(World Development Indicators)のデータを使います。参照:WDI のデータ
WDI の使い方は、世界銀行の部分で紹介しますが、はじめてのデータサイエンスの例でも紹介したように、データコードを利用して、データを読み込みます。ここでは、出生時の平均寿命と、一人当たりの GDP と、総人口のデータを使います。
- SP.DYN.LE00.IN: Life expectancy at birth, total (years) 出生時の平均寿命
- SP.POP.TOTL: Population, total 総人口
- NY.GDP.PCAP.KD: GDP per capita (constant 2015 US$) 一人当たりの GDP
次のコードで読み込みます。
df_wdi <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL", gdpPercap = "NY.GDP.PCAP.KD")
)#> Rows: 16758 Columns: 7
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, iso2c, iso3c
#> dbl (4): year, lifeExp, pop, gdpPercap
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_wdi_extra <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL", gdpPercap = "NY.GDP.PCAP.KD"),
extra = TRUE
)すこし、追加情報を付加したものも取得しておきます。
#> Rows: 16758 Columns: 15
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (6): year, lifeExp, pop, gdpPercap, longitude, lati...
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_wdi_extra
18.4.2 ggplot2
また、前の章の Tidyverse の説明で、あやめ(iris)のデータを使って、視覚化の説明を、散布図を使って、少ししました。参照:ggplot2 グラフの描画
詳細は、次の、視覚化のところで説明しますが、視覚化のためには、データの変形、整理が必要であることを、理解していただくために、散布図と、箱ひげ図の基本的な場合のみ、以下のような形式で利用します。
例1 散布図(scatter plot)
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length)) + geom_point()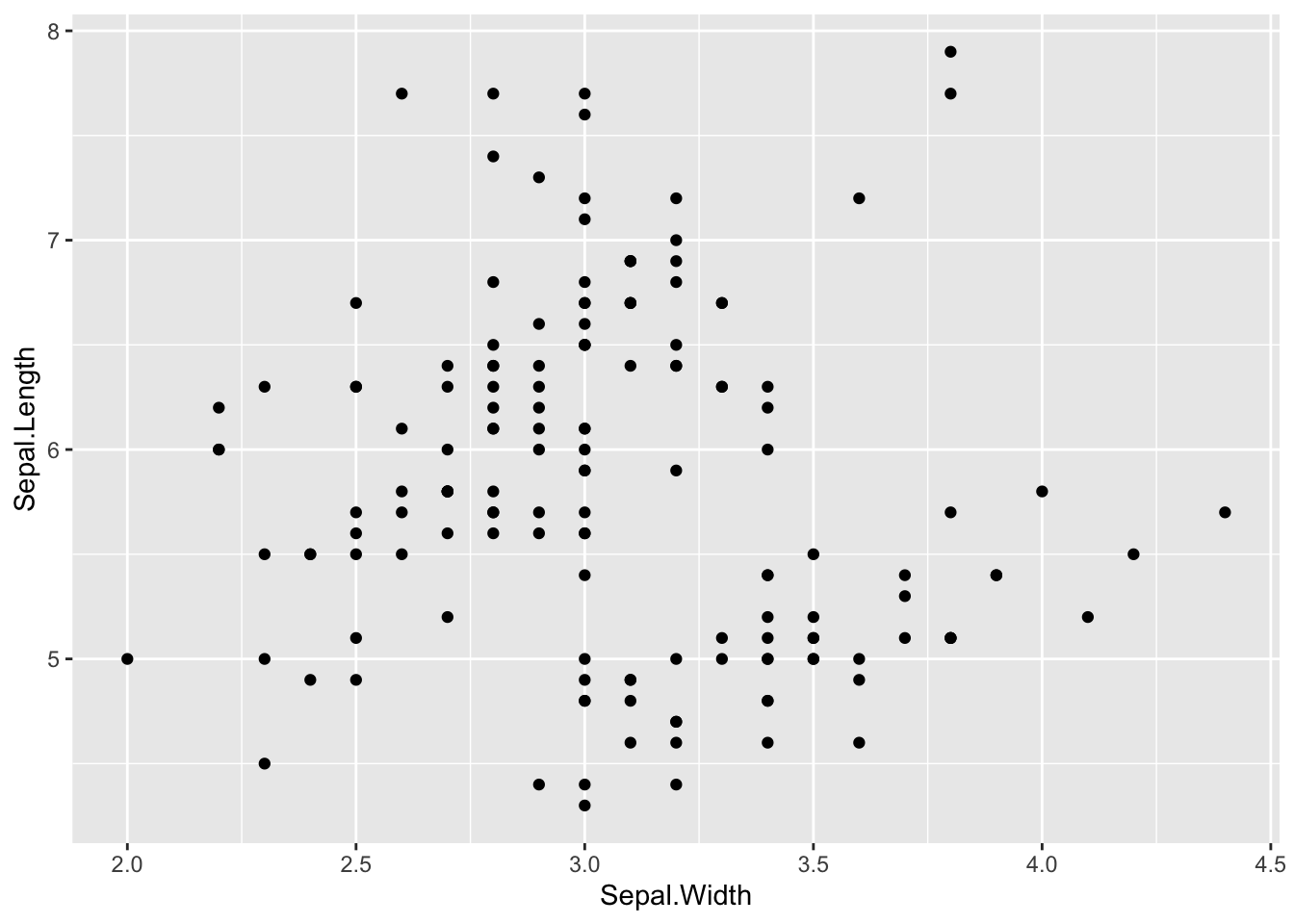
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length, color = Species)) +
geom_point()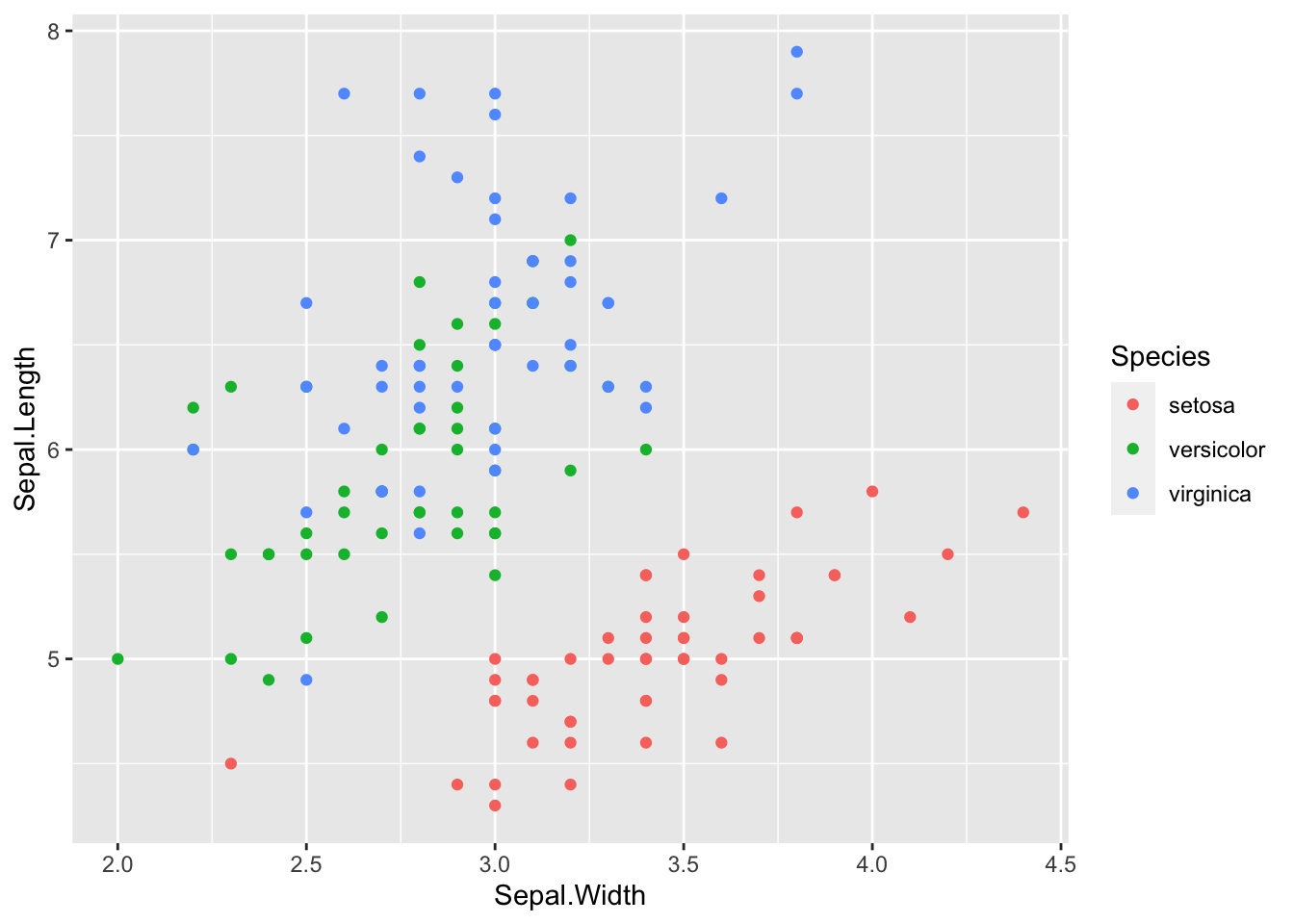
18.4.3 dplyr の応用
すべて、dplyr というわけではありませんが、データを理解していきたいと思います。
二つのデータ df_wdi と df_wdi_extra がありました。この違いをまずは見ていきましょう。colnames は、列名が並んだもの(ベクトル)を出力します。
df_wdi |> colnames()
#> [1] "country" "iso2c" "iso3c" "year"
#> [5] "lifeExp" "pop" "gdpPercap"
df_wdi_extra |> colnames()
#> [1] "country" "iso2c" "iso3c" "year"
#> [5] "status" "lastupdated" "lifeExp" "pop"
#> [9] "gdpPercap" "region" "capital" "longitude"
#> [13] "latitude" "income" "lending"df_wdi_extra の一部が、df_wdi のようです。
ここからは、しばらく、df_wdi_extra をみていきます。range は、最小、最大を見るのに使います。df_wdi_extra$year は、df_wdi_extra の year の列を取り出したもの(ベクトルといいます)です。
range(df_wdi_extra$year)
#> [1] 1960 2022unique を使って、その列で相異なるものをすべてリストすることもできます。
unique(df_wdi_extra$income)
#> [1] "Low income" "Aggregates"
#> [3] "Upper middle income" "Lower middle income"
#> [5] "High income" NA
#> [7] "Not classified"Aggregates とか、Not classified とか、NA は何を表しているのでしょうか。あとで見てみましょう。Google Public Data Explorer を使ったときに、Income Level というものがありました。覚えていますか。
参考:The World by Income and Region
unique(df_wdi_extra$region)
