17 Tidyverse
17.1 はじめに
R のはじめかたについて少し説明しました。R を起動させると、最初に base などいくつかのパッケージが自動的に読み込まれますが、その基本の基本を紹介したということです。ここでは、第二部で学ぶことの、核となる tidyverse というパッケージ群についてその基本を学びます。
R は、さまざまな分野で、統計分析に利用されてきたこともあり、それぞれの分析でよく使われる関数(functions, 小さなプログラム)を集めたパッケージが作られ、それぞれの分野で使われてきました。まさに、痒いところに手が届く、さまざまなパッケージが存在します。他方、さまざまな人たちが開発を続けてきたために、統一性がない、保守の継続性が十分ではない、異なるパッケージに同じ名前の関数があるなどの問題も生じてきたように思います。
さらに、それぞれの分野での、統計分析だけではなく、学際分野としてのデータサイエンスでの利用、AI への応用などにも使われるようになったこと、さらに、データサイエンスでは、特に可視化が重要ですが、その部分の基本が、幾何表現の文法、または、描画の原理(Grammar of Graphics)の理論に則って設計された ggplot2 パッケージによって、確立し、それを中心に、統一した思想のもとで、構築されたのが、tidyverse パッケージ群です。さまざまな改善によって、R は、プログラミング言語としても、十分なレベルの言語となっていると思います。
一連の tidyverse パッケージ群の開発が、R 自体にも影響を与え、R の起動時に読み込まれるようになったものもあります。
パッケージ群と呼びましたが、たくさんのパッケージが全体として、tidyverse と呼ばれ、tidyverse をインストールすると、tidyverse パッケージ群のパッケージがすべてインストールされます。
それを、library(tidyverse) などで、ロード(使えるようにするために)すると、tidyverse パッケージ群の主要なパッケージがみな、読み込まれます。ただ、こちらは、「主要な」ものだけですので、tidyverse パッケージ群 のパッケージでも、後ほど、個別に読み込む必要があるものもありますので、注意してください。
17.2 あやめ(iris)のデータ
利用するデータ、特に、その変数(列)名に日本語(中国語・韓国語など)を使う場合には、install.packages('showtext') で、showtext パッケージをインストールして、下のように設定ます。標準的には、最初の行 library(tidyverse) だけで十分です。
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(showtext)
#> Loading required package: sysfonts
#> Loading required package: showtextdb
showtext_auto()いろいろなメッセージが表示されました。簡単に説明しておきます。
Attaching core tidyverse packages:パッケージを読み込む、使えるようにするのが、library() という、命令ですが、ここでは、たくさんのパッケージが読み込まれたことが書かれています。Tidyverse パッケージ群の中の核となるパッケージです(core tidyverse packages)。実は、これ以外にも、Tidyverse パッケージ群は、パッケージを含んでいますが、それは、別に、読み込まないといけません。その都度説明します。
Conflicts:実は、違うパッケージの中に、同じ名前の関数(命令)が含まれている場合があります。その場合は、あとから読み込んだパッケージの命令が優先されます。いま、tidyverse を読み込んだので、その前に、読み込まれていたパッケージのいくつかの、関数が使えなくなりましたというメッセージです。
次に、showtext を読み込んでいます。そこでは、sysfonts と showtextdb も必要なので、読み込んだと書かれています。
