29 世界不平等データベース
29.1 WID と WIR
World Inequality Database(世界不平等データベース、WID.world)は、国内および国家間の両方で、所得と富の分布が歴史とともに、どのように、進化・変化してきたかに関する広範な情報を、提供することを目的とした、オープンデータベースです。
The World Inequality Database (WID.world) aims to provide open and convenient access to the most extensive available database on the historical evolution of the world distribution of income and wealth, both within countries and between countries. (参照)
ホームページ:https://wid.world
また、世界不平等データベース(WID.world)では、毎年、世界不平等報告(World Inequality Report, WIR)を出版しています。
29.2 世界不平等報告2022(WIR2022)
まず、World Inequility Report 2022(WIR2022)の 概要(Executive Report)に含まれている、図を、再構成(recrerate)する方法を説明し、そのあとで、報告の他の部分のデータの取得方法や、活用について説明します。
以下が、基本的な、サイトの URL です。
- 世界不平等報告2022(World Inequality Report): https://wir2022.wid.world/
- 概要(Executive Summary): https://wir2022.wid.world/executive-summary/
- 分析方法(Methodology): https://wir2022.wid.world/methodology/
- 概要のデータ(WIR2022 Executive Summary Data): https://wir2022.wid.world/www-site/uploads/2022/03/WIR2022TablesFigures-Summary.xlsx
29.3 WIR2022概要
29.3.1 準備(Setup)
まず、ダウンロードしたデータを保存する data ディレクトリ(フォルダ)を作成します。言語を英語に設定することをお勧めします。Error が生じた時に、インターネット上で検索する時に、役立ちます。
Sys.setenv(LANG = "en")
dir.create("./data")分析方法(Methodology)の、ページをみると、概要のデータのダウンロード(Download the datasets of the executive summary)があります。Download と書いてあるところを、右クリックまたは、Ctrl を押しながら、クリックすると、データのリンク先の URL を取得できます。一旦、ダウンロードして、それを、上で作成した、data ディレクトリに入れても構いませんが、再現性の確保から、ここでは、URL を使います。直接ダウンロードする場合には、そのページの URL や、項目を記録しておいてください。
データは、Excel 形式になっており、図も、Excel で作成したようですが、どのように作成したかはわかりません。
まったく同じものはできませんが、同様のものを、R で作成します。
tidyverse:標準的なパッケージ
readxl: tidyverse パッケージ群の一部ですが、tidyverse の主要なパッケージとしては読み込まれませんので、Excel ファイルを読み込むために、読み込みます。
DT: 読み込まなくても作業はできますが、皆さんにも、確認していただくために、表の中の検索機能がつけられる、DT パッケージを読み込みます。自分で作業をするときは、Environment から、データを見ることで、代替可能です。
maps: 世界地図の描画がありますから、そのための世界地図のデータが含まれるパッケージを読み込みます。
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.3 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.4 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.2
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(readxl)
library(DT)
library(maps)
#>
#> Attaching package: 'maps'
#>
#> The following object is masked from 'package:purrr':
#>
#> mapExcel ファイルは、CSV のようなテキストファイルではなく、デジタルファイル(binary file)ですから、ダウンロードするには mode = "wb" を追加する必要があります。
まず、データファイルの、URL から、データを読み込み、data ディレクトリに保存します。Excel ファイルは、binary(二進)の、デジタルファイルで、テキストファイルではありませんから、mode = 'wb' とします。‘wb’ でも、“wb” でも構いません。
url_summary <- "https://wir2022.wid.world/www-site/uploads/2022/03/WIR2022TablesFigures-Summary.xlsx"
download.file(
url = url_summary,
destfile = "./data/WIR2022TablesFigures-Summary.xlsx",
mode = "wb") 読み込めない時は、単純に、Download をクリックして、ダウンロードし、作成した、data ディレクトリに保存してください。
Mac の場合は、リソースファイルというものも取得するので、mode = ‘wb’ はなくても、ダウンロード可能です。
download.file(url = url_summary,
destfile = "data/WIR2022TablesFigures-Summary.xlsx") Excel ファイルに、どのような名前の シートが含まれているか、excel_sheets を使って確認します。
summary_sheets <- excel_sheets("data/WIR2022TablesFigures-Summary.xlsx")
summary_sheets
#> [1] "Index" "F1" "F2" "F3"
#> [5] "F4" "F5." "F6" "F7"
#> [9] "F8" "F9" "F10" "F11"
#> [13] "F12" "F13" "F14" "F15"
#> [17] "T1" "data-F1" "data-F2" "data-F3"
#> [21] "data-F4" "data-F5" "data-F6" "data-F7"
#> [25] "data-F8" "data-F9" "data-F10" "data-F11"
#> [29] "data-F12" "data-F13." "data-F14." "data-F15"- Excel ファイルをあければ、シート名は、確認できますが、読み込む時には、リストがあると便利です。コピー・ペーストも使えます。よくみていただくと、なんと、シート名の最後に、ピリオッドが入っているものもあります。注意が必要です。
- Excel ファイルを見ればわかりますが、最初のほうは、グラフなどが載っており、後の方が、データになっています。
- 読み込む時は、シート名
sheet = "Index"以外に、sheet = 1など、何番目のシートかを指定することも可能です。ただ、たとえば、シートを削除していたりすると、削除したシートも含めての番号になっているので、問題が起こる場合もあります。
df_index <- read_excel("data/WIR2022TablesFigures-Summary.xlsx",
sheet = "Index")
df_indexこのファイルの情報から、それぞれのシートの内容がわかります。データは、“data-F1” から “data-F15” にあります。
29.3.2 F1: 世界の所得と富の不平等 2021年
Global income and wealth inequality, 2021
df_f1 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F1")
#> New names:
#> • `` -> `...1`- 最初の列には、列名がないため, R は、自動的に
...1を割り当て、New names:とメッセージを出しています。
df_f1
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
geom_text(aes(x = cat, y = value, group = group, label = scales::label_percent(accuracy=1)(value)), vjust = -0.08,
position = position_dodge(0.9)) +
labs(title = "Figure 1. Global income and wealth inequality, 2021",
x = "", y = "Share of total income or wealth", fill = "")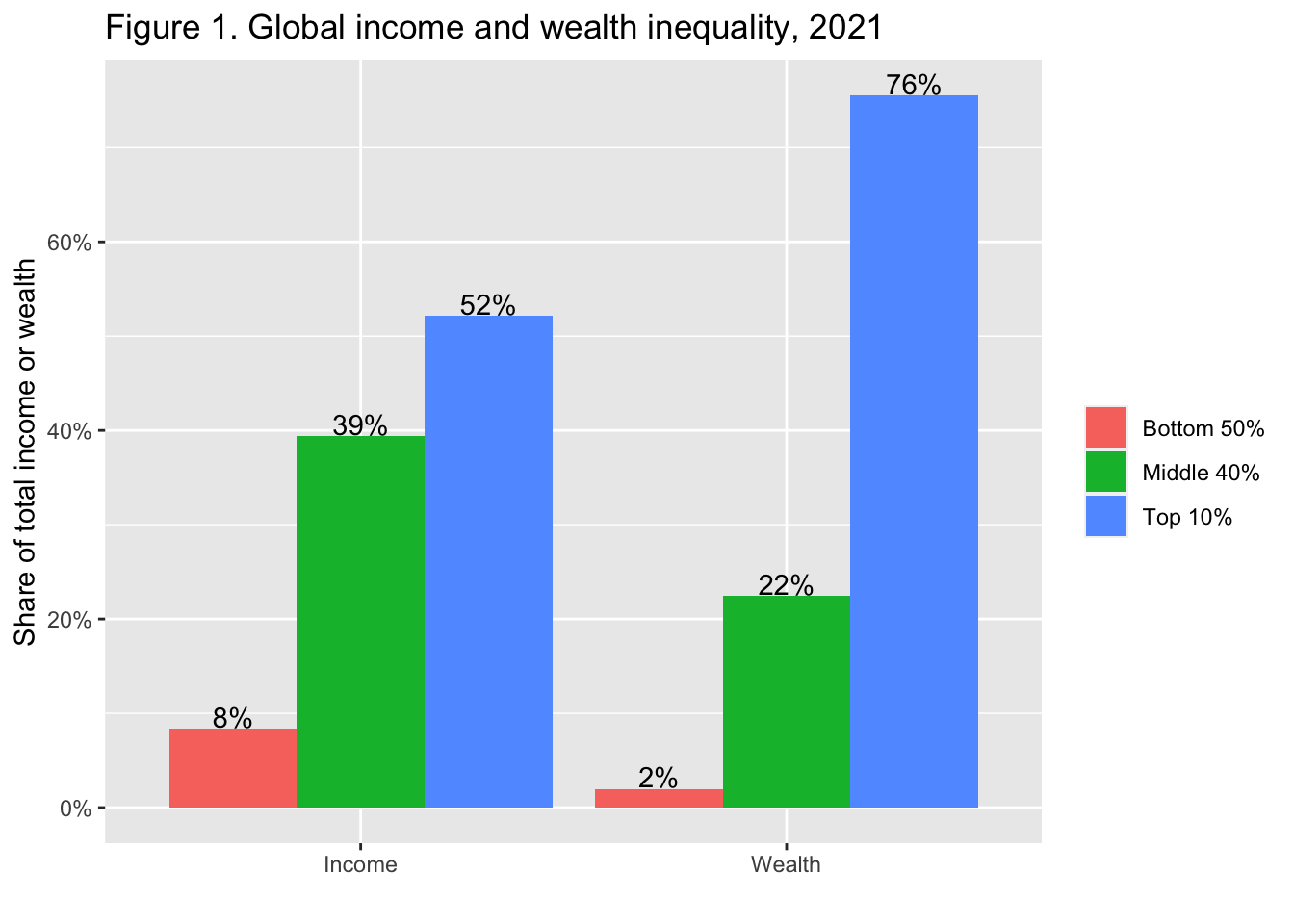
Interpretation: The global bottom 50% captures 8.5% of total income measured at Purchasing Power Parity (PPP). The global bottom 50% owns 2% of wealth (at Purchasing Power Parity). The global top 10% owns 76% of total Household wealth and captures 52% of total income in 2021. Note that top wealth holders are not necessarily top income holders. Incomes are measured after the operation of pension and unemployment systems and before taxes and transfers.
図の解釈 世界の下位50%は、購買力平価(PPP)で測定した総所得の8.5%を占めている。世界の下位50%は富の2%を所有(購買力平価で)。世界の上位10%は、2021年には世帯総資産の76%を保有し、総所得の52%を獲得する。富の上位者が所得の上位者とは限らないことに注意。所得は年金と失業制度の運用後、税金と移転の前に測定されている。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.2.1 説明
29.3.2.1.1 Step 1.
- 図には Top 1% のデータは含まれていない。
- Income と Wealth の二つのグループがあり、
pivot_longerを使って、整える(tidy にする)必要がある。 -
pivot_longerの基本的な使い方:-
pivot_longer(cols, names_to = "group", values_to = "value"),colsは、縦長の形式にする列、この場合は、2列から4列なので、cols = 2:4と指定。第一列以外なので、cols = -1, と指定してもよい。
-
- 列名 …1 を cat(カテゴリの省略形)に変更。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value")29.3.2.1.2 Step 2.