#> [1] "South Asia"
#> [2] "Aggregates"
#> [3] "Europe & Central Asia"
#> [4] "Middle East & North Africa"
#> [5] "East Asia & Pacific"
#> [6] "Sub-Saharan Africa"
#> [7] "Latin America & Caribbean"
#> [8] "North America"
#> [9] NAこれらは、あとで使いますから、残しておきましょう。そこで、country, iso2c, year, liefExp, pop, gdpPercap, income, region だけを取り出します。列を選択するので、select を使います。
df_wdi3 <- df_wdi_extra |> select(country, iso2c, year, lifeExp, pop, gdpPercap, income, region)
df_wdi3何列目かを指定することもできます。今回は少し多いので大変ですが。
df_wdi_extra |> select(1,2,4,7,8,9,10,14)Aggregates は何を意味しているのかみてみましょう。filter で、その行だけを取り出します。
df_wdi3 |> filter(income == "Aggregates")どうも、国ではなく、地域のようです。確認しておきましょう。unique を使って、
unique(filter(df_wdi3, income == "Aggregates")$country)
#> [1] "Africa Eastern and Southern"
#> [2] "Africa Western and Central"
#> [3] "Arab World"
#> [4] "Caribbean small states"
#> [5] "Central Europe and the Baltics"
#> [6] "Early-demographic dividend"
#> [7] "East Asia & Pacific"
#> [8] "East Asia & Pacific (excluding high income)"
#> [9] "East Asia & Pacific (IDA & IBRD countries)"
#> [10] "Euro area"
#> [11] "Europe & Central Asia"
#> [12] "Europe & Central Asia (excluding high income)"
#> [13] "Europe & Central Asia (IDA & IBRD countries)"
#> [14] "European Union"
#> [15] "Fragile and conflict affected situations"
#> [16] "Heavily indebted poor countries (HIPC)"
#> [17] "IBRD only"
#> [18] "IDA & IBRD total"
#> [19] "IDA blend"
#> [20] "IDA only"
#> [21] "IDA total"
#> [22] "Late-demographic dividend"
#> [23] "Latin America & Caribbean (excluding high income)"
#> [24] "Latin America & the Caribbean (IDA & IBRD countries)"
#> [25] "Least developed countries: UN classification"
#> [26] "Low & middle income"
#> [27] "Middle East & North Africa"
#> [28] "Middle East & North Africa (excluding high income)"
#> [29] "Middle East & North Africa (IDA & IBRD countries)"
#> [30] "Middle income"
#> [31] "North America"
#> [32] "OECD members"
#> [33] "Other small states"
#> [34] "Pacific island small states"
#> [35] "Post-demographic dividend"
#> [36] "Pre-demographic dividend"
#> [37] "Small states"
#> [38] "South Asia"
#> [39] "South Asia (IDA & IBRD)"
#> [40] "Sub-Saharan Africa (excluding high income)"
#> [41] "Sub-Saharan Africa (IDA & IBRD countries)"
#> [42] "World"とする手もありますが、パイプを使うときは、そのまま、country で異なるものを取り出した表にした方が簡単なので、distinct を使って、次のようにすることもできます。
unique を使った場合と同じ表示にしたければ、最後に pull() を付け加えて、その列だけを、並べて(ベクトル)表示することも可能です。