以下では、R の起動時に読み込まれる、 datasets パッケージの中の、iris データを使います。以前には、同じパッケージに含まれる、cars を使いました。まず、このデータに、ds_iris という名前をつけて使うことにします。これは、アサインと言い、<- を使います。半角で入力します。
備考:
- Help の Keyboard Shortcuts Help をみると、さまざまなキーボードショートカットが書かれています。
<-は、Windows では、Alt + -、Mac では、Option + -で、入力することもできます。Alt + -などは、Altキーを推しながら、-キーを押すという意味です。 -
df_iris <- irisでも問題ないと思います。下にようにするのは、すでに、irisという変数を使っているかもしれないので、datasetsパッケージのirisを使うという意味です。
あやめのデータ iris は data.frame というクラスであることがわかります。tidyverse には、tibble というデータのクラス(data.frame のサブクラス)もあります。
df_iris と tbl_iris で出力が変わる場合もありますが、今のところは、あまり気にせず、df_iris を使っていきたいと思います。
17.2.1 データを見てみよう
17.2.1.1 復習
すでに、いくつかの関数を学んでいますから、それを使ってみてみましょう。head, str, summary でした。
17.2.1.1.2 str : データの構造(structure)
str(df_iris)
#> 'data.frame': 150 obs. of 5 variables:
#> $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
#> $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
#> $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
#> $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
#> $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...全体の構造(structure)の概略が表示されました。5つの変数、Sepal.Lengh(萼(がく)長), Sepal.Width(萼幅), Petal.Length(花弁長), Petal.Width(花弁幅), Species(種別) について、150 の データ(observations)が含まれており、Species は、三つの Factor になっているということがわかります。Factor については、後ほど学びますが、三つに分類されているという意味で、ここでは、あやめの種類、setosa, versicolor, virginica となっています。三つ目は見えていないかもしれません。
次の、summary() を使うと、Species の三種類がなにかわかりますが、unique() という関数を使って、みてみましょう。df_iris の Species に対応する列は、df_iris$Species で取り出せますので、次のようにします。Level と書いてあるのは、Factor という形式になっているので、その順序が書かれています。この場合は、アルファベットの順序になっています。
unique(df_iris$Species)
#> [1] setosa versicolor virginica
#> Levels: setosa versicolor virginica
17.2.1.1.3 summary: データの概要
summary(df_iris)
#> Sepal.Length Sepal.Width Petal.Length
#> Min. :4.300 Min. :2.000 Min. :1.000
#> 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600
#> Median :5.800 Median :3.000 Median :4.350
#> Mean :5.843 Mean :3.057 Mean :3.758