-
ggplot2を使って図を描く。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "level", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = level)) +
geom_col()
29.3.2.1.3 Step 3.
- 積み上げグラフになっているので、
position = dodgeで横に並べる。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge")
29.3.2.1.4 Step 4.
- y-軸を%に変更
- この場合は、
scale_y_continuous(labels = c("0%", "20%", "40%", "60%", "80%"))でも同じ。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1))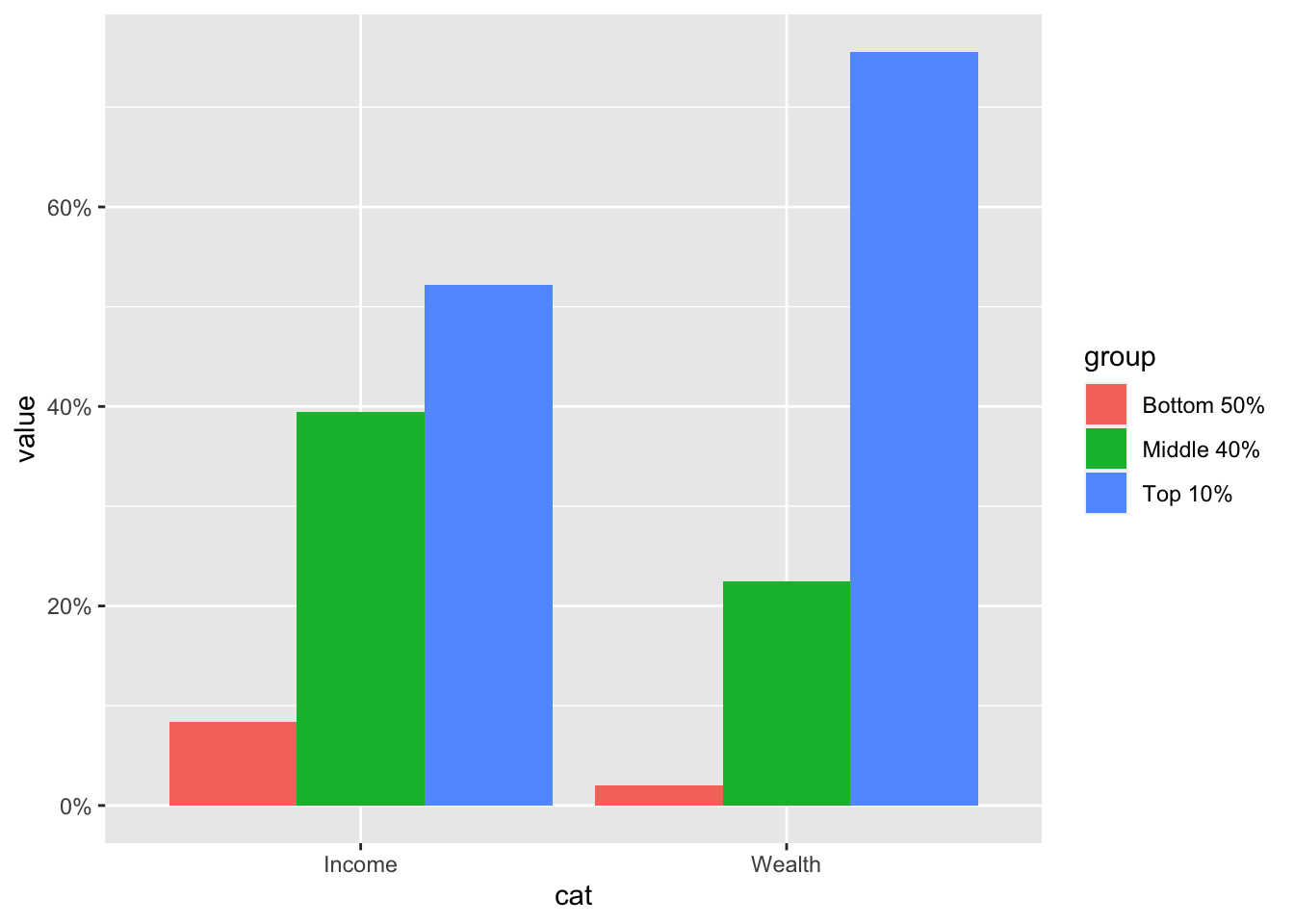
29.3.2.1.5 Step 5.
- 表題(title)と y-軸のラベルをつけ、x 軸のられると、凡例のラベルを消去。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 1. Global income and wealth inequality, 2021",
x = "", y = "Share of total income or wealth", fill = "")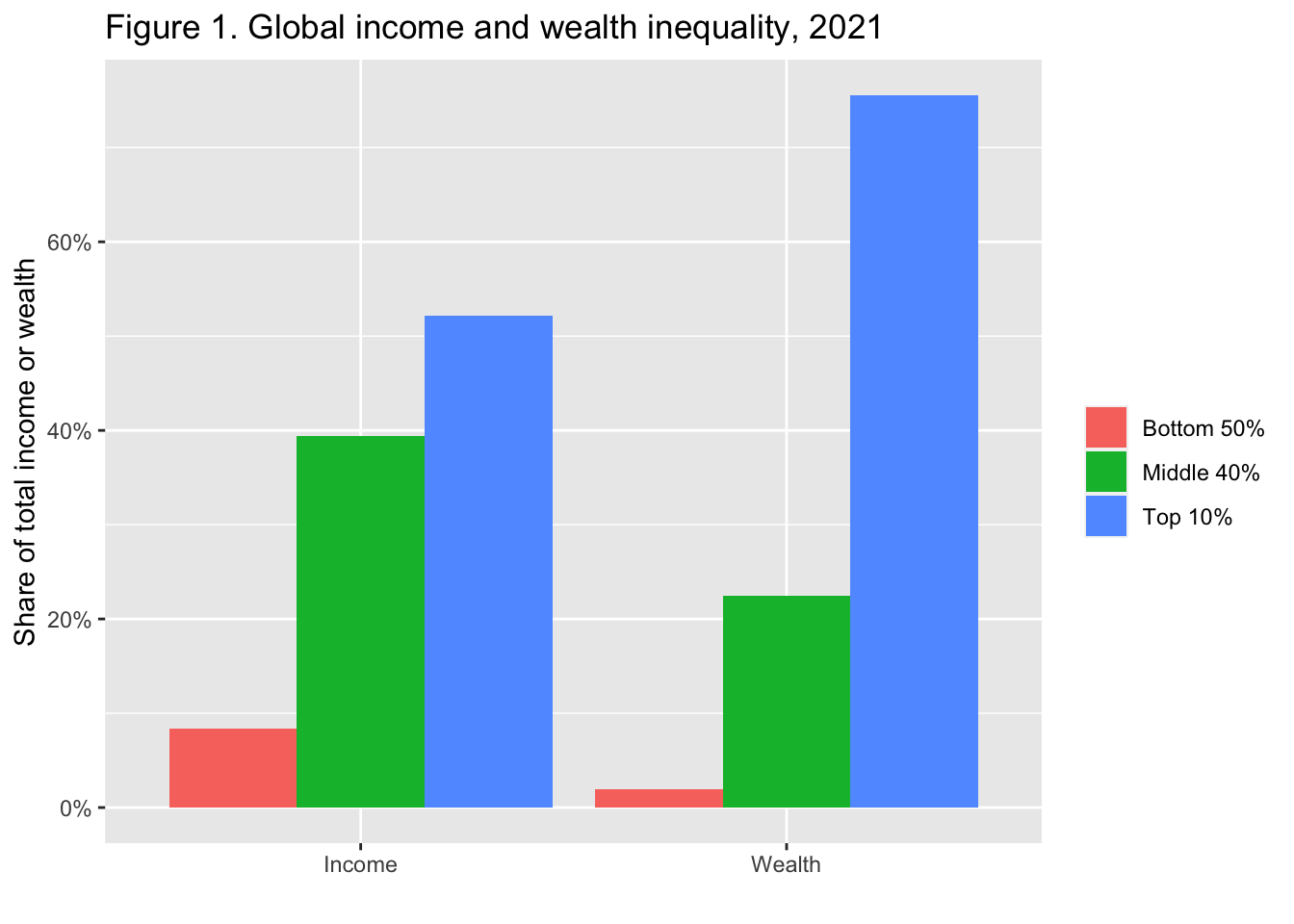
29.3.2.1.6 Step 6.
- 値を、棒グラフの上に表示。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
geom_text(aes(x = cat, y = value, group = group, label = scales::label_percent(accuracy=1)(value)),
position = position_dodge(0.9)) +
labs(title = "Figure 1. Global income and wealth inequality, 2021",
x = "", y = "Share of total income or wealth", fill = "")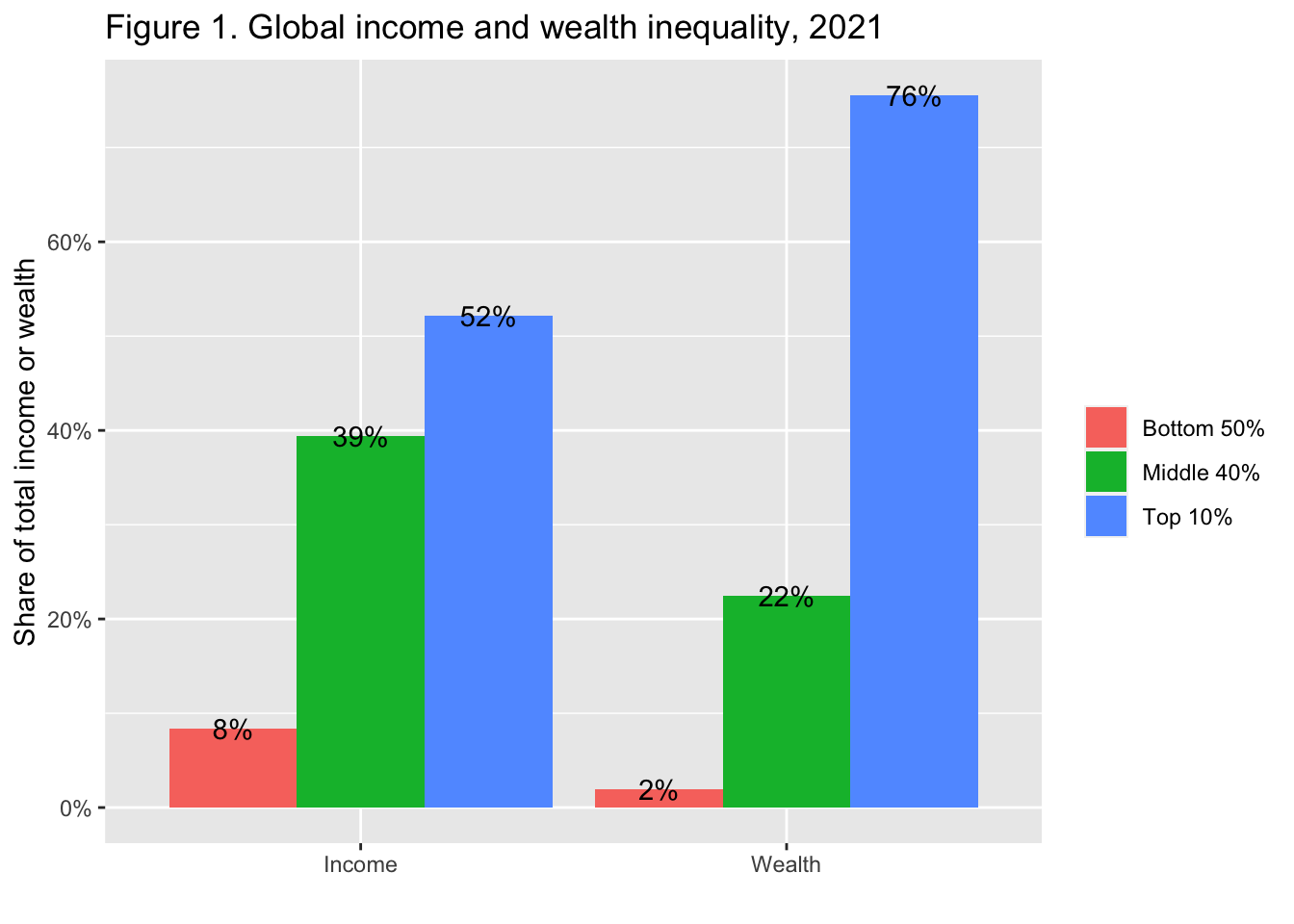