df_wdi3 |> filter(income == "Aggregates") |> distinct(country) |> pull()
#> [1] "Africa Eastern and Southern"
#> [2] "Africa Western and Central"
#> [3] "Arab World"
#> [4] "Caribbean small states"
#> [5] "Central Europe and the Baltics"
#> [6] "Early-demographic dividend"
#> [7] "East Asia & Pacific"
#> [8] "East Asia & Pacific (excluding high income)"
#> [9] "East Asia & Pacific (IDA & IBRD countries)"
#> [10] "Euro area"
#> [11] "Europe & Central Asia"
#> [12] "Europe & Central Asia (excluding high income)"
#> [13] "Europe & Central Asia (IDA & IBRD countries)"
#> [14] "European Union"
#> [15] "Fragile and conflict affected situations"
#> [16] "Heavily indebted poor countries (HIPC)"
#> [17] "IBRD only"
#> [18] "IDA & IBRD total"
#> [19] "IDA blend"
#> [20] "IDA only"
#> [21] "IDA total"
#> [22] "Late-demographic dividend"
#> [23] "Latin America & Caribbean (excluding high income)"
#> [24] "Latin America & the Caribbean (IDA & IBRD countries)"
#> [25] "Least developed countries: UN classification"
#> [26] "Low & middle income"
#> [27] "Middle East & North Africa"
#> [28] "Middle East & North Africa (excluding high income)"
#> [29] "Middle East & North Africa (IDA & IBRD countries)"
#> [30] "Middle income"
#> [31] "North America"
#> [32] "OECD members"
#> [33] "Other small states"
#> [34] "Pacific island small states"
#> [35] "Post-demographic dividend"
#> [36] "Pre-demographic dividend"
#> [37] "Small states"
#> [38] "South Asia"
#> [39] "South Asia (IDA & IBRD)"
#> [40] "Sub-Saharan Africa (excluding high income)"
#> [41] "Sub-Saharan Africa (IDA & IBRD countries)"
#> [42] "World"unclassified と、NA もみておきましょう。まず、Aggregates 以外を見たいので、等しくないは、!= を使います。
NA もなくなりましたから、あとは、Not classified ですね。
df_wdi3 |> filter(income != "Aggregates") |>
filter(income == "Not classified") |> distinct(country) ベネズエラ(Venezuela, RB)は、経済が安定していないので、このようになるようです。これは、残しておいて、Aggregates でないものだけ選択しましょう。通常の、country のみですから、df_wdi3c としておきます。
df_wdi3c <- df_wdi3 |> filter(income != "Aggregates")
df_wdi3c散布図を書いてみましょう。
df_wdi3c |> ggplot(aes(gdpPercap, lifeExp)) + geom_point()
#> Warning: Removed 3981 rows containing missing values
#> (`geom_point()`).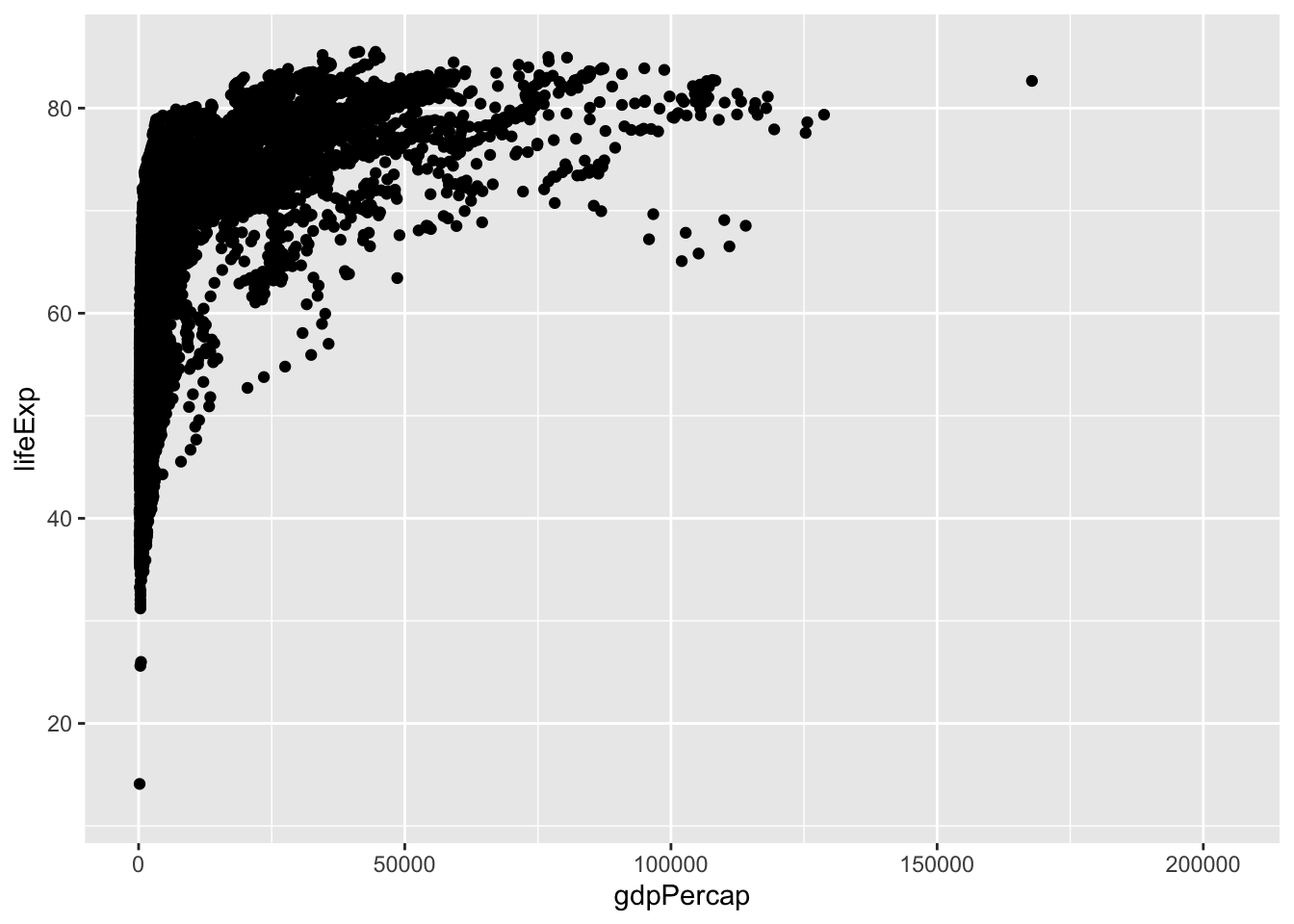
一応、なにか描けましたが、どうも、すごく点の数が多いですね。それと、欠損値もたくさんあるようです。また、gdpPercap でみると、値が小さいところに固まってあるようです。
まずは、すべての年について、値を使っていますから、2022 年に限ってみましょう。
df_wdi3c |> filter(year == "2022") |>
ggplot(aes(gdpPercap, lifeExp)) + geom_point()
#> Warning: Removed 216 rows containing missing values
#> (`geom_point()`).