#> 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100
#> Max. :7.900 Max. :4.400 Max. :6.900
#> Petal.Width Species
#> Min. :0.100 setosa :50
#> 1st Qu.:0.300 versicolor:50
#> Median :1.300 virginica :50
#> Mean :1.199
#> 3rd Qu.:1.800
#> Max. :2.500それぞれの最小値(Min. Minimum)、第一四分位(1st Qu. First Quartile 小さい方から、4分の1を切り捨てたときの最小の値)、中央値(Median)、平均(Mean)、第三四分位(3rd Qu. Third Quartile、大きい方から、4分の1を切り捨てたときの最大の値)最大値(Max. Maximum)が、書かれており、各種それぞれ50個のデータからなっていることがわかります。
base R では、さらに、plot、View、help についても学びました。
これは、あやめ(iris)の、長さや幅のデータでしたが、単位は何でしょうか。それも、help で調べることができます。Help の検索ボックスに、iris と入れてみてください。この場合は、Description(概要)に次のように書かれています。
This famous (Fisher’s or Anderson’s) iris data set gives the measurements in centimeters of the variables sepal length and width and petal length and width, respectively, for 50 flowers from each of 3 species of iris. The species are Iris setosa, versicolor, and virginica.
この有名な(フィッシャーまたはアンダーソンの)あやめのデータは、3種のあやめからそれぞれ50個の花について、萼片の長さと幅、花弁の長さと幅の変数をそれぞれセンチメートル単位で測定したものです。種は、Iris setosa, versicolor, virginica です。
各、変数の説明が書かれている場合もありますので、Help は、かならず確認するようにしてください。
17.2.1.1.4 plot: 散布図
plot(df_iris$Sepal.Width, df_iris$Sepal.Length)
何を x 軸、何を y 軸 の値とするかを指定します。それは、df_iris$Sepal.Width で、df_iris の、Sepal.Width の列、df_iris$Sepal.Length で、df_iris の Sepal.Length の列の値を指定しています。
17.2.1.1.5 View: データテーブルの表示
View(df_iris)View(df_iris) を、Console に入れると、データテーブルが開きます。順番の並び替えもできるようになっています。
R Studio では、右上の窓に、Environment タブがありますが、そこに、df_iris があると思いますから、それを、クリックすると、同じ、データテーブルが表示されます。
17.2.1.1.6 help: ヘルプ
help(iris)help(iris) を、Console に入れるか、または、右下の窓枠の Help に、iris と入れると、説明などが出ます。
ここまでは、tidyverse を使わずにもできることですが、これからは、tidyverse の関数を紹介していきます。
17.2.2 dplyr 変形
ここでは、head と、str に対応する、二種類の関数を紹介するにとどめますが、次の、章の中心的トピックです。
17.2.2.1 slice: 行を切り取る
head を一般化したものです。slice, slice_head, slice_tail, slice_max, slice_min, slice_sample とあります。