29.3.2.1.7 Step 7.
- 棒の上にするためには、
vjustを利用して調節。
df_f1 |> select(cat = ...1, 2:4) |>
pivot_longer(2:4, names_to = "group", values_to = "value") |>
ggplot(aes(x = cat, y = value, fill = group)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
geom_text(aes(x = cat, y = value, group = group, label = scales::label_percent(accuracy=1)(value)), vjust = 0,
position = position_dodge(width = 0.9)) +
labs(title = "Figure 1. Global income and wealth inequality, 2021",
x = "", y = "Share of total income or wealth", fill = "")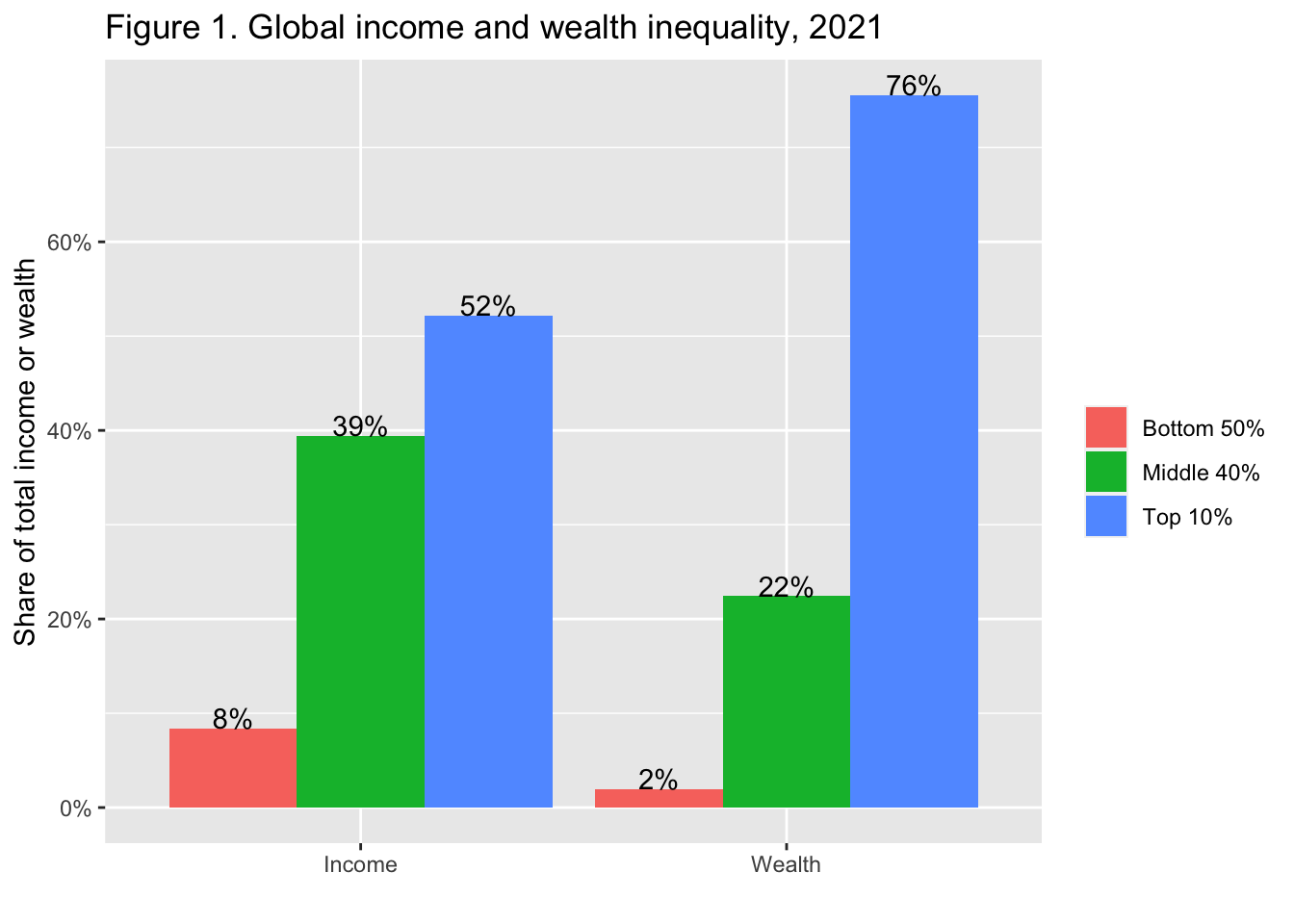
29.3.3 F2: 最貧困層はかなり少なくなっている: 2021年における世界の下位50%、中位40%、上位10%の所得シェア
The poorest half lags behind: Bottom 50%, middle 40% and top 10% income shares across the world in 2021
df_f2 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F2")
df_f2
df_f2 |> pivot_longer(3:5, names_to = "level", values_to = "value") |>
ggplot(aes(x = iso, y = value, fill = level)) +
geom_col(position = "dodge") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 8)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 2. The poorest half lags behind Bottom 50%, middle 40% \nand top 10% income shares across the world in 2021",
x = "", y = "Share of national income (%)", fill = "")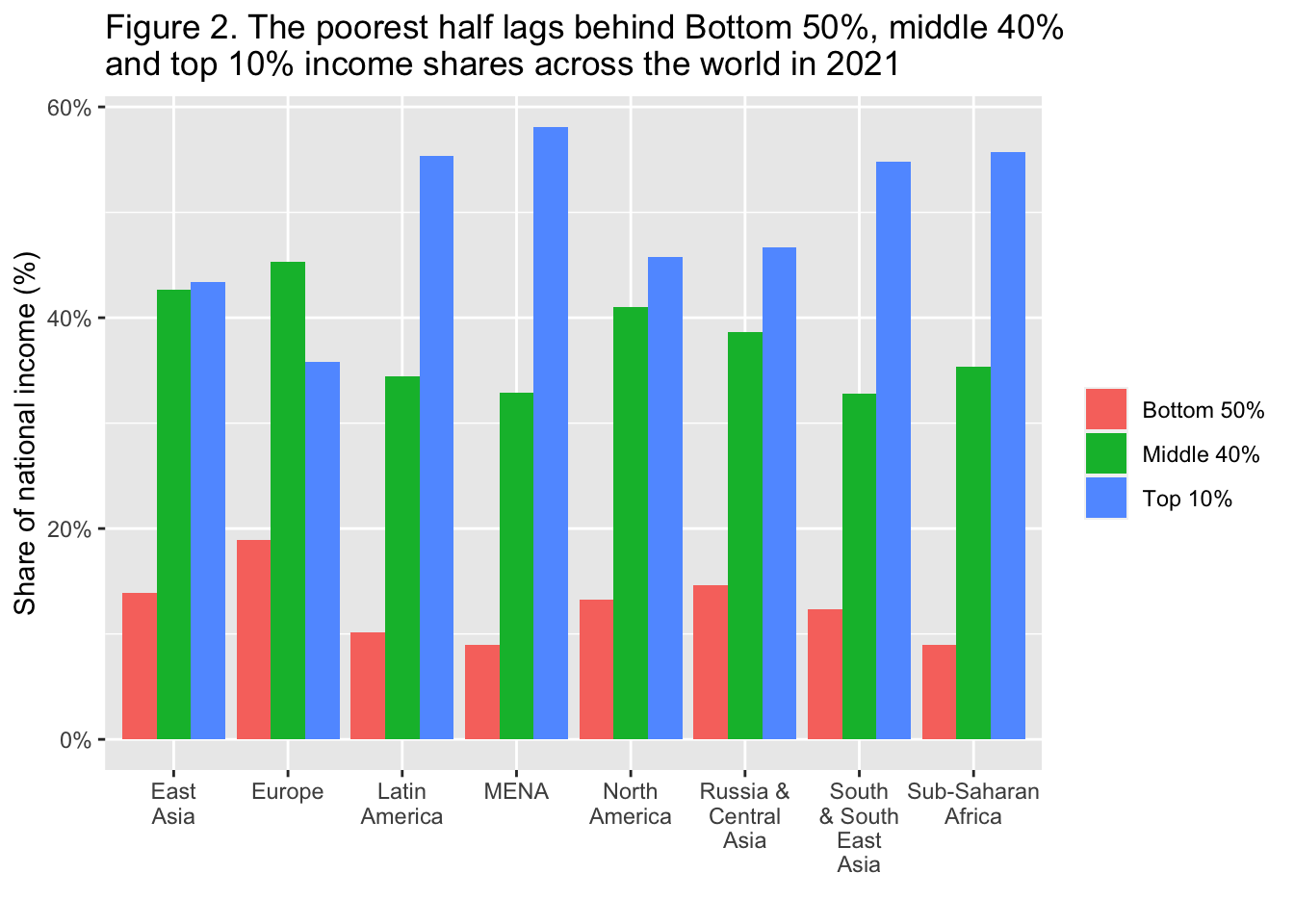
Interpretation: In Latin America, the top 10% captures 55% of national income, compared to 36% in Europe. Income is measured after pension and unemployment contributions and benefits paid and received by individuals but before income taxes and other transfers.
図の解釈 ラテンアメリカでは、上位10%が国民所得の55%を占めているのに対し、ヨーロッパでは36%である。所得は、個人が支払った年金や失業保険、給付の後、所得税やその他の移転の前に測定される。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.3.1 説明
29.3.3.1.2 Step 2.
- タイトルが非常に長いので、
\nを入れて改行。 ‘and’ の前にスペースを入れると\n and‘and’ の前にスペースが入ることになる。
df_f2 |> pivot_longer(3:5, names_to = "level", values_to = "value") |>
ggplot(aes(x = iso, y = value, fill = level)) +
geom_col(position = "dodge") +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 2. The poorest half lags behind Bottom 50%, middle 40% \nand top 10% income shares across the world in 2021",
x = "", y = "Share of national income (%)", fill = "")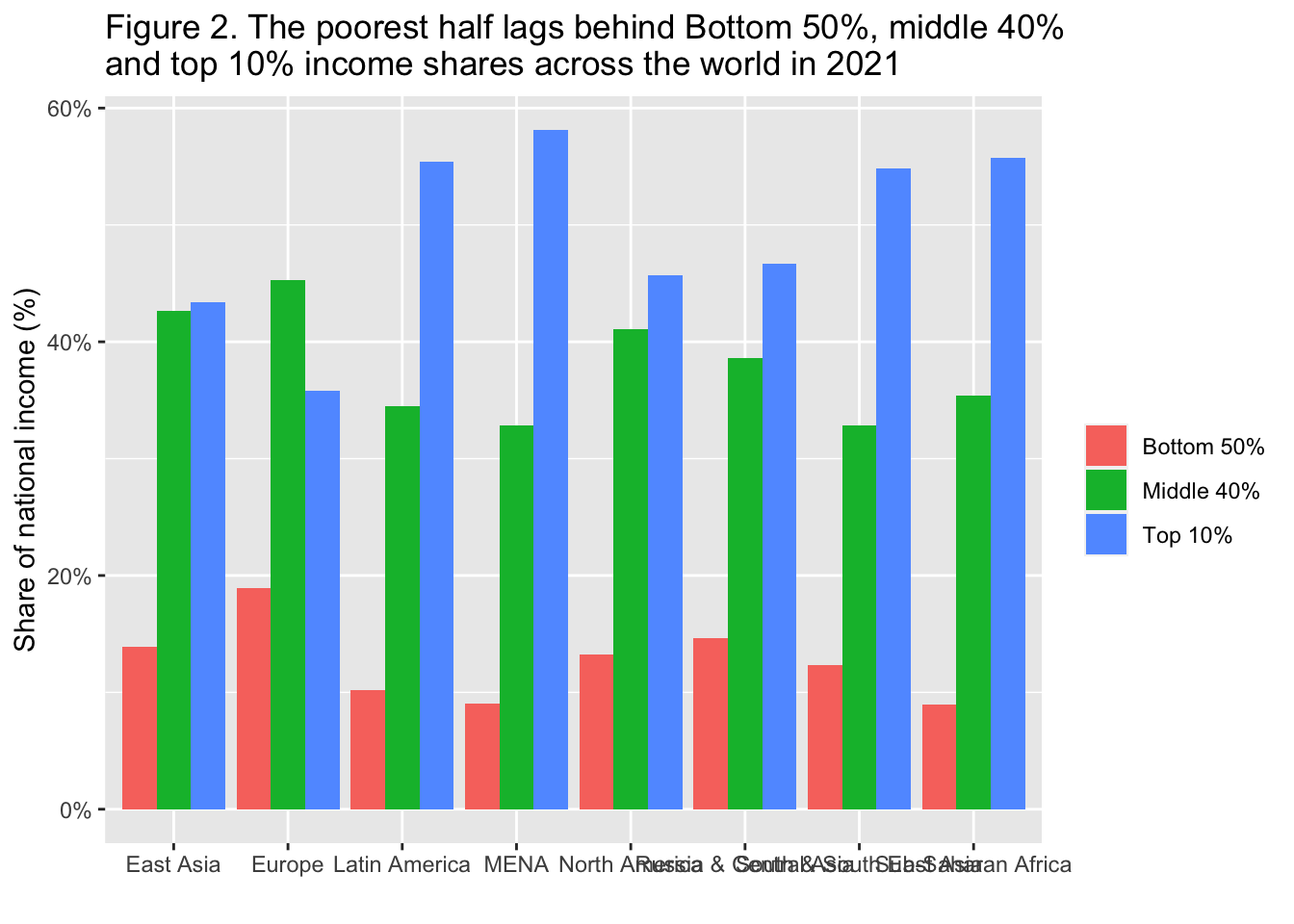