どうも、何も現れません。2021 年ならどうでしょうか。
df_wdi3c |> filter(year == 2021) |>
ggplot(aes(gdpPercap, lifeExp)) + geom_point()
#> Warning: Removed 23 rows containing missing values
#> (`geom_point()`).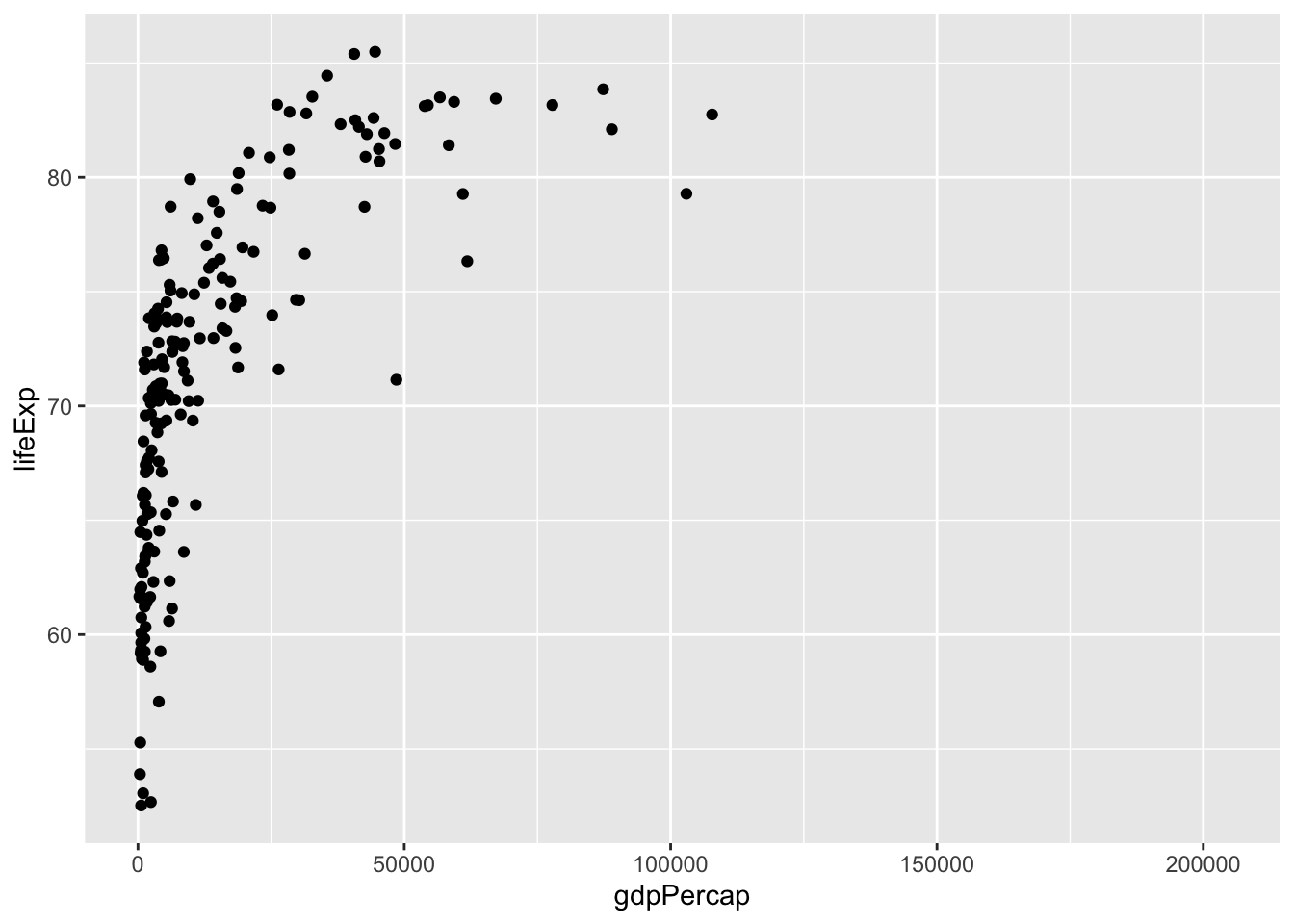
データがない国もあるようですが、どうやら表示されました。データがない国は、削除しておいたり region を 色で表したり、人口を、点の大きさで表したり、gdpPercap を log10 をとって、値を修正して表すなども可能ですが、それは、可視化の項目で学びます。
df_wdi3c |> filter(year == 2021) |> drop_na(lifeExp, gdpPercap) |>
ggplot(aes(gdpPercap, lifeExp, color = region, size = pop)) +
geom_point() + scale_x_log10()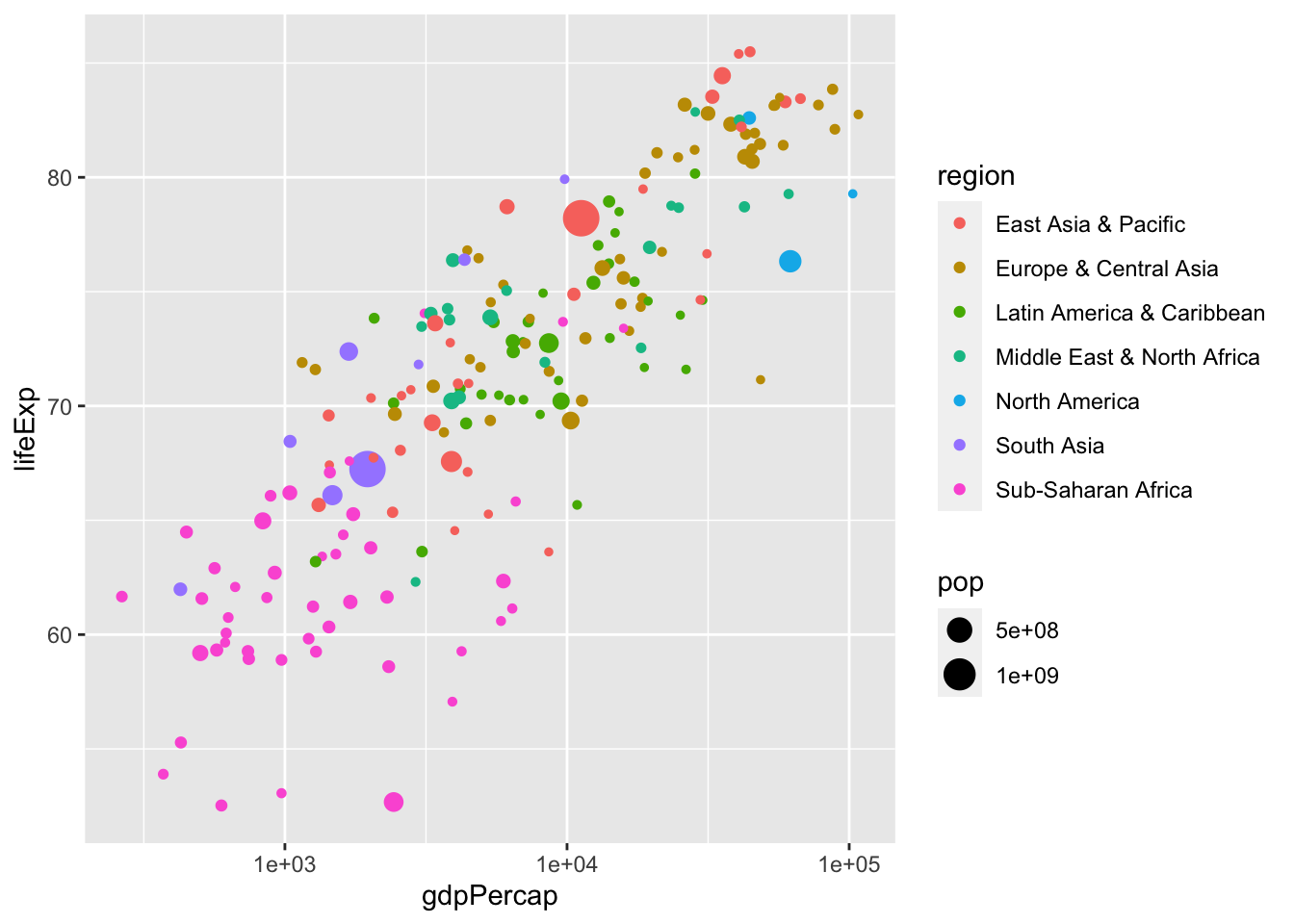
こうしてみると、gdpPercap が大きい国ほど、lifeExp も大きい傾向があることも見えますね。
ここまでは、select と、filter を使ってきましたが、arrange、mutate、group_by や、summarize も使ってみましょう。
まず、gdpPercap は一人当たりの GDP でしたから、この値に、pop 人口をかければ、原理的には、GDP が得られることになります。(さまざまな基準がありますから、詳細は、調べてください。)順番を、入れ替えて、year の次に、gdp がくるようにしておきます。他にも、year の後に置くようにとの指示もできます。Help で確認してください。例も載っています。また、掛け算は、* を使います。これを、df_wdi4c としておきましょう。また、year が順番になっていないのが気になりますから、大きい順に並べ替えておきましょう。
df_wdi4c <- df_wdi3c |> mutate(gdp = pop*gdpPercap) |>
select(1,2,3,9,4,5,6,7,8) |> arrange(country, desc(year))
df_wdi4c2022 年のデータはあまりないようですから、2021 年の GDP の大きい順に並べてみましょう。gdp が 2.052946e+13 などと書かれているのは、指数表示(Scientific Notation)で、e+3 は、1000 千、e+6 は、1,000,000 百万、e+9 は、1,000,000,000 千億、e+12 は、1,000,000,000,000 超です。つまり、アメリカの GDP は、だいたい、20兆ドル、日本は、4.5兆ドルと言ったところです。
地域ごとの平均寿命を求めてみましょう。
df_wdi4c |> drop_na(lifeExp) |>
group_by(region) |> summarize(lifeexpregion = mean(lifeExp)) |>
arrange(desc(lifeexpregion))income でも計算してみましょう。
df_wdi4c |> drop_na(lifeExp) |>
group_by(income) |> summarize(lifeexpincome = mean(lifeExp)) |>