df_iris |> slice(1:10)|> は、パイプ(pipe)コマンドと言われるもので、tidyverse では、%>% もほぼ同じ機能ですが、R 4.0 以降には、含まれていますので、tidyverse なしでも使えますから、こちらを使うようにします。最初の 10 行を切り出すという意味で、パイプを使わないときは、一つ前のものが、最初の 変数(argument)となりますから、下のものでも同じです。
slice(df_iris, 1:10)
1:10
#> [1] 1 2 3 4 5 6 7 8 9 101から10のベクトルです。ということは、1:10 の部分をいろいろと変えれば、さまざまな部分を取り出すことができます。詳細は、Help 検索窓で、で、slice と調べてください。下も同じ結果を出力します。
df_iris |> slice_head(n=10)
df_iris |> slice_max(order_by = Sepal.Length, n=7)Sepal.Length の値を大きい方から順に並べて、最初の7つを選択するというものです。
17.2.2.2 glimpse: データの構造
str の改良版です。他の、tidyverse の関数と一緒に使うこともできます。
glimpse(df_iris)
#> Rows: 150
#> Columns: 5
#> $ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.…
#> $ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.…
#> $ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.…
#> $ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.…
#> $ Species <fct> setosa, setosa, setosa, setosa, setos…
df_iris |> glimpse()
#> Rows: 150
#> Columns: 5
#> $ Sepal.Length <dbl> 5.1, 4.9, 4.7, 4.6, 5.0, 5.4, 4.6, 5.…
#> $ Sepal.Width <dbl> 3.5, 3.0, 3.2, 3.1, 3.6, 3.9, 3.4, 3.…
#> $ Petal.Length <dbl> 1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, 1.…
#> $ Petal.Width <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.4, 0.3, 0.…
#> $ Species <fct> setosa, setosa, setosa, setosa, setos…str(df_iris) では num (数値データ)と表示されましたが、ここでは、もう少し詳R の 6個のデータタイプ Double(連続データ), Integer(整数値データ), Character(文字データ), Logical(論理値データ), Raw(素データ), Complex(複素数データ) が表示されます。最初の四種類が主要なものと考えてください。
データの列を指定するときは、データ名のあとに、ドルマークをつけ、列名を加えます。df_iris$Sepal.Width などです。 これは、一列目ですから、 typeof(df_iris[[1]]) とすることもできます。2行目の1列目というときは、次のようにします。
df_iris[2,1] = 4.9 is the fourth entry of Sepal.Width.
typeof(df_iris$Sepal.Width)
#> [1] "double"
typeof(df_iris$Species)
#> [1] "integer"
class(df_iris$Species)
#> [1] "factor"ファクター factors = fct については the R Document または、Factor in R: Categorical Variable & Continuous Variables をみてください。必要になったときに、説明します。