29.3.3.1.3 Step 3.
- x-軸のラベルが重なっている。一つの方法は
angleを使って角度をつけること。 - もう一つの方法は
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 8))をつかって、幅を指定し折り返すことで重複を避ける。 - stringr は、tidyverse と一緒にインストールされるが、読み込まれてはいないので、stringr:: としているが、library(stringr) と最初に読み込んでおけば、
scale_x_discrete(labels = function(x) str_wrap(x, width = 8))で良い。
df_f2 |> pivot_longer(3:5, names_to = "level", values_to = "value") |>
ggplot(aes(x = iso, y = value, fill = level)) +
geom_col(position = "dodge") +
theme(axis.text.x = element_text(angle = 30, vjust = 1, hjust=1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 2. The poorest half lags behind Bottom 50%, middle 40% \nand top 10% income shares across the world in 2021",
x = "", y = "Share of national income (%)", fill = "")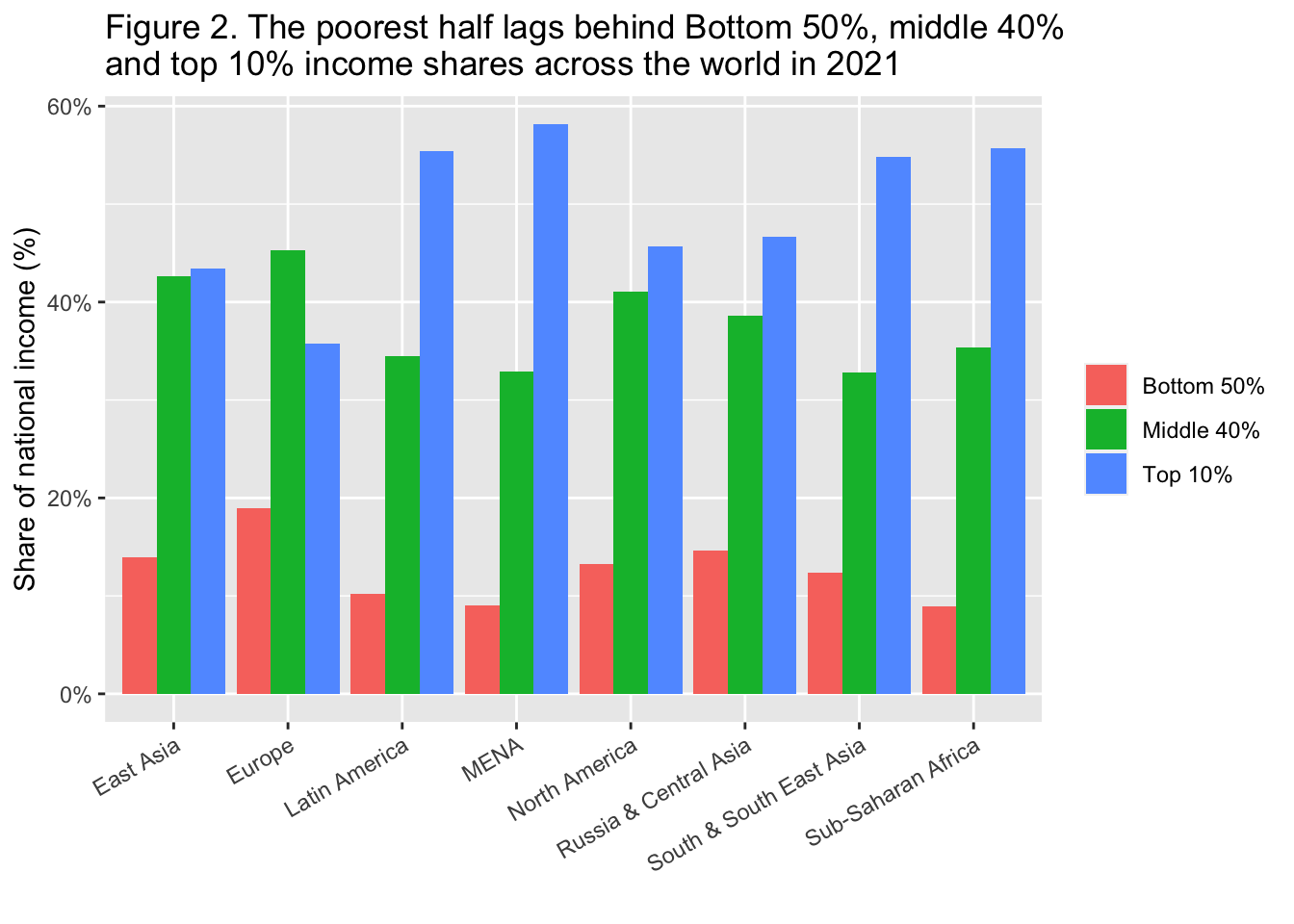
df_f2 |> pivot_longer(3:5, names_to = "level", values_to = "value") |>
ggplot(aes(x = iso, y = value, fill = level)) +
geom_col(position = "dodge") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 8)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 2. The poorest half lags behind Bottom 50%, middle 40% \nand top 10% income shares across the world in 2021",
x = "", y = "Share of national income (%)", fill = "")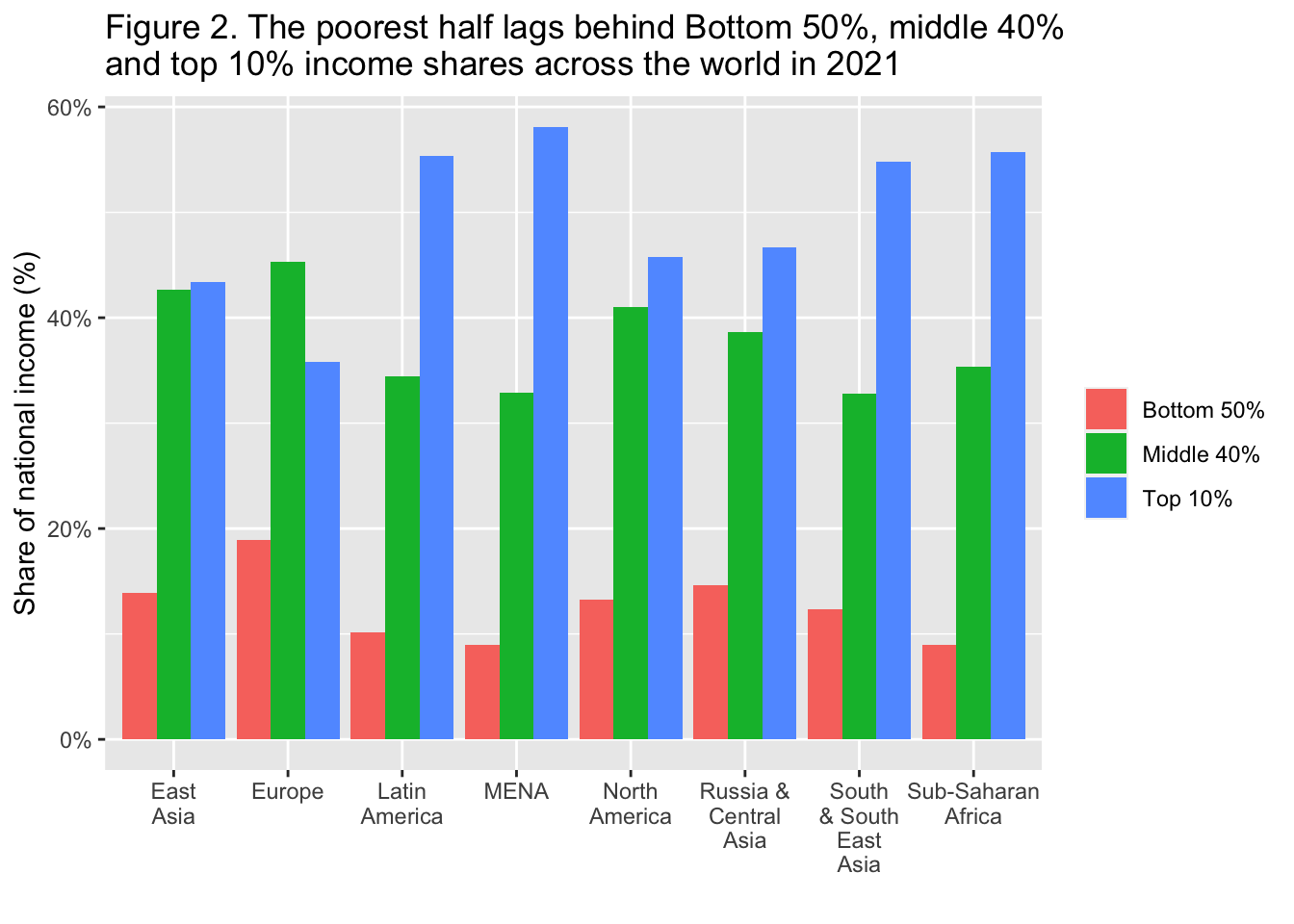
29.3.4 F3: 世界の所得格差上位10位/下位50位(2021年)
Top 10/Bottom 50 income gaps across the world, 2021
df_f3 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F3")
df_f3
map0<-map_data("world")
map0$region[map0$region=="Democratic Republic of the Congo"]<-"DR Congo"
map0$region[map0$region=="Republic of Congo"]<-"Congo"
map0$region[map0$region=="Ivory Coast"]<-"Cote dIvoire"
map0$region[map0$region=="Vietnam"]<-"Viet Nam"
map0$region[map0$region=="Russia"]<-"Russian Federation"
map0$region[map0$region=="South Korea"]<-"Korea"
map0$region[map0$region=="UK"]<-"United Kingdom"
map0$region[map0$region=="Brunei"]<-"Brunei Darussalam"
map0$region[map0$region=="Laos"]<-"Lao PDR"
map0$region[map0$region=="Cote dIvoire"]<-"Cote d'Ivoire"
map0$region[map0$region=="Cape Verde"]<- "Cabo Verde"
map0$region[map0$region=="Syria"]<- "Syrian Arab Republic"
map0$region[map0$region=="Trinidad"]<- "Trinidad and Tobago"
map0$region[map0$region=="Tobago"]<- "Trinidad and Tobago"
df_f3 |>
mutate(`Top 10 Bottom 50 Ratio` = cut(T10B50,breaks = c(5, 12, 13, 16, 19,140), include.lowest = FALSE)) |>
ggplot(aes(map_id = Country)) + geom_map(aes(fill = `Top 10 Bottom 50 Ratio`), map = map0) + expand_limits(x = map0$long, y = map0$lat) +
labs(title = "Figure 3. Top 10/Bottom 50 income gaps across the world, 2021",
x = "", y = "", fill = "Top 10/Bottom 50 ratio") +
theme(legend.position="bottom",
axis.text.x=element_blank(), axis.ticks.x=element_blank(),
axis.text.y=element_blank(), axis.ticks.y=element_blank()) +
scale_fill_brewer(palette='YlOrRd')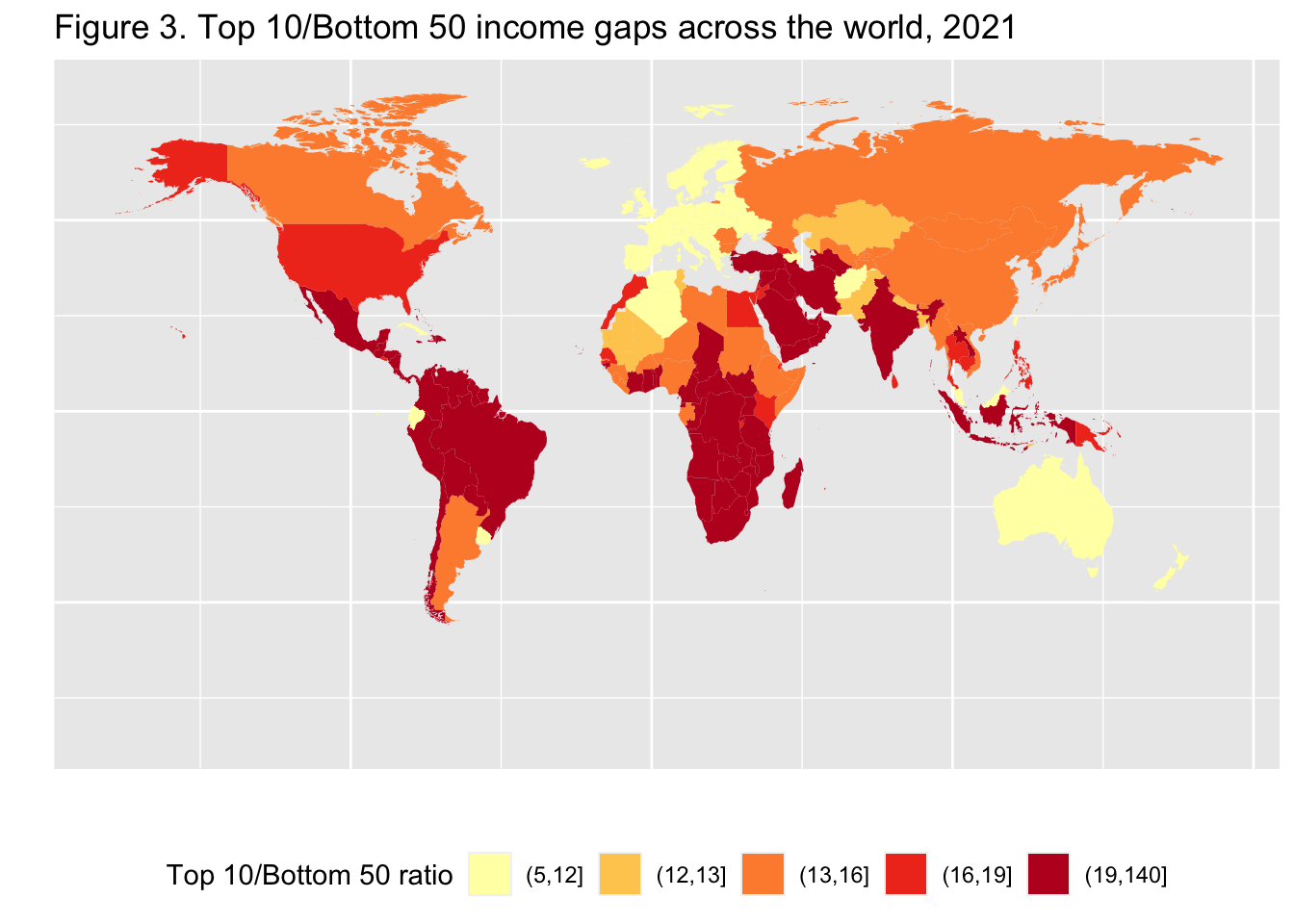
Interpretation: In Brazil, the bottom 50% earns 29 times less than the top 10%. The value is 7 in France. Income is measured after pension and unemployment payments and benefits received by individuals but before other taxes they pay and transfers they receive.
