A 日本語の扱いについて
A.1 日本語・中国語・韓国語
文字化けが、起こることが多く、対応が、一定せず、特に、図の表示において、Windows や、macOS や、Linux などの、OS ごとに、フォントが違ったり、それを、図のタイトルなどに、使ったりが、難しかったのですが、どうやら、現在は、どの場合も、次の設定で、解決しているようです。下の例を確認してください。特に、フォントについては、好みも関係しますから、難しいですが、ここでは、どのプラットフォーム(OS)でも、共通に扱えることを中心に書きます。
# showtext を、インストールしていない場合は、一回だけ、右上の三角をクリックして実行
install.packages('showtext')
A.3 列名や、データに日本語
df_iris <- iris
colnames(df_iris) <- c("萼長","萼幅","葉長","葉幅","Species" )
tab <- data.frame(Species = c("setosa", "versicolor", "virginica"),
"種別" = c("ヒオウギアヤメ", "ブルーフラッグ", "バージニカ"))
df_iris <- df_iris %>% left_join(tab, by=c("Species" = "Species")) %>% select(-5)
df_iris %>% slice(1:2)
A.4 kable で表示
knitr::kable(df_iris[1:6, ])| 萼長 | 萼幅 | 葉長 | 葉幅 | 種別 |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | ヒオウギアヤメ |
| 4.9 | 3.0 | 1.4 | 0.2 | ヒオウギアヤメ |
| 4.7 | 3.2 | 1.3 | 0.2 | ヒオウギアヤメ |
| 4.6 | 3.1 | 1.5 | 0.2 | ヒオウギアヤメ |
| 5.0 | 3.6 | 1.4 | 0.2 | ヒオウギアヤメ |
| 5.4 | 3.9 | 1.7 | 0.4 | ヒオウギアヤメ |
A.5 ggplot でグラフを作成
ggplot(df_iris, aes(x = `葉長`, y = `葉幅`, col = `種別`)) +
geom_point() + labs(title = "散布図", x = "葉長", y = "葉幅")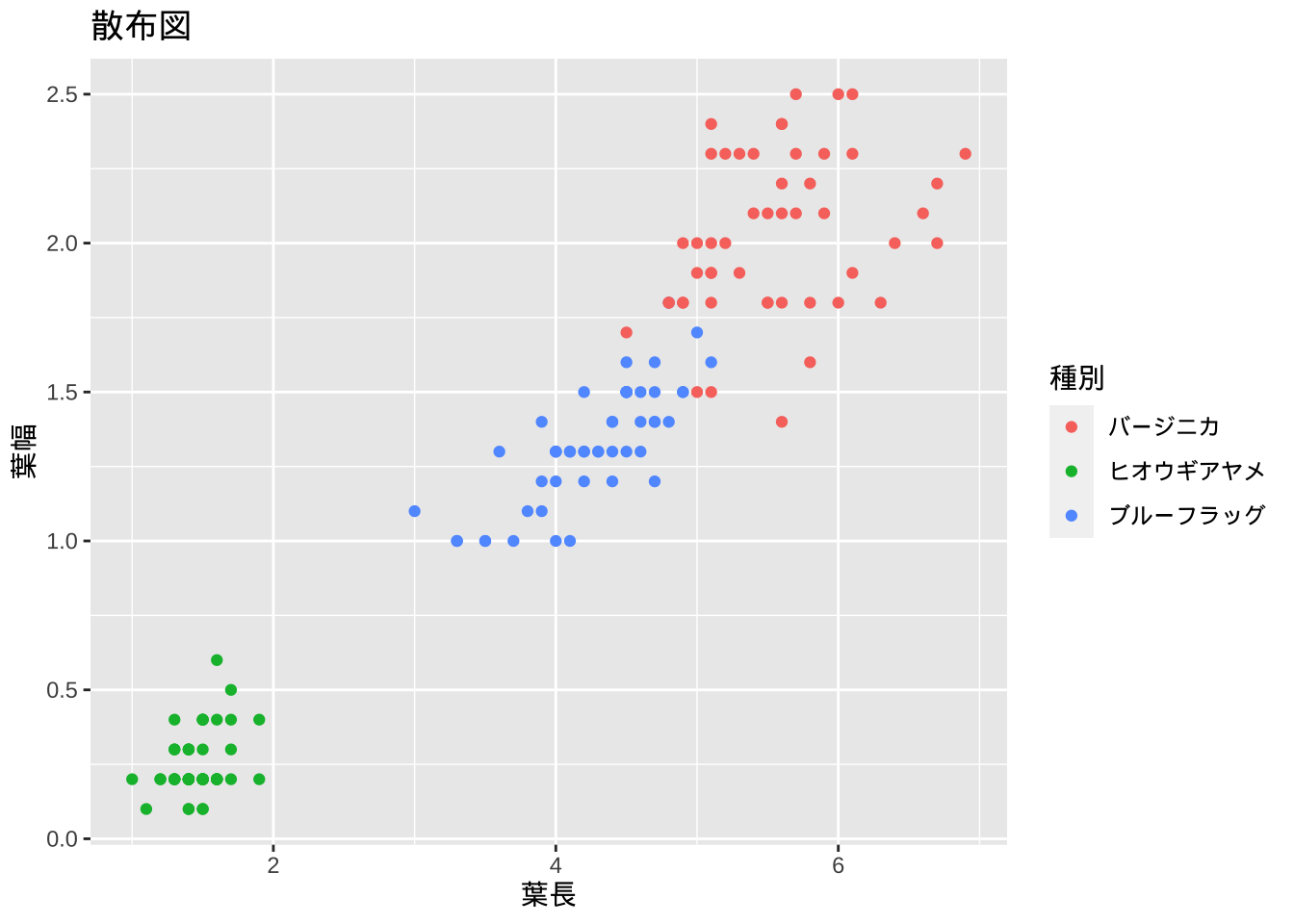
A.6 備考:
実は、一番難しいのが、PDF の作成だと思いますが、一応、上のものも、PDF を作成することが可能です。 下のリンクのファイルを、いろいろな、形式で、出力してみてください。R Notebook と、PDF に出力したもののリンクを付けておきます。
-
R Notebook
- 右上の Code ボタンから、Rmd ファイルも取得できます。
-
R Notebook RMD
- Rmd の中身がテキストで表示されますから、コピーして、新規作成した、RNotebook ファイルに貼り付けることも可能です。
-
PDF
- 通常のPDFも、やはり PDF 形式の、beamer presentation も作成できます。
詳細は、これらのファイルに記載されていますから、参考にしてください。
A.7 参考:日本語の表示について
日本語が適切に表示されない!?