arrange(desc(lifeexpincome))ある年の値がないためにグラフがかけない場合もあります。各指標の年毎のデータがどれぐらいあるかみてみましょう。is.na(x) は、x が NA なら TRUE (値は 1)、x が NA でなければ、FALSE(値は 0)を返します。!is.na(x) はその否定ですから、逆になります。そこで、たとえば、sum(!is.na(gdp)) は、gdp という列(年毎にグループ分けした)の中の、NA ではないものがいくつあるか数えることになります。sum は summation で、合計です。
df_wdi4c |> group_by(year) |>
summarize(gdp_n = sum(!is.na(gdp)), lifeExp_n = sum(!is.na(lifeExp)), pop_n = sum(!is.na(pop)), gdpPercap_n = sum(!is.na(gdpPercap))) |> arrange(desc(year))
18.4.4 filter
一番上に、国名(country)に、アフガニスタン(Afghanistan) がありましたから、aアフガニスタンのデータを選び、平均寿命(lifeExp: Life Expectancy)の折線グラフ(line graph)を描いてみましょう。まずは、filter で、アフガニスタンのデータを抽出します。スペルに注意してください。コピーをするのが安全かもしれません。折れ線グラフ(line graph)を描いてみましょう。まずは、filter で、アフガニスタンのデータを抽出します。スペルに注意してください。コピーをするのが安全かもしれません。
filter(country == "Afghanistan")
特定の値のデータを抽出するには、== を使うのでした。二つの = ですから、間違わないでください。
df_wdi |> filter(country == "Afghanistan")確認できましたか。
折線グラフを書きます。この場合は、GEOM は、geom_line です。
df_wdi |> filter(country == "Afghanistan") |>
ggplot(aes(x = year, y = lifeExp)) + geom_line()
#> Warning: Removed 1 row containing missing values
#> (`geom_line()`).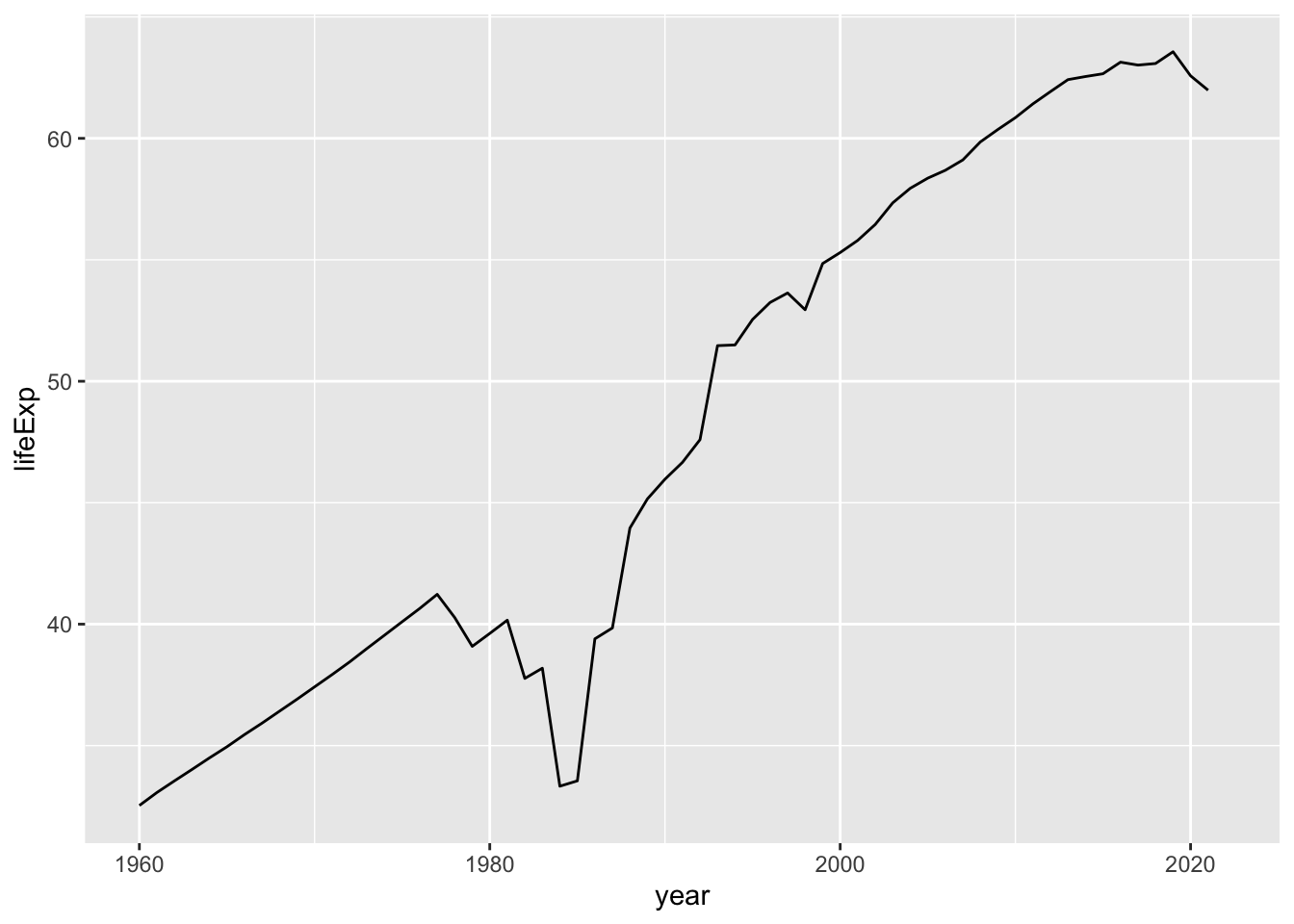
アフガニスタンでは 1952年 の誕生時の平均寿命(life expectancy at birth)は 30歳以下 (28.8歳)でした。2007年でも50歳以下(48.8 歳)のようですね。改善されていることも確かです。
アフガニスタンと日本両方を抽出してみましょう。そのときは、 country %in% c("Afghanistan", "Japan") とします。
グラフにしてみましょう。今度は、区別のため、color = country を追加します。すると、線が違う色で表示されます。詳しくは、視覚化を参照してください。
df_wdi |> filter(country %in% c("Afghanistan", "Japan")) |>
ggplot(aes(x = year, y = lifeExp, color = country)) + geom_line()
#> Warning: Removed 2 rows containing missing values
#> (`geom_line()`).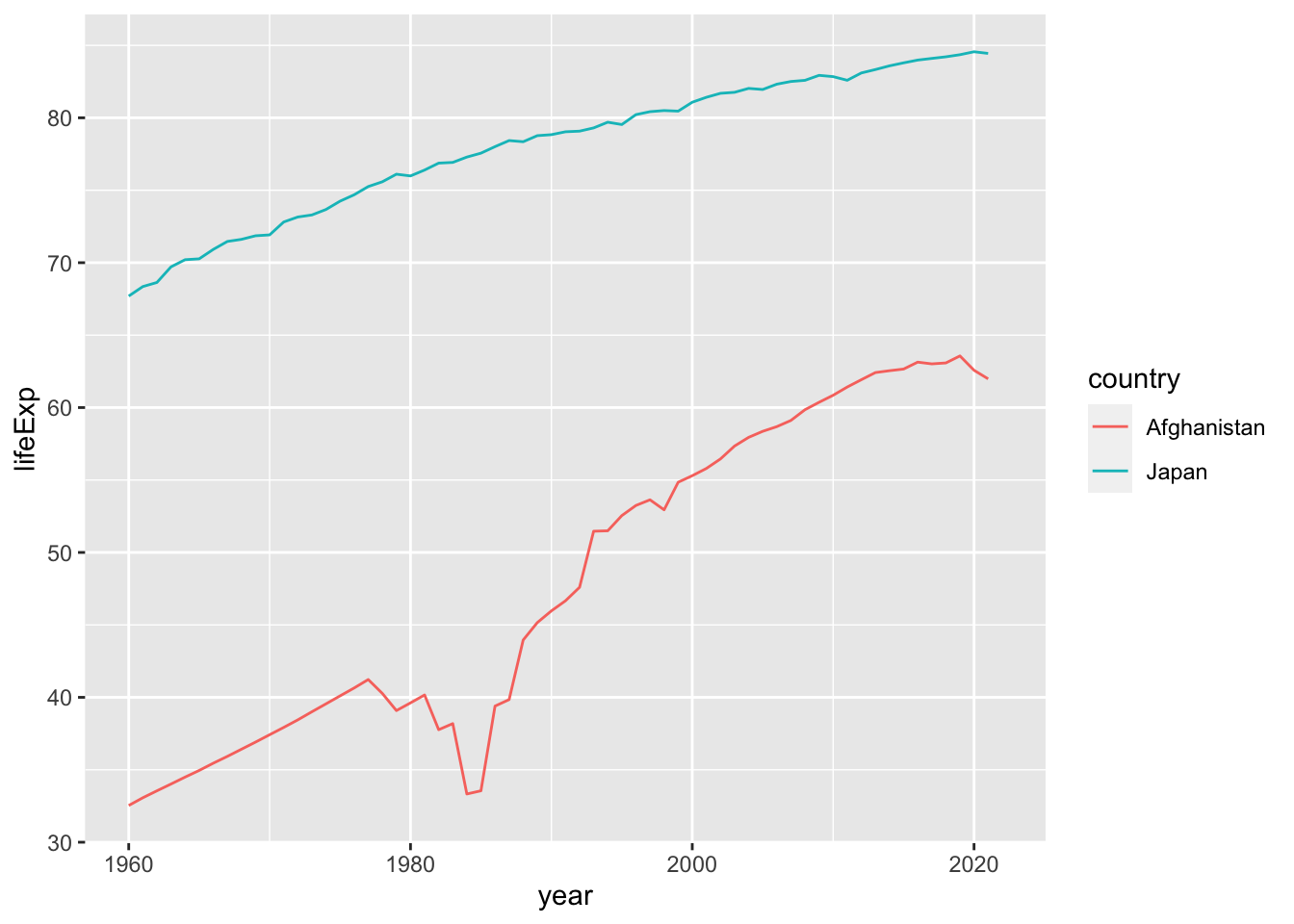
どのような発見がありますか。かならず書き留めておいてください。