図の解釈 :ブラジルでは、下位50%の所得は上位10%の29倍である。フランスは7倍。所得は、個人が受け取る年金や失業手当、給付金を差し引いたものであり、その他の税金や給付金を差し引く前のものである。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.4.1 説明
29.3.4.1.1 Step 1.
df_f3 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F3")
df_f3- 最初の読み込んだ、
maprパッケージを使って、世界地図 map_data(“world”)` を読み込みます。
world_map <- map_data("world")
datatable(world_map)
#> Warning in instance$preRenderHook(instance): It seems your
#> data is too big for client-side DataTables. You may
#> consider server-side processing:
#> https://rstudio.github.io/DT/server.html- まず
ggplotの標準的な雛形を使って地図を書いてみます。 国名Countryをmap_idにT10B50を数値データに割り当てます。地図データworld_mapは、それぞれの地域の経度と緯度 (longとlat)の 情報を持っており、地図を書きます。地図の端が切れてしまうといけないので、expand_limitを付け加えます。
df_f3 |>
ggplot(aes(map_id = Country)) +
geom_map(aes(fill = `T10B50`), map = world_map) +
expand_limits(x = world_map$long, y = world_map$lat)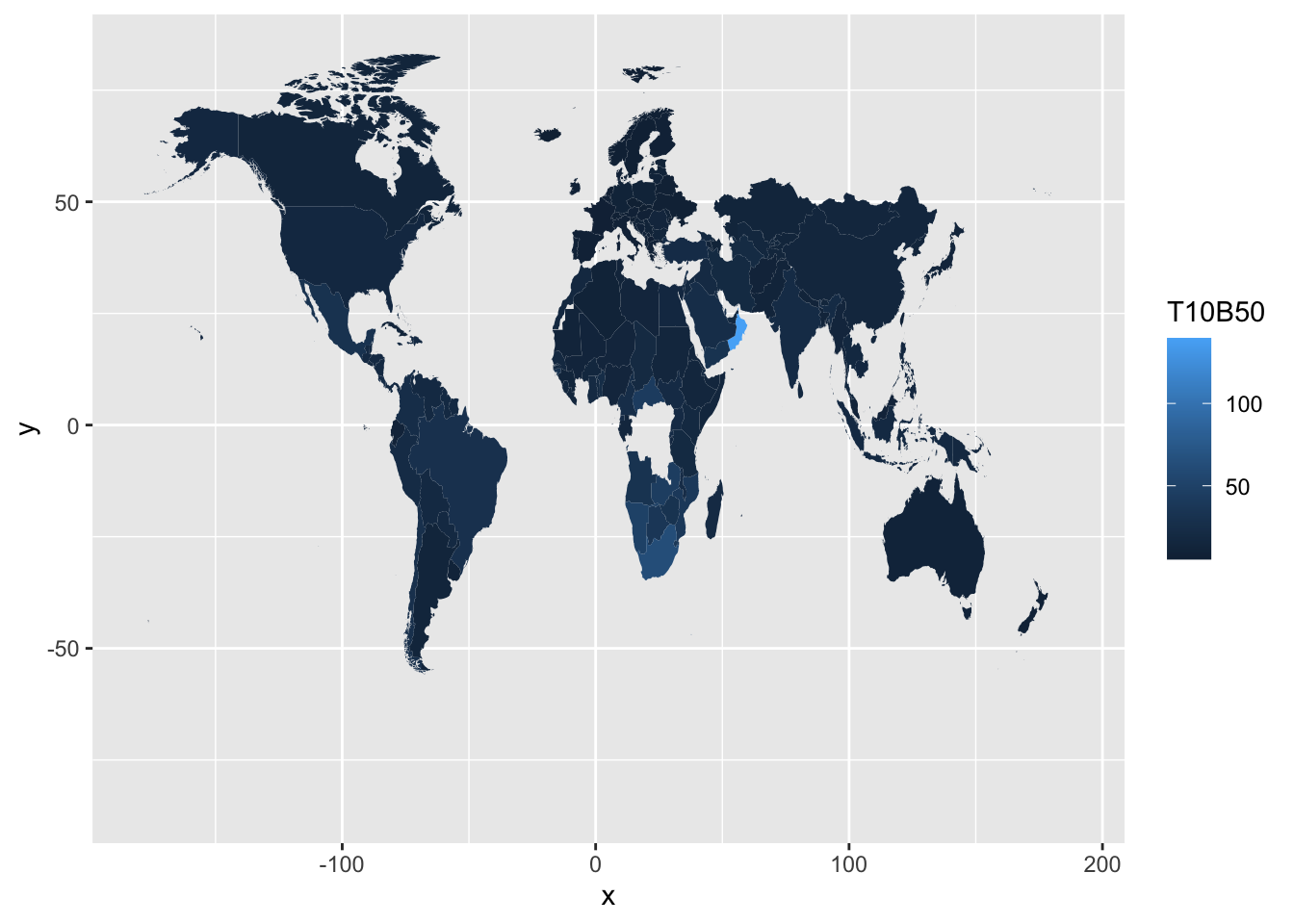
29.3.4.1.2 Step 2.
- いくつかの問題点がわかります。
- ロシア(Russia), コンゴ(Congo)などいくつかの地域が地図から抜け落ちています。
- どのように区切るかなどの尺度と、凡例は改善が必要です。
- 地図の横幅が狭くなるので、凡例は、下に移したほうがよい。

地図
world_mapの地域名regionと、df_f3の国名が異なっていることが、最初の問題の理由のようです。DT::datatable、すなわちDTパッケージのdatatable機能をつかって調べてみます。
datatable(df_f3)-
ロシア ‘russia’ や、コンゴ ‘congo’ を調べると、次のように対応していることがわかります。等号の左が、df_f3 の名前です。
- Russian Federation = Russia (
world_map名) - DR Congo = Democratic Republic of the Congo (
world_map名) - Congo = Republic of Congo (
world_map名)
- Russian Federation = Russia (
-
最低でも、三つほど、修正する方法があります。
-
最初の方法は Base R の機能を使う方法です。
-
df_f3_rev$Country[df_f3_rev$Country == "Russian Federation"] <- "Russia": これにより、df_f3_revのCountry列が、"Russian Federation" と一致するものを、"Russiaに取り替える、などです。
-
二番目の方法は、
tidyverseのmutateを、補助関数case_whenとともに使い修正する方法。三番目は、対照表を作っておいて、
left_joinで、修正する方法です。
-
データを一つ一つ手で直して言ってもよいように思えますが、上のような修正を記録に残すことで、間違いを減らせます。追跡できる方法を、極力採用してください。
df_f3_rev <- df_f3
df_f3_rev$Country[df_f3_rev$Country == "Russian Federation"] <- "Russia"
df_f3_rev$Country[df_f3_rev$Country == "DR Congo"] <- "Democratic Republic of the Congo"
df_f3_rev$Country[df_f3_rev$Country == "Congo"] <- "Republic of Congo"- 次に
anti_joinを使って、チェックします。これによって、df_f3_revの Country には入っているが、world_mapのregionには入っていない、もののリストが得られます。
一つ一つ修正しても良いのですが WIR は R でのコードを提供しています。そこで、それを使ってみましょう。Methodology の site にあります。‘Full Datasets’ と ’Computer Codes’をダウンロードすると、 WIR2022 - Computer codes, がありますから Chapter1_Maps.R を探してください。
map<-map_data("world")
map$region[map$region=="Democratic Republic of the Congo"]<-"DR Congo"
map$region[map$region=="Republic of Congo"]<-"Congo"
map$region[map$region=="Ivory Coast"]<-"Cote dIvoire"
map$region[map$region=="Vietnam"]<-"Viet Nam"
# map$region[map$region=="United Arab Emirates"]<-"UAE"どうも、最後の UAE は間違いのようですから、削除しました。このように、記録が残っているから、それもわかります。
次は見つかりません。 map を使ってみましょう。
index_region2<-read_dta("index_region.dta")