17.2.2.3 ggplot2: グラフの描画
plot の拡張ですが、tidyverse パッケージ群の核をなすものでもあります。詳細は、視覚化で扱います。
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length)) + geom_point()
さまざまな描画が可能ですが、一番、一般的な、散布図、plot に対応するものを書きました。ggplot の中の、aes (aesthetic)の部分に、x 軸、y 軸に対応する変数(列名)を書きます。種類(Species)ごとに色を変える場合には、color = Species とします。
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length, color = Species)) +
geom_point()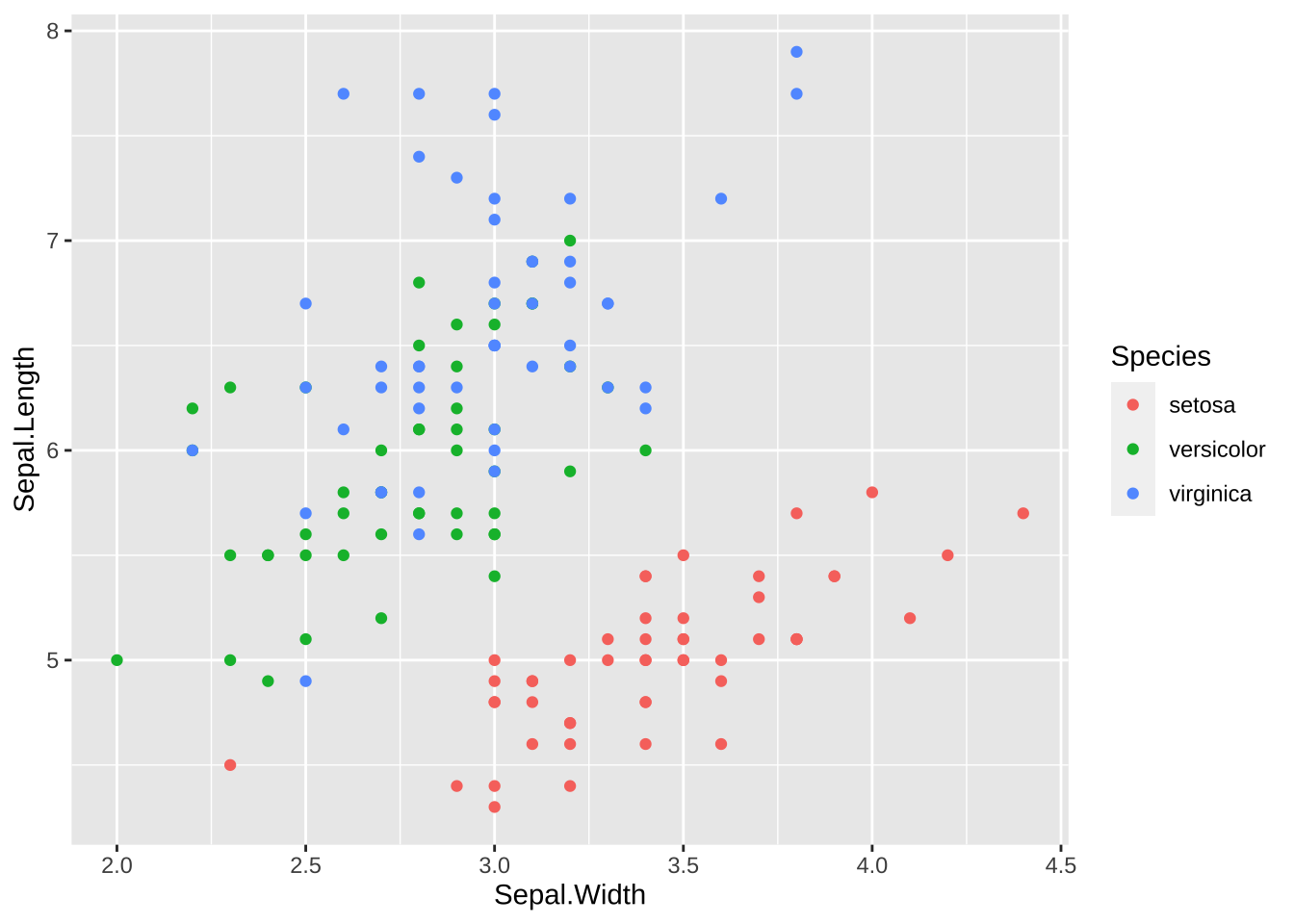
さらに、点の大きさを、Petal.Width によって変える場合には次のように、size = Petal.Width を加えます。
df_iris |>
ggplot(aes(Sepal.Width, Sepal.Length, color = Species,
size = Petal.Width)) +
geom_point()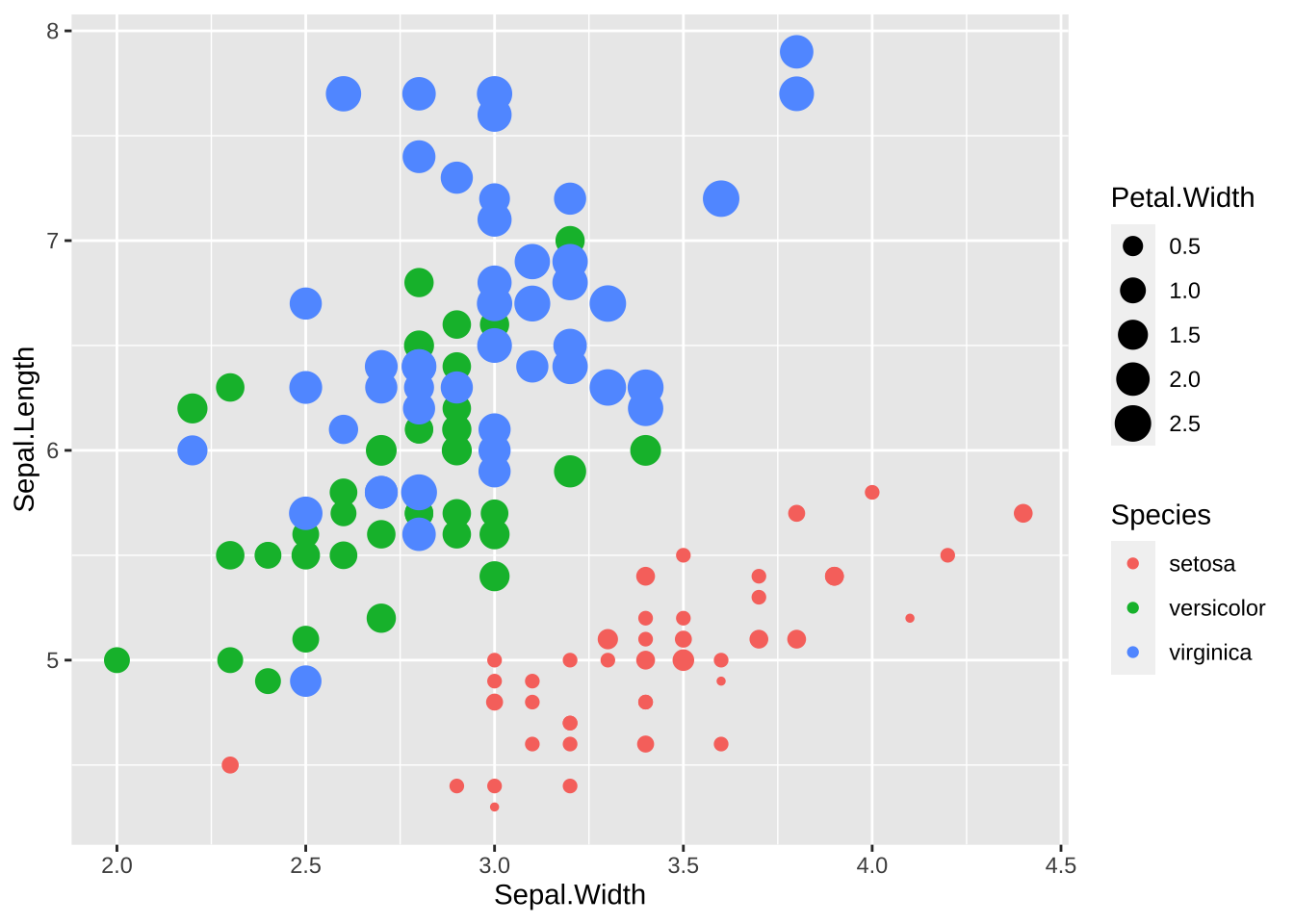
少しずつ学んでいきましょう。
17.3 WDI のデータ
以下の説明では、世界開発指標(World Development Indicator)の実際のデータも使って説明していきます。例として使うデータを取得して、上で学んだことの復習もかねて、簡単にみておきたいと思います。
すでに、tidyverse は読み込んでありますから、その場合は、WDI パッケージを読み込むだけで十分です。
WDI の使い方は、世界銀行の部分で紹介しますが、はじめてのデータサイエンスの例でも紹介したように、データコードを利用して、データを読み込みます。ここでは、出生時の平均寿命と、一人当たりの GDP と、総人口のデータを使います。
- SP.DYN.LE00.IN: Life expectancy at birth, total (years) 出生時の平均寿命
- SP.POP.TOTL: Population, total 総人口
- NY.GDP.PCAP.KD: GDP per capita (constant 2015 US$) 一人当たりの GDP
次のコードで読み込みます。
df_wdi <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL", gdpPercap = "NY.GDP.PCAP.KD")
)#> Rows: 16758 Columns: 7
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, iso2c, iso3c
#> dbl (4): year, lifeExp, pop, gdpPercap
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.注:WDI のサイトは、頻繁に、保守をしているため、時々、データをダウンロードできないことがあります。そのときは、すでに、ダウンロードしてものがわたしの GitHub サイトにありますから、そこから次のコードで読み込んでください。
最初の10行をみてみましょう。
df_wdi_extra <- WDI(
country = "all",
indicator = c(lifeExp = "SP.DYN.LE00.IN", pop = "SP.POP.TOTL", gdpPercap = "NY.GDP.PCAP.KD"),
extra = TRUE
)すこし、追加情報を付加したものも取得しておきます。
#> Rows: 16758 Columns: 15
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (7): country, iso2c, iso3c, region, capital, income...