他の国についても調べるときは、国のリストがあるとよいので、 unique(df_gm$country) とすると、リストが得られます。distinct(country) で、異なる国を選択してから、その部分をベクトルとして出力することもできます。
df_wdi |> distinct(country) |> pull()
#> [1] "Afghanistan"
#> [2] "Africa Eastern and Southern"
#> [3] "Africa Western and Central"
#> [4] "Albania"
#> [5] "Algeria"
#> [6] "American Samoa"
#> [7] "Andorra"
#> [8] "Angola"
#> [9] "Antigua and Barbuda"
#> [10] "Arab World"
#> [11] "Argentina"
#> [12] "Armenia"
#> [13] "Aruba"
#> [14] "Australia"
#> [15] "Austria"
#> [16] "Azerbaijan"
#> [17] "Bahamas, The"
#> [18] "Bahrain"
#> [19] "Bangladesh"
#> [20] "Barbados"
#> [21] "Belarus"
#> [22] "Belgium"
#> [23] "Belize"
#> [24] "Benin"
#> [25] "Bermuda"
#> [26] "Bhutan"
#> [27] "Bolivia"
#> [28] "Bosnia and Herzegovina"
#> [29] "Botswana"
#> [30] "Brazil"
#> [31] "British Virgin Islands"
#> [32] "Brunei Darussalam"
#> [33] "Bulgaria"
#> [34] "Burkina Faso"
#> [35] "Burundi"
#> [36] "Cabo Verde"
#> [37] "Cambodia"
#> [38] "Cameroon"
#> [39] "Canada"
#> [40] "Caribbean small states"
#> [41] "Cayman Islands"
#> [42] "Central African Republic"
#> [43] "Central Europe and the Baltics"
#> [44] "Chad"
#> [45] "Channel Islands"
#> [46] "Chile"
#> [47] "China"
#> [48] "Colombia"
#> [49] "Comoros"
#> [50] "Congo, Dem. Rep."
#> [51] "Congo, Rep."
#> [52] "Costa Rica"
#> [53] "Cote d'Ivoire"
#> [54] "Croatia"
#> [55] "Cuba"
#> [56] "Curacao"
#> [57] "Cyprus"
#> [58] "Czechia"
#> [59] "Denmark"
#> [60] "Djibouti"
#> [61] "Dominica"
#> [62] "Dominican Republic"
#> [63] "Early-demographic dividend"
#> [64] "East Asia & Pacific"
#> [65] "East Asia & Pacific (excluding high income)"
#> [66] "East Asia & Pacific (IDA & IBRD countries)"
#> [67] "Ecuador"
#> [68] "Egypt, Arab Rep."