map<-left_join(map,index_region2,by=c("region"="name_region"))
map$ISO[map$region=="Greenland"]<-"GL"
map$ISO[map$region=="UAE"]<-"AE"
map$ISO[map$region=="Brunei"]<-"BR" # done
map$ISO[map$region=="Antigua"]<-"AG"
map$ISO[map$region=="Cape Verde"]<-"CV"
map$ISO[map$region=="Cote dIvoire"]<-"CI"
map$ISO[map$region=="UK"]<-"GB" # done
map$ISO[map$region=="Canary Islands"]<-"ES"
map$ISO[map$region=="French Guiana"]<-"FR"
map$ISO[map$region=="Saint Kitts"]<-"KN"
map$ISO[map$region=="South Korea"]<-"KR"
map$ISO[map$region=="Saint Martin"]<-"MF"
map$ISO[map$region=="Macedonia"]<-"MK"
map$ISO[map$region=="Russia"]<-"RU" # done
map$ISO[map$region=="Bonaire"]<-"BQ"
map$ISO[map$region=="Sint Eustatius"]<-"BQ"
map$ISO[map$region=="Saba"]<-"BQ"
map$ISO[map$region=="Laos"]<-"LA"
map$ISO[map$region=="Sint Maarten"]<-"SX"
map$ISO[map$region=="Syria"]<-"SY"
map$ISO[map$region=="Trinidad"]<-"TT"
map$ISO[map$region=="Tobago"]<-"TT"
map$ISO[map$region=="Virgin Islands"]<-"VI"
map$ISO[map$region=="Saint Vincent"]<-"VC"
map$ISO[map$region=="Grenadines"]<-"VC"
map$ISO[map$region=="French Southern and Antarctic Lands"]<-"FR"
map$ISO[map$region=="Western Sahara"]<-"WS"
map$region[map$region=="Russia"]<-"Russian Federation"
map$region[map$region=="South Korea"]<-"Korea"
map$region[map$region=="UK"]<-"United Kingdom"
map$region[map$region=="Brunei"]<-"Brunei Darussalam"
map$region[map$region=="Laos"]<-"Lao PDR"
map$region[map$region=="Cote dIvoire"]<-"Cote d'Ivoire"
map$region[map$region=="Cape Verde"]<- "Cabo Verde"
map$region[map$region=="Syria"]<- "Syrian Arab Republic"
map$region[map$region=="Trinidad"]<- "Trinidad and Tobago"
map$region[map$region=="Tobago"]<- "Trinidad and Tobago"- Zanzibar は Tanzania の一部でしょうか。国の色分けも、微妙な問題を含む場合もありますので、記録を残し、判断をメモしておくことは大切でしょう。
df_f3 |>
ggplot(aes(map_id = Country)) +
geom_map(aes(fill = `T10B50`), map = map) +
expand_limits(x = map$long, y = map$lat)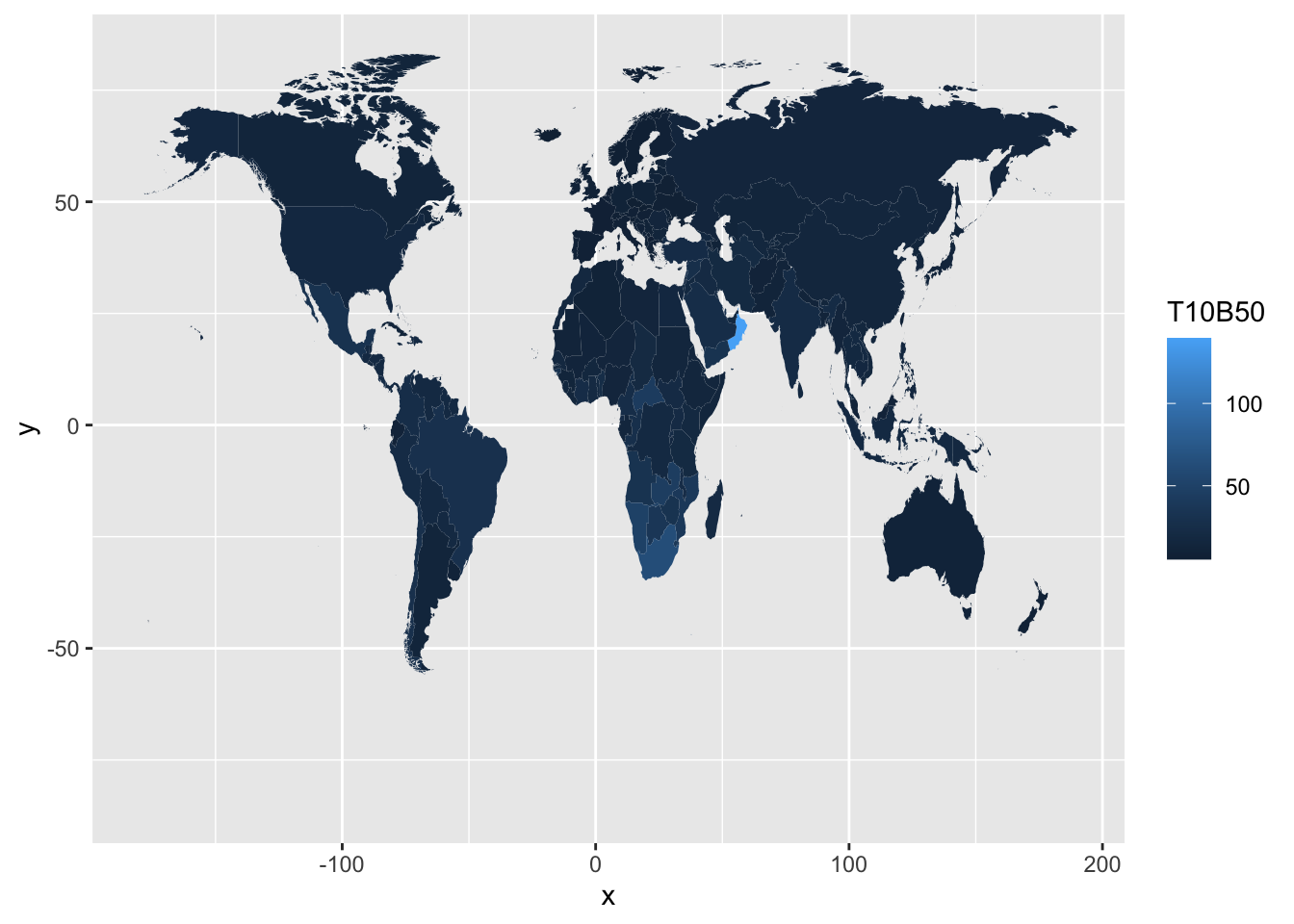
29.3.4.1.3 Step 3.
- 新しい列
Top 10 Bottom 50 Ratioを加えT10B50の値を分割します。 - 凡例を下に置くには、
theme(legend.position="bottom")を使います。
df_f3_rev |>
mutate(`Top 10 Bottom 50 Ratio` = cut(T10B50, breaks = c(5, 12, 13, 16, 19, 140), include.lowest = FALSE)) |>
ggplot(aes(map_id = Country)) + geom_map(aes(fill = `Top 10 Bottom 50 Ratio`), map = world_map) + expand_limits(x = world_map$long, y = world_map$lat) +
theme(legend.position="bottom")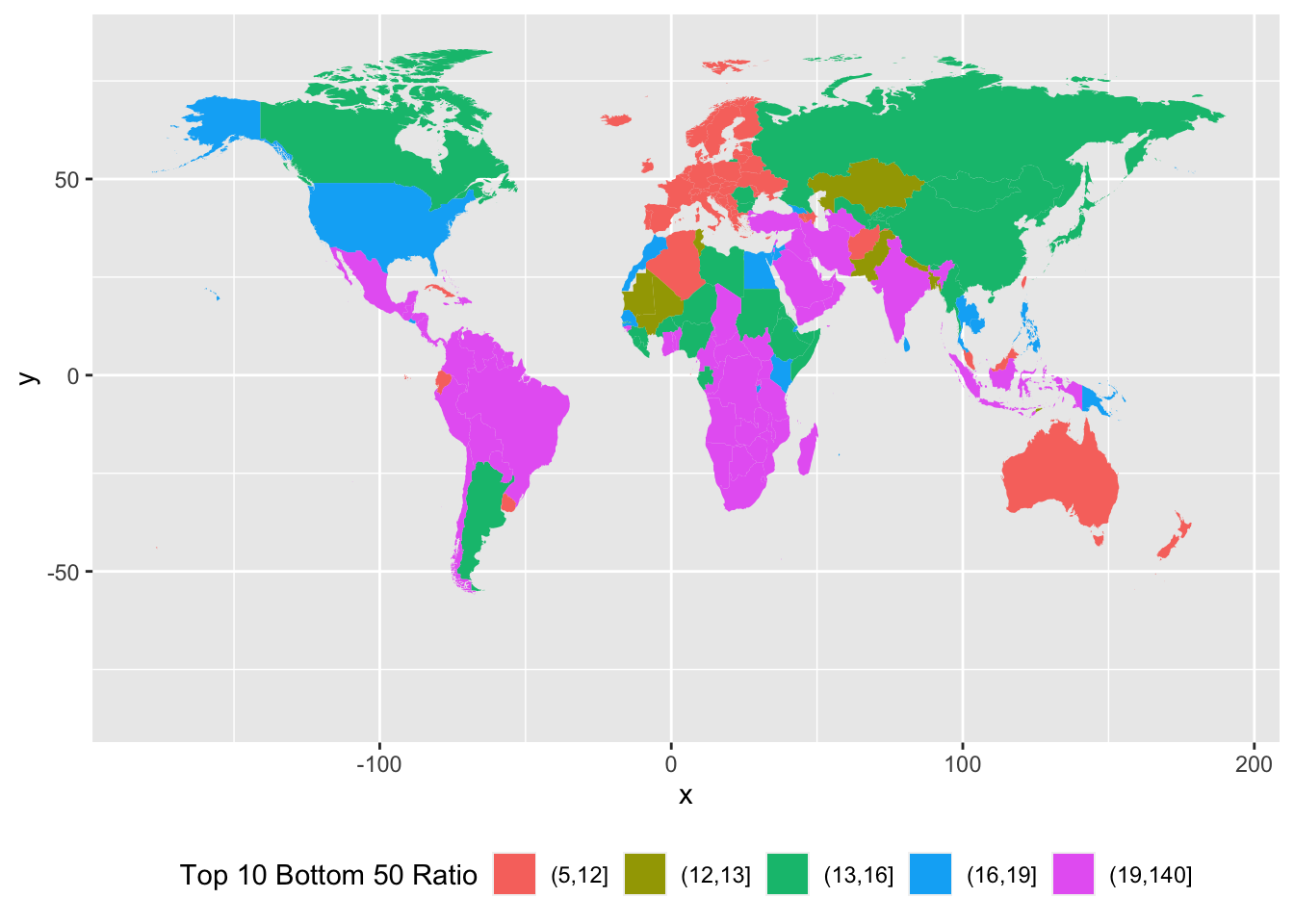
29.3.4.1.4 Step 4.
最後に、表題をつけ、 x と y それぞれの軸の名前を消去し、凡例名を変更します。
df_f3_rev |>
mutate(`Top 10 Bottom 50 Ratio` = cut(T10B50, breaks = c(5, 12, 13, 16, 19, 140), include.lowest = FALSE)) |>
ggplot(aes(map_id = Country)) + geom_map(aes(fill = `Top 10 Bottom 50 Ratio`), map = world_map) + expand_limits(x = world_map$long, y = world_map$lat) +