#> dbl (6): year, lifeExp, pop, gdpPercap, longitude, lati...
#> lgl (1): status
#> date (1): lastupdated
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
df_wdi_extra違いはわかりましたか。同じような変数についてのデータですが、WDI からダウンロードした実際のデータの場合には、練習用のデータとは、違った困難がいくつもあります。それを、少しず見ていきながら、現実世界のデータを扱えるようにしていきましょう。
実は表示の仕方も違っています。今回は、slice(1:10) を使っていません。下の数のところを選択すると、10個ずつ二ページ目、三ページ目と、みていくことができます。これは、HTML 形式で、df_print: paged というオプションを使っているからで、この文書では、これを初期設定に入れてあります。glimpse の出力をみると、16758行あることが、わかり、この表示でも、1000ページ、つまり、10000行しか表示されませんから、全てではありません。しかし、10行ずつ見るよりは、いろいろと調べられますね。実は、メモリーは使うのですが。
glimpse を使ってみてるとどのような違いがわかりますか。
df_wdi |> glimpse()
#> Rows: 16,758
#> Columns: 7
#> $ country <chr> "Afghanistan", "Afghanistan", "Afghanist…
#> $ iso2c <chr> "AF", "AF", "AF", "AF", "AF", "AF", "AF"…
#> $ iso3c <chr> "AFG", "AFG", "AFG", "AFG", "AFG", "AFG"…
#> $ year <dbl> 1960, 1961, 1962, 1963, 1964, 1965, 1966…
#> $ lifeExp <dbl> 32.535, 33.068, 33.547, 34.016, 34.494, …
#> $ pop <dbl> 8622466, 8790140, 8969047, 9157465, 9355…
#> $ gdpPercap <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, …
df_wdi_extra |> glimpse()
#> Rows: 16,758
#> Columns: 15
#> $ country <chr> "Afghanistan", "Afghanistan", "Afghani…
#> $ iso2c <chr> "AF", "AF", "AF", "AF", "AF", "AF", "A…
#> $ iso3c <chr> "AFG", "AFG", "AFG", "AFG", "AFG", "AF…
#> $ year <dbl> 2014, 2012, 2009, 2013, 1971, 2015, 19…
#> $ status <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
#> $ lastupdated <date> 2023-09-19, 2023-09-19, 2023-09-19, 2…
#> $ lifeExp <dbl> 62.545, 61.923, 60.364, 62.417, 37.923…
#> $ pop <dbl> 32716210, 30466479, 27385307, 31541209…
#> $ gdpPercap <dbl> 602.5166, 596.4424, 512.4090, 608.3863…
#> $ region <chr> "South Asia", "South Asia", "South Asi…
#> $ capital <chr> "Kabul", "Kabul", "Kabul", "Kabul", "K…
#> $ longitude <dbl> 69.1761, 69.1761, 69.1761, 69.1761, 69…
#> $ latitude <dbl> 34.5228, 34.5228, 34.5228, 34.5228, 34…
#> $ income <chr> "Low income", "Low income", "Low incom…
#> $ lending <chr> "IDA", "IDA", "IDA", "IDA", "IDA", "ID…列の数が違いますね。どちらも行は、16,758行です。こんなに多いものは、表で見ていても、よくわかりません。これらを扱う方法を少しずつ学んでいきます。
RStudio の右上の窓の Environment から、df_wdi や、df_wdi_extra を選択して、データを表示してみてください。それぞれの列(変数)の右の二つの三角を押すと、昇順(小さい順)、降順(大きい順)に並び替えることもできますし、Filter を使うと、検索も可能です。たとえば、Japan や、JP や、JPN などと検索窓に入れて、日本のデータを表示させてみてください。h表示させてから、Year 列の右の二つの三角を押して、順序をかえてみてください。それぞれの変数何年からのデータがありますか。