#> [69] "El Salvador"
#> [70] "Equatorial Guinea"
#> [71] "Eritrea"
#> [72] "Estonia"
#> [73] "Eswatini"
#> [74] "Ethiopia"
#> [75] "Euro area"
#> [76] "Europe & Central Asia"
#> [77] "Europe & Central Asia (excluding high income)"
#> [78] "Europe & Central Asia (IDA & IBRD countries)"
#> [79] "European Union"
#> [80] "Faroe Islands"
#> [81] "Fiji"
#> [82] "Finland"
#> [83] "Fragile and conflict affected situations"
#> [84] "France"
#> [85] "French Polynesia"
#> [86] "Gabon"
#> [87] "Gambia, The"
#> [88] "Georgia"
#> [89] "Germany"
#> [90] "Ghana"
#> [91] "Gibraltar"
#> [92] "Greece"
#> [93] "Greenland"
#> [94] "Grenada"
#> [95] "Guam"
#> [96] "Guatemala"
#> [97] "Guinea"
#> [98] "Guinea-Bissau"
#> [99] "Guyana"
#> [100] "Haiti"
#> [101] "Heavily indebted poor countries (HIPC)"
#> [102] "High income"
#> [103] "Honduras"
#> [104] "Hong Kong SAR, China"
#> [105] "Hungary"
#> [106] "IBRD only"
#> [107] "Iceland"
#> [108] "IDA & IBRD total"
#> [109] "IDA blend"
#> [110] "IDA only"
#> [111] "IDA total"
#> [112] "India"
#> [113] "Indonesia"
#> [114] "Iran, Islamic Rep."
#> [115] "Iraq"
#> [116] "Ireland"
#> [117] "Isle of Man"
#> [118] "Israel"
#> [119] "Italy"
#> [120] "Jamaica"
#> [121] "Japan"
#> [122] "Jordan"
#> [123] "Kazakhstan"
#> [124] "Kenya"
#> [125] "Kiribati"
#> [126] "Korea, Dem. People's Rep."
#> [127] "Korea, Rep."
#> [128] "Kosovo"
#> [129] "Kuwait"
#> [130] "Kyrgyz Republic"
#> [131] "Lao PDR"
#> [132] "Late-demographic dividend"
#> [133] "Latin America & Caribbean"
#> [134] "Latin America & Caribbean (excluding high income)"
#> [135] "Latin America & the Caribbean (IDA & IBRD countries)"
#> [136] "Latvia"
#> [137] "Least developed countries: UN classification"
#> [138] "Lebanon"
#> [139] "Lesotho"
#> [140] "Liberia"
#> [141] "Libya"
#> [142] "Liechtenstein"
#> [143] "Lithuania"
#> [144] "Low & middle income"
#> [145] "Low income"
#> [146] "Lower middle income"
#> [147] "Luxembourg"
#> [148] "Macao SAR, China"
#> [149] "Madagascar"
#> [150] "Malawi"
#> [151] "Malaysia"
#> [152] "Maldives"
#> [153] "Mali"
#> [154] "Malta"
#> [155] "Marshall Islands"
#> [156] "Mauritania"
#> [157] "Mauritius"
#> [158] "Mexico"
#> [159] "Micronesia, Fed. Sts."
#> [160] "Middle East & North Africa"
#> [161] "Middle East & North Africa (excluding high income)"
#> [162] "Middle East & North Africa (IDA & IBRD countries)"
#> [163] "Middle income"
#> [164] "Moldova"
#> [165] "Monaco"
#> [166] "Mongolia"
#> [167] "Montenegro"
#> [168] "Morocco"
#> [169] "Mozambique"
#> [170] "Myanmar"
#> [171] "Namibia"
#> [172] "Nauru"
#> [173] "Nepal"
#> [174] "Netherlands"
#> [175] "New Caledonia"
#> [176] "New Zealand"
#> [177] "Nicaragua"
#> [178] "Niger"
#> [179] "Nigeria"
#> [180] "North America"
#> [181] "North Macedonia"
#> [182] "Northern Mariana Islands"
#> [183] "Norway"
#> [184] "Not classified"
#> [185] "OECD members"
#> [186] "Oman"
#> [187] "Other small states"
#> [188] "Pacific island small states"
#> [189] "Pakistan"
#> [190] "Palau"
#> [191] "Panama"
#> [192] "Papua New Guinea"
#> [193] "Paraguay"
#> [194] "Peru"
#> [195] "Philippines"
#> [196] "Poland"
#> [197] "Portugal"
#> [198] "Post-demographic dividend"
#> [199] "Pre-demographic dividend"
#> [200] "Puerto Rico"
#> [201] "Qatar"
#> [202] "Romania"
#> [203] "Russian Federation"
#> [204] "Rwanda"
#> [205] "Samoa"
#> [206] "San Marino"
#> [207] "Sao Tome and Principe"
#> [208] "Saudi Arabia"
#> [209] "Senegal"
#> [210] "Serbia"
#> [211] "Seychelles"
#> [212] "Sierra Leone"
#> [213] "Singapore"
#> [214] "Sint Maarten (Dutch part)"
#> [215] "Slovak Republic"
#> [216] "Slovenia"
#> [217] "Small states"
#> [218] "Solomon Islands"
#> [219] "Somalia"
#> [220] "South Africa"
#> [221] "South Asia"
#> [222] "South Asia (IDA & IBRD)"
#> [223] "South Sudan"
#> [224] "Spain"
#> [225] "Sri Lanka"
#> [226] "St. Kitts and Nevis"
#> [227] "St. Lucia"
#> [228] "St. Martin (French part)"
#> [229] "St. Vincent and the Grenadines"
#> [230] "Sub-Saharan Africa"
#> [231] "Sub-Saharan Africa (excluding high income)"
#> [232] "Sub-Saharan Africa (IDA & IBRD countries)"
#> [233] "Sudan"
#> [234] "Suriname"
#> [235] "Sweden"
#> [236] "Switzerland"
#> [237] "Syrian Arab Republic"
#> [238] "Tajikistan"
#> [239] "Tanzania"
#> [240] "Thailand"
#> [241] "Timor-Leste"
#> [242] "Togo"
#> [243] "Tonga"
#> [244] "Trinidad and Tobago"
#> [245] "Tunisia"
#> [246] "Turkiye"
#> [247] "Turkmenistan"
#> [248] "Turks and Caicos Islands"
#> [249] "Tuvalu"
#> [250] "Uganda"
#> [251] "Ukraine"
#> [252] "United Arab Emirates"
#> [253] "United Kingdom"
#> [254] "United States"
#> [255] "Upper middle income"
#> [256] "Uruguay"
#> [257] "Uzbekistan"
#> [258] "Vanuatu"
#> [259] "Venezuela, RB"
#> [260] "Vietnam"
#> [261] "Virgin Islands (U.S.)"
#> [262] "West Bank and Gaza"
#> [263] "World"
#> [264] "Yemen, Rep."