labs(title = "Figure 3. Top 10/Bottom 50 income gaps across the world, 2021",
x = "", y = "", fill = "Top 10/Bottom 50 ratio") +
theme(legend.position="bottom")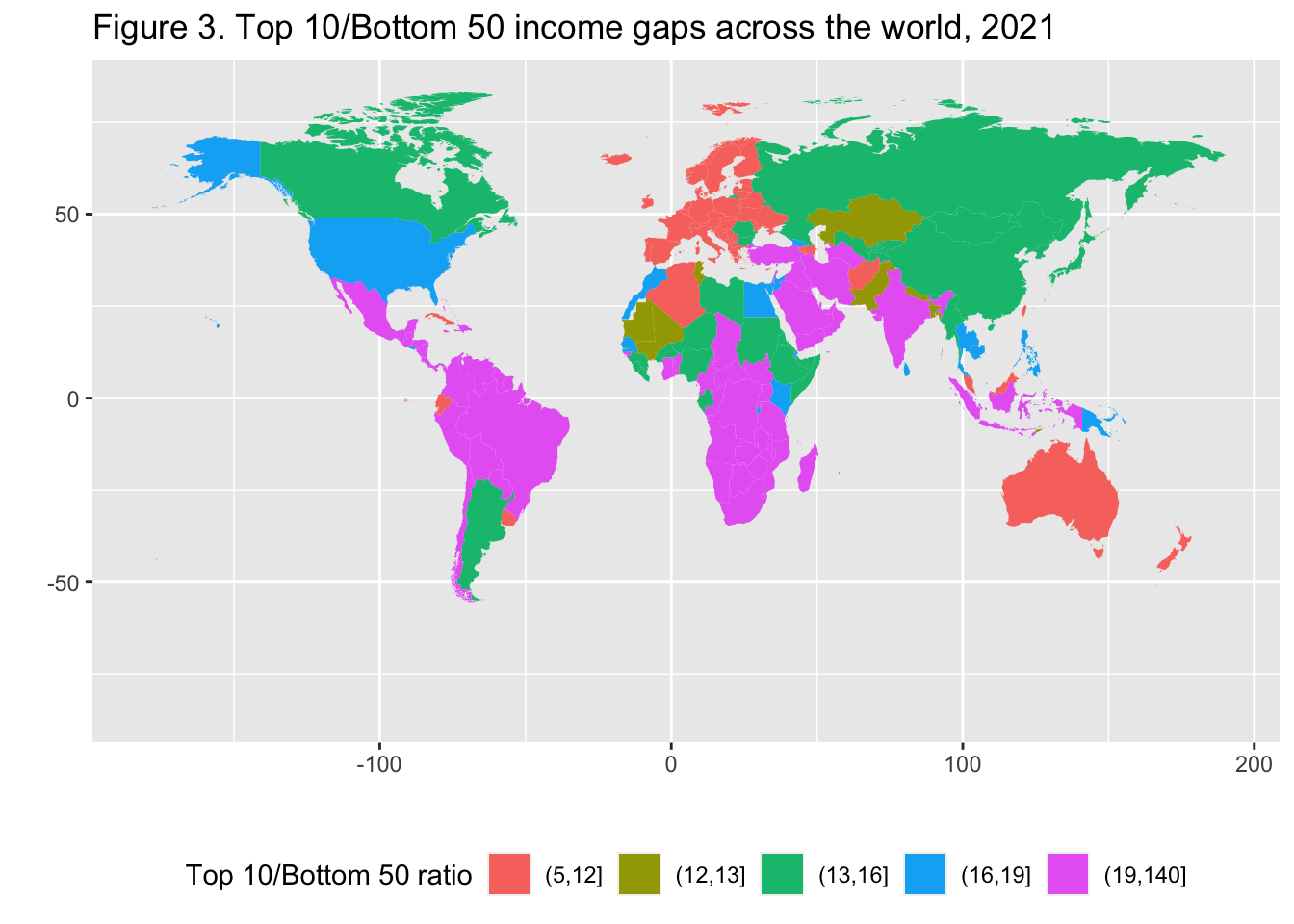
29.3.4.1.5 Step 5.
X 軸(x-axis)と Y軸(y-axis)と、目盛りの印(ticks)を消します。色を変えたい場合は、次を参照してください。
- https://ggplot2.tidyverse.org/reference/scale_brewer.html
- http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/
df_f3_rev |>
mutate(`Top 10 Bottom 50 Ratio` = cut(T10B50, breaks = c(5, 12, 13, 16, 19, 140), include.lowest = FALSE)) |>
ggplot(aes(map_id = Country)) + geom_map(aes(fill = `Top 10 Bottom 50 Ratio`), map = world_map) + expand_limits(x = world_map$long, y = world_map$lat) +
labs(title = "Figure 3. Top 10/Bottom 50 income gaps across the world, 2021",
x = "", y = "", fill = "Top 10/Bottom 50 ratio") +
theme(legend.position="bottom",
axis.text.x=element_blank(), axis.ticks.x=element_blank(),
axis.text.y=element_blank(), axis.ticks.y=element_blank()) +
scale_fill_brewer(palette='YlOrRd')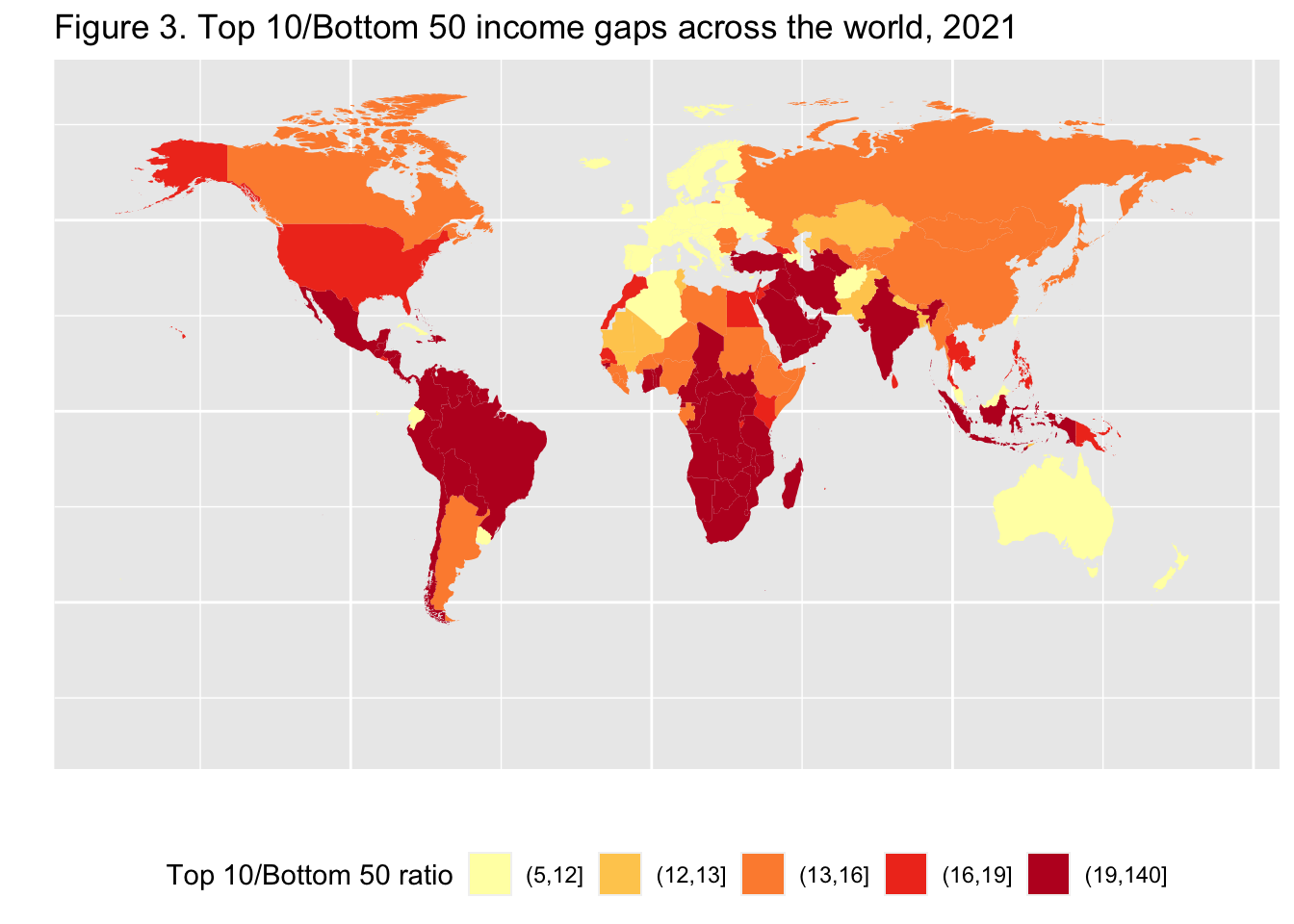
- 最初の読み込んだ、
maprパッケージを使って、世界地図 map_data(“world”)` を読み込み、それに、二文字の ISO コードを付けます。
29.3.4.1.6 Steps 3-5 (別法)
パッケージ、maps の関数 mutate(iso2c = iso.alpha(region, n=2)) によって、iso2c コードを付加することが可能です。ただ、やはり、多少問題も残ります。それぞれのコードで、何をしているか、考えてみてください。
world_map_iso2c <- map_data("world") |> mutate(iso2c = iso.alpha(region, n=2))
world_map_iso2c |> filter(is.na(iso2c)) |> distinct(region) |> pull()
#> [1] "Siachen Glacier" "Namibia" "Virgin Islands"
world_map_iso2c <- world_map_iso2c |>
mutate(iso2c = case_when(is.na(iso2c) & region == "Namibia" ~ "NA",
is.na(iso2c) & region == "Virgin Islands" ~ "US",
TRUE ~ iso2c))
df_f3 |> mutate(iso2c = iso.alpha(Country, n=2)) |> filter(is.na(iso2c)) |> distinct(Country) |> pull()
#> [1] "DR Congo" "Congo" "Cote d'Ivoire"
#> [4] "Cabo Verde" "United Kingdom" "Hong Kong"
#> [7] "Korea" "Lao PDR" "Macao"
#> [10] "Namibia" "Viet Nam" "Zanzibar"
country <- df_f3 |> distinct(Country) |> pull()
world_map_iso2c |> filter(!(region %in% country)) |> distinct(region, iso2c) |> arrange(region)
df_f3_iso2c <- df_f3 |> mutate(iso2c = iso.alpha(Country, n=2)) |>
mutate(iso2c = case_when(is.na(iso2c) & Country == "DR Congo" ~ "CD",
is.na(iso2c) & Country == "Congo" ~ "CG",
is.na(iso2c) & Country == "Cote d'Ivoire" ~ "CI",
is.na(iso2c) & Country == "Cabo Verde" ~ "CV",
is.na(iso2c) & Country == "United Kingdom" ~ "GB",
is.na(iso2c) & Country == "Hong Kong" ~ "HK",
is.na(iso2c) & Country == "Korea" ~ "KR",
is.na(iso2c) & Country == "Lao PDR" ~ "LA",
is.na(iso2c) & Country == "Macao" ~ "MO",
is.na(iso2c) & Country == "Namibia" ~ "NA",
is.na(iso2c) & Country == "Viet Nam" ~ "VN",
is.na(iso2c) & Country == "Zanzibar" ~ "TZ",
TRUE ~ iso2c))
df_f3_iso2c
world_map_iso2c |> left_join(df_f3_iso2c, by = 'iso2c') |>
mutate(`Top 10 Bottom 50 Ratio` = cut(T10B50, breaks = c(5, 12, 13, 16, 19, 140), include.lowest = FALSE)) |>
drop_na(`Top 10 Bottom 50 Ratio`) |>
ggplot(aes(map_id = region)) + geom_map(aes(fill = `Top 10 Bottom 50 Ratio`), map = world_map_iso2c) + expand_limits(x = world_map$long, y = world_map$lat) +
labs(title = "Figure 3. Top 10/Bottom 50 income gaps across the world, 2021",
x = "", y = "", fill = "Top 10/Bottom 50 ratio") +
theme(legend.position="bottom",
axis.text.x=element_blank(), axis.ticks.x=element_blank(),
axis.text.y=element_blank(), axis.ticks.y=element_blank()) +
scale_fill_brewer(palette='YlOrRd')
#> Warning in left_join(world_map_iso2c, df_f3_iso2c, by = "iso2c"): Detected an unexpected many-to-many relationship between
#> `x` and `y`.
#> ℹ Row 40866 of `x` matches multiple rows in `y`.
#> ℹ Row 2 of `y` matches multiple rows in `x`.