17.4 メモ
引数(augument)について
関数の中に指定するものを引数と言います。たとえば、
head(df_iris)のdf_iris、WDI() の () の中の、country や、indicator、ggplot() の () の中の、aes や、color や size などです。Help を一つ一つ見てみるのが良いのですが、引数に名前がついている場合と、ついていない場合があります。三通りがあります。
引数の要・不要
引数の名前がある場合の名前の省略
引数の順序
すべて Help を見ないとわかりませんが、原則は、以下のとおりです。
引数が必要であっても、その初期値(default value)が決まっていて、変更の必要がなければ、引数を指定する必要なし。
引数の名前がある場合であっても、引数の順序どおりであれば、名前は省略可能。
引数には順序があるが、名前のついている引数は、名前をつければ、順序を変更しても構わない。
例で見ていきましょう。
head(df_iris) は、Help には、head(x, …) と書いてあり、x は object と書いてありますから、この場合は、df_iris が x に対応します。… は、任意で、詳細は Help の下の方に書いてあります。さらに見ると、ftable(表 S3: flat contingency table)の場合には、head(x, n = 6L, …) とあります。最初の6行を取り出すという意味です。
n=6L(6L は整数値で 6 の意味)は、6L が初期値ですから、書く必要はありませんが、もし、6を他の数字、たとえば 10 に変えれば、10行ということになります。L の部分は、なくても自然数(1,2, 3, …)なら普通に理解してくれます。head(df_iris, n=-145)とすると何が表示されるでしょうか。-
WDI(country = “all”, indicator = c(lifeExp = “SP.DYN.LE00.IN”, pop = “SP.POP.TOTL”, gdpPercap = “NY.GDP.PCAP.KD”) はどうでしょうか。Help を見てみると、次のようにあります。
WDI( country = "all", indicator = "NY.GDP.PCAP.KD", start = 1960, end = NULL, extra = FALSE, cache = NULL, latest = NULL, language = "en" )最初の引数は、country で初期値は “all”、indicator は、初期値は “NY.GDP.PCAP.KD” ですが、それを、
c()を使ったベクトル表示で与えています。country = “all” は初期値と同じですから、省略可能です。二番目の引数は、indicator ですから、country = “all” を書いてあれば、“indicator =” の部分は省略可能です。
extra = FALSEとありますから、この場合は、何も指定しませんでしたが、df_wdi_extra の場合には、extra = TRUE としました。
-
df_iris |> ggplot(aes(Sepal.Width, Sepal.Length, color = Species, size = Petal.Width)) はどうでしょうか。Help を見ると下のようにありますが、Details の部分も書いておきます。これは、他のパターンもあります。
ggplot(data = NULL, mapping = aes(), ..., environment = parent.frame()) ggplot(data = df, mapping = aes(x, y, other aesthetics))data の部分は、pipe (|>)で、最初に引数に
data = df_irisとあるのと同じです。二番目の引数が、aes の部分ですから、
mapping =は省略しても問題ありません。aes() の中身は、最初が、x、次が y となっていますから、変数の順番があっていれば、x = Sepal.Width, y = Sepal.Length と書いても、書かなくても同じです。
color = Species, size = Petal.Width の部分は、引数名が書かれているので、順番は、関係ありません。
慣れが必要ですから、原則を確認して、あとは、出てきたときに、一つ一つ確認してください。
17.5 練習
17.5.1 Posit Primers https://posit.cloud/learn/primers
R と Tidyverse の基礎:The Basics – r4ds: Explore, I
視覚化の基礎:Visualization Basics
プログラミング基礎:Programming Basics
17.6 まとめ
あやめ(iris)のデータを、df_iris として、読み込み、WDI パッケージを用いて、WDI のデータを df_wdi および df_wdi_extra として読み込み、それをみてみました。
また、あやめのデータについては、散布図も描いて、それからわかることも少し考えてみました。
WDI データはかなりの大きさですから、表を眺めていただけでは、わかることは限られていますが、それでも、まずは、表がどのようなものかを確認することは、大切です。