#> [265] "Zambia"
#> [266] "Zimbabwe"このデータには 142 の国のデータがあることがわかりました。
BRICs を選んでみるとどうなるでしょうか。最近は、BRICS として、South Africa を加えることが増えてきているようです。
df_wdi |> filter(country %in% c("Brazil", "Russia", "India", "China")) |>
ggplot(aes(x = year, y = lifeExp, color = country)) + geom_line()
#> Warning: Removed 3 rows containing missing values
#> (`geom_line()`).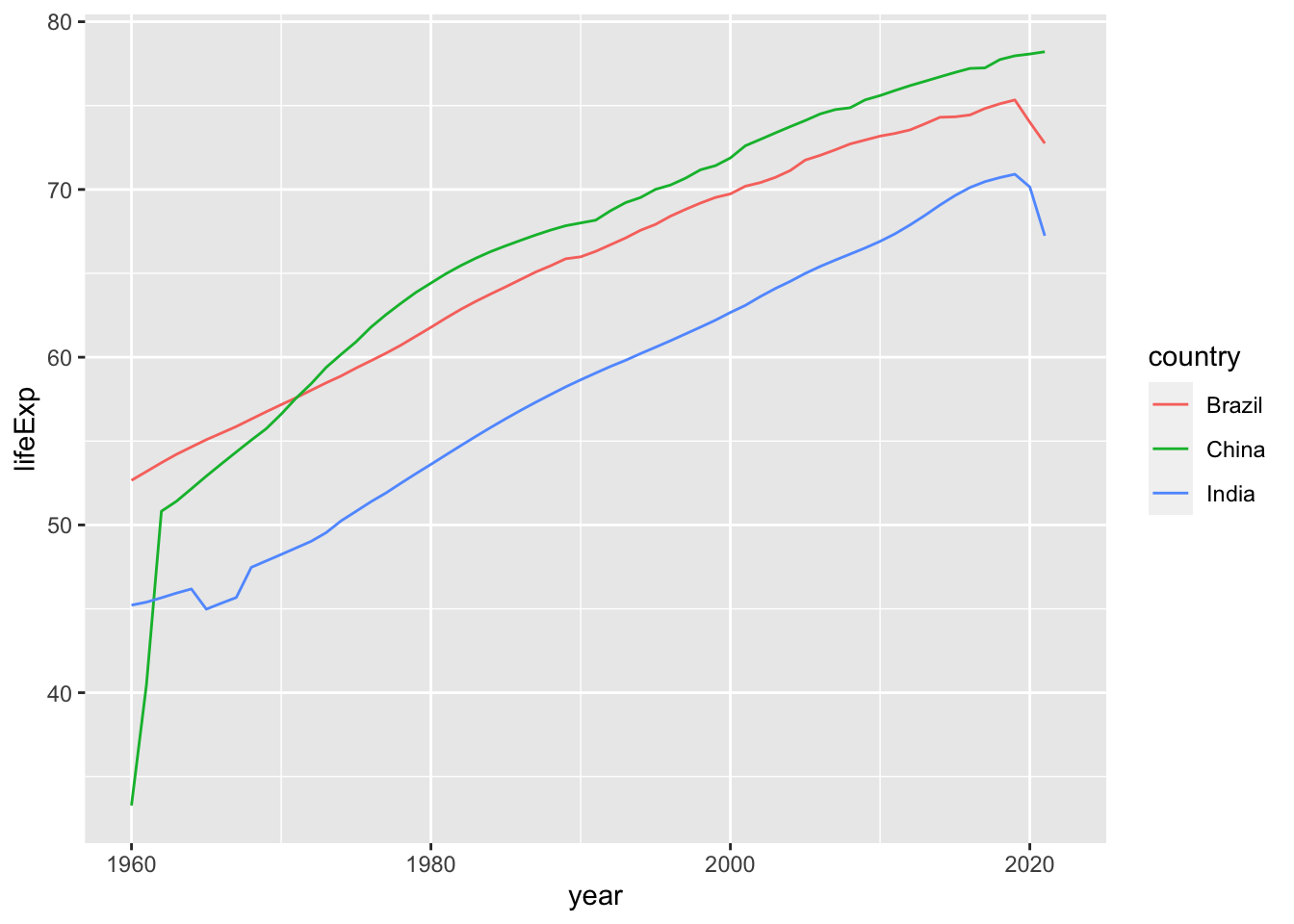
ロシアが含まれていないことがわかります。ロシアは、以前は、ソビエト社会主義連邦でしたから、国が変化したものは含まれていないのかもしれません。上の国のリストで見てもありませんね。2007年より新しいデータ、ロシアなども含むデータなど、実際のデータでも見てみたいですね。それは、また後ほど。
18.4.5 練習
- 平均寿命
lifeExpを人口popや、一人当たりの GDPgdpPercapに変えて、試してみてください。 - ASEAN (東南アジア諸国連合)ではどうでしょうか。
Brunei, Cambodia, Indonesia, Laos, Malaysia, Myanmar, Philippines, Singapore.
このうち幾つの国がこのデータに含まれていますか。
- 興味のある国をいくつか選んで、三つの指標について調べてみてください。
18.4.6 group_by と summarize
データには大陸(continent )という変数があります。幾つの大陸があり、それぞれの大陸のいくつ国のデータがこのデータには入っているでしょうか。
それぞれの大陸ごとの2007年の平均寿命の平均と中央値と最大、最小を求めてみましょう。
df_wdi_extra |> filter(year == 2007) |>
group_by(income) |>
summarize(mean_lifeExp = mean(lifeExp), median_lifeExp = median(lifeExp), max_lifeExp = max(lifeExp), min_lifeExp = min(lifeExp), .groups = "keep")18.5 練習問題
18.5.0.1 Gapminder と R Package gapminder
Gapminder は オラ ロスリング(Ola Rosling) と アンナ ロスリング(Anna Rosling Rönnlund)と ハンス ロスリング(Hans Rosling)が設立した組織です。
ハンス・ロスリング は、FACTFULNESS(ファクトフルネス)10の思い込みを乗り越え、データを基に世界を正しく見る習慣 の著者です。
また、R の gapminder パッケージには、ファクトフルネス にも登場するデータで、Gapminder サイトでも使っているデータの一部を、使いやすい、練習用のデータとして提供しているものです。
-
Gapminder: https://www.gapminder.org
- Test on Top: You are probably wrong about - upgrade your worldview
- Bubble Chart: https://www.gapminder.org/tools/#$chart-type=bubbles&url=v1
- Dallar Street: https://www.gapminder.org/tools/#$chart-type=bubbles&url=v1
- Data: https://www.gapminder.org/data/
-
R Package gapminder by Jennifer Bryan
-
Package Help
?gapminderorgapminderin the search window of Help- The main data frame gapminder has 1704 rows and 6 variables:
- country: factor with 142 levels
- continent: factor with 5 levels
- year: ranges from 1952 to 2007 in increments of 5 years
- lifeExp: life expectancy at birth, in years
- pop: population
- gdpPercap: GDP per capita (US$, inflation-adjusted)
- The main data frame gapminder has 1704 rows and 6 variables:
lifeExp, pop, gdpPercap と三つの指標があります。df_wdi と似ていますね。
なにが同じで、何が違いますか。
練習用のデータですが、df_wdi や、df_wdi_extra でしたようなことを試してみてください。
値は同じでしょうか。
18.6 練習
18.6.1 Posit Primers https://posit.cloud/learn/primers
データの変形:Work with Data – r4ds: Wrangle, I
表の形式 Tibble:Working with Tibbles
dplyr によるデータの抽出:Isolating Data with dplyr
dplyr によるデータの変形:Deriving Information with dplyr