簡単ではなく、未解決の部分が何かなどを含め、わたしも十分理解できているか不明であるが、理解できていると思われる範囲で、備忘録のように記します。
R を使うという場合に限っても、R Studio IDE を使う場合、RStudio Cloud を使う場合、Google colab を使う場合、他のプラットフォームで使う場合で違ってくると思われますが、上にあげた、三種類のプラットフォームで確かめられるものについて書いていく。上に書いた以外に、R Studio IDE を、Windows 上で使う場合と、Mac 上で使う場合(Mac のシステムは Unix 系であるが、さまざまな Linux )でも、状況が異なるかもしれません。そこで、場合分けをして書いていくほうが安全ですが、それは、極力避け、どれにでも適用可能な方法を模索しながら書いていこうと思います。個人的に、日常的に分断を避ける努力をすることが大切だと思っていることも背景にある。さらに、ソフトウェア開発者は、むろん、そのような差異を理解して、どの環境でも、可能なように設計することを心がけていると思われますし、そのようなものが、R Project の正規のパッケージとして採用されていくべきだとも考えていますので、多少、理想も入っているが、これを基本として書いていこうと思います。十分なチェックができていないものもあるので、不具合などは、ぜひ、お知らせ願いたい。この文章も少しずつ、改善していければと思う。
通常、日本語、中国語、韓国語などが適切に表示できない場合は、文字のエンコーディング(Encoding: どのような情報として記録されているか)と、フォントの問題、さらに、システムがこれらをどう処理しているかの問題があると思われます。しかし、R の利用者として考えると、文字化けが起きたり、適切に文字が表示されないのは、以下の三つに分けられるようです。
- データファイルなどを読み込んだときに適切に表示されない
- 図の中のタイトルなどが、適切に表示されない
- R Markdown の出力において、適切に表示されない
A.7.1 データファイルの読み込み
- tidyverse に含まれる readr には、guess_encoding が含まれており、一般的には、たとえば、
- read_csv(“./data/file_name.csv”) とすると、一番可能性の高いエンコーディングで読み込まれるようになっています。
- 使い方:guess_encoding(file, n_max = 10000, threshold = 0.2) とあり、10000行で推測されたエンコーディング、または、確率を計算することを 初期設定値(Default)にしてます。Help によると、すべての行をチェックする場合は、n_max = -1 とすることが書かれています。
- これで問題がない場合が多いです。他の、readr 関数も同様です。しかし、これは、あくまでも、CSV などのテキストファイルについてです。
- なお、read_csv などにも、guess_max = min(1000, n_max) もありますが、これは、column type を決めるためのものである。
- read.csv() など、base R では、fileEncoding = ““, encoding =”unknown” がオプションに含まれていたので、指定して読み込むことが通常でした。
A.7.2 図の中のテキスト
- 基本的には、日本語を表示できるフォントがインストールされていて、図の表示の前にlibrary(showtext); showtext_auto() となっていれば、これ以降の図は、問題なく、表示されるはずです。
- 通常使っている、コンピュータ以外で、使うときに、フォントが入っていない場合などは、
tinytexの命令を使って、tinytex::tlmgr_install("ipaex")とすれば、PDF を作成するときも、IPA フォント(International Phonetic Alphabet)を使えます。 - 二種類以上のフォントを使い分けたいときは、名前をつけて、それを family = name で指定する。
- showtext: Using Fonts More Easily in R Graphs 参照。
A.7.3 R Markdown の出力
- PDF 作成には、システムを使っているので、日本語を扱えるように、tex-engine や、document class や、mainfont を設定する必要があるが、R Markdown ファイルの YAML に、以下を加えれば問題がないようである。
header-includes:
- \usepackage{xeCJK}
- \setCJKmainfont{ipaexm.ttf}
- \setCJKsansfont{ipaexg.ttf}
- \setCJKmonofont{ipaexg.ttf}
A.7.4 bookdown
bookdown を使って、電子書籍を出版する場合には、bookdown (リンク) を参照してください。
日本語におけるテンプレートは、こちら にあります。まずは、ページの下にある、README を読んでください。
A.7.5 参考としたもの
A.7.5.3 foods4all: Examples of Graphs
-
https://foods4all.github.io/examples/examples_of_graphs.html
- 77.2 Japanese Environments 日本語環境(昔の記事:Last Updated: 2020-04-22)