#> ℹ If a many-to-many relationship is expected, set
#> `relationship = "many-to-many"` to silence this warning.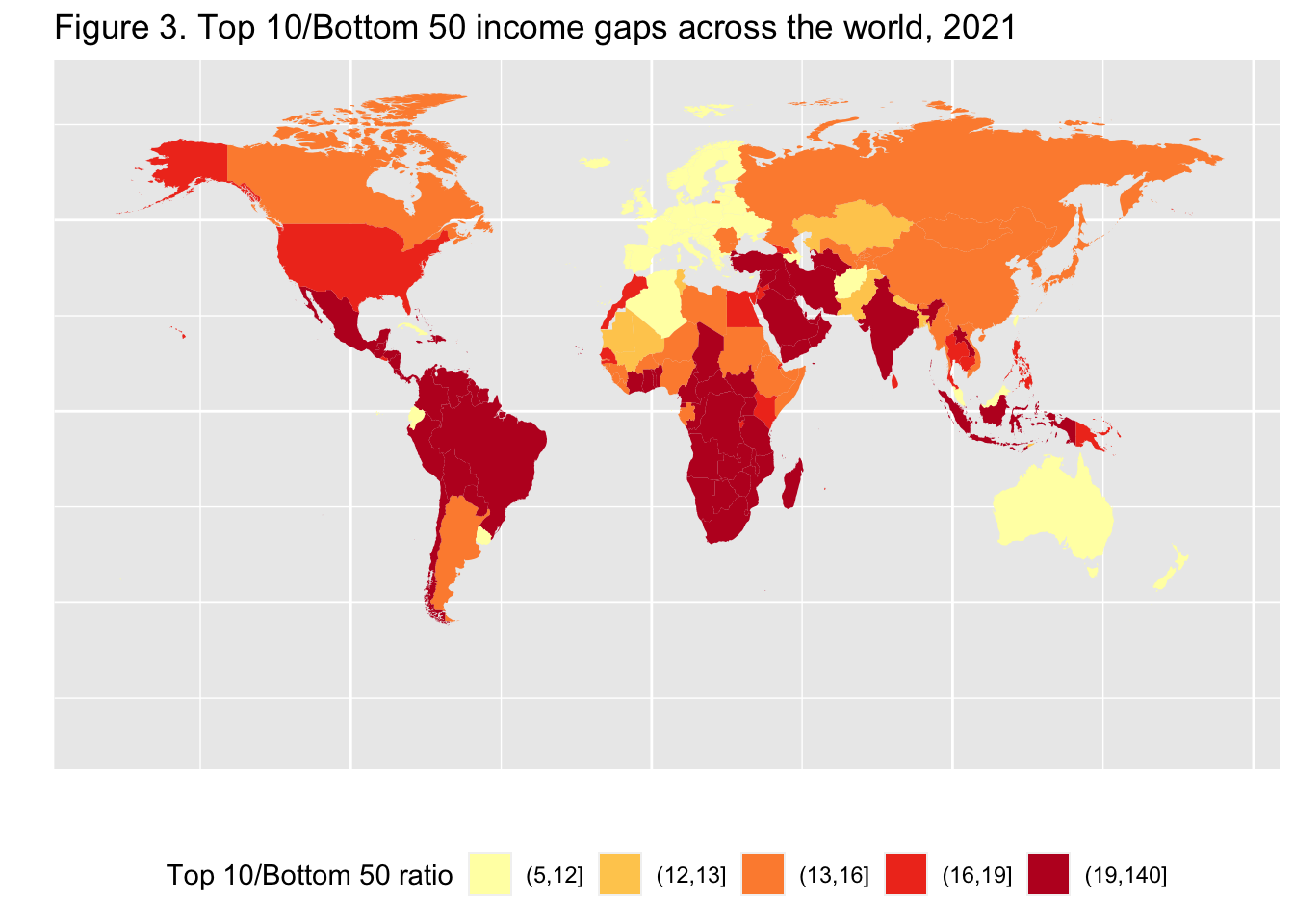
29.3.5 F4: 資本の極端な集中:世界全体の富の不平等、2021年
The extreme concentration of capital: wealth inequality across the world, 2021
df_f4 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F4")
df_f4
df_f4 |> pivot_longer(3:5, names_to = "level", values_to = "value") |>
ggplot(aes(x = iso, y = value, fill = level)) +
geom_col(position = "dodge") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 10)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 4. The extreme concentration of capital: \nwealth inequality across the world, 2021",
x = "", y = "Share of national wealth (%)", fill = "")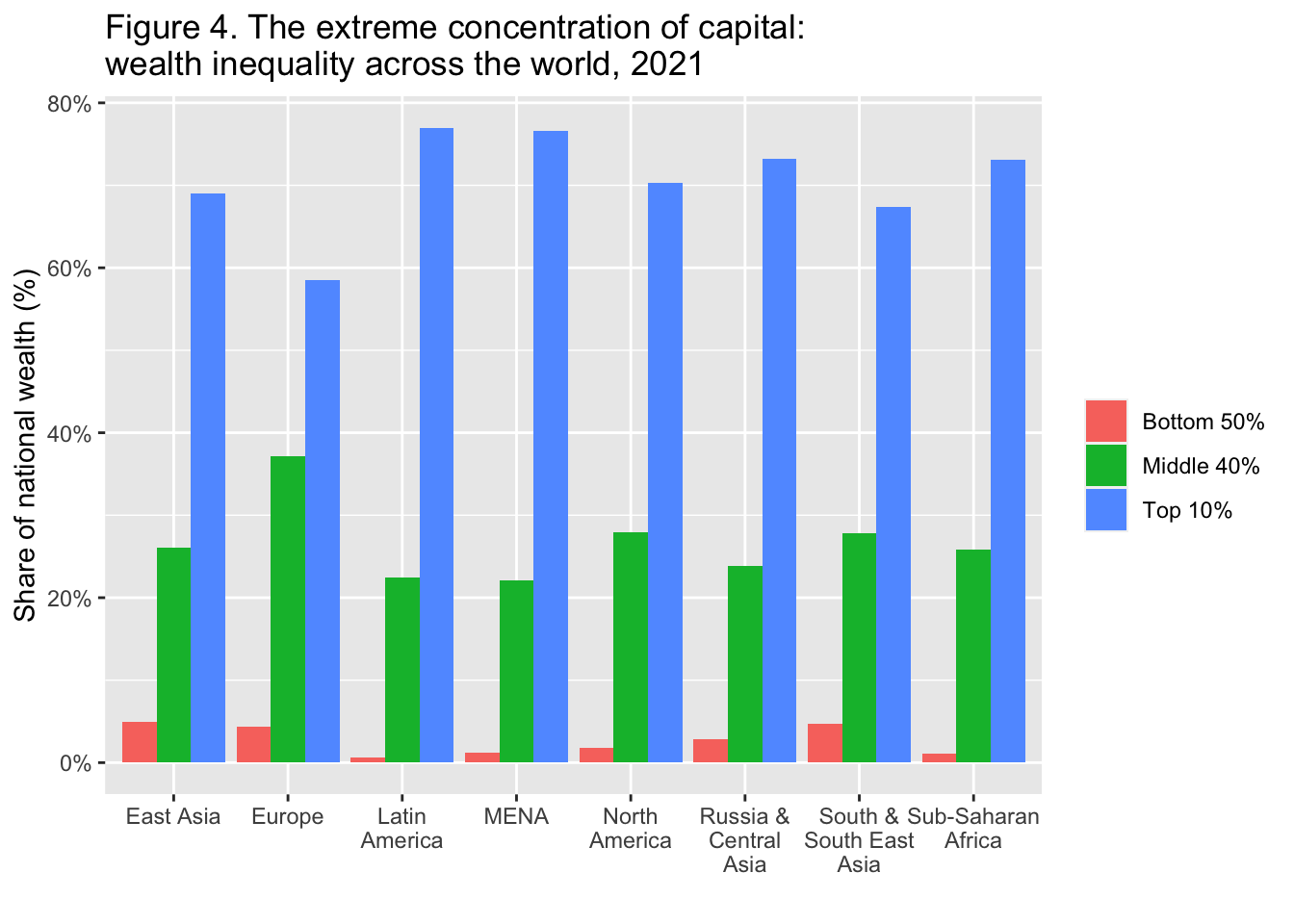
Interpretation: The Top 10% in Latin America captures 77% of total household wealth, versus 22% for the Middle 40% and 1% for the Bottom 50%. In Europe, the Top 10% owns 58% of total wealth, versus 38% for the Middle 40% and 4% for the Bottom 50%.
図の解釈: ラテンアメリカでは上位10%が家計総資産の77%を占めているのに対し、中位40%は22%、下位50%は1%である。ヨーロッパでは、上位10%が総資産の58%を所有しているのに対し、中位40%は38%、下位50%は4%である。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.6 F5: 世界の所得格差: T10/B50比、1820年-2020年
Global income inequality: T10/B50 ratio, 1820-2020
df_f5 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F5")
df_f5
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
lims(y = c(10,70)) +
geom_smooth(formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
labs(title = "Figure 5. Global income inequality:T10/B50 ratio, 1820-2020",
x = "", y = stringr::str_wrap("Ratio of top 10% average income to bottom 50% average income", width = 35)) +
annotate("text", x = 1840, y = 32, label = stringr::str_wrap("1820: average income of the global top 10% is 18x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 1910, y = 49, label = stringr::str_wrap("1910: average income of the global top 10% is 41x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 1980, y = 60, label = stringr::str_wrap("1980: average income of the global top 10% is 53x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 2010, y = 32, label = stringr::str_wrap("2020: average income of the global top 10% is 38x higher than average income of the bottom 50%", width = 20), size = 3)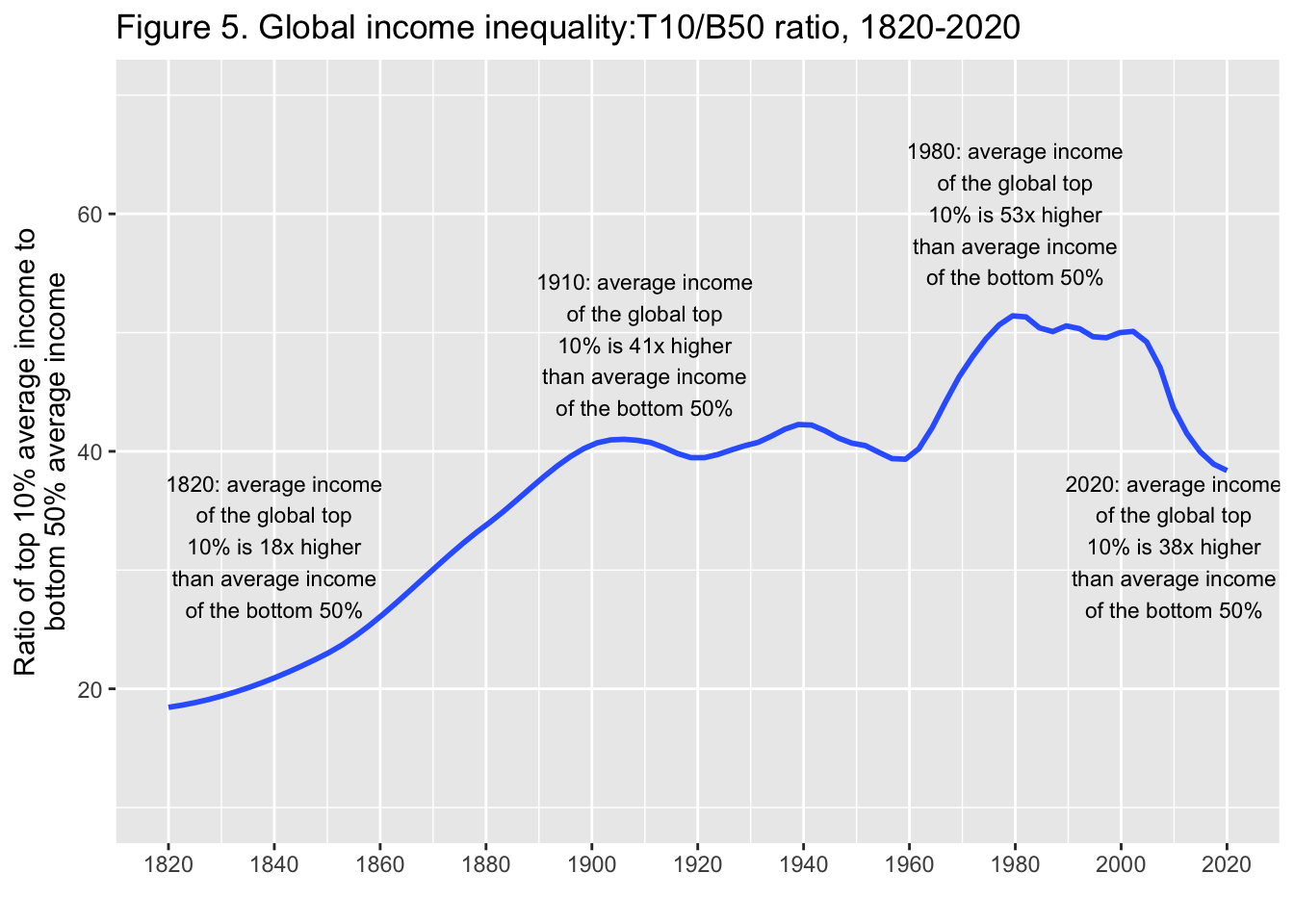
Interpretation. Global inequality, as measured by the ratio T10/B50 between the average income of the top 10% and the average income of the bottom 50%, more than doubled between between 1820 and 1910, from less than 20 to about 40, and stabilized around 40 between 1910 and 2020. It is too early to say whether the decline in global inequality observed since 2008 will continue. Income is measured per capita after pension and unemployement insurance transfers and before income and wealth taxes.
図の解釈: 世界の不平等は、上位10%の平均所得と下位50%の平均所得の比 T10/B50で測定され、1820年から1910年の間に、20未満から約40へと2倍以上に増加し、1910年から2020年の間に40前後で安定した。2008年以降に観察された世界的な不平等の減少が今後も続くかどうか を判断するのは時期尚早である。所得は、年金および失業保険給付後、所得税および富裕税課税前の1人当たりで測定されている。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Chancel and Piketty (2021)..
29.3.6.1 説明
29.3.6.1.1 Step 1.
- 基本的に、次で十分。Y 軸のラベルが長いので、
str_wrapで、折り返している。改行コード\nで折り返し場所を指定しても良い。
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
geom_line() +
labs(title = "Figure 5. Global income inequality:T10/B50 ratio, 1820-2020",
x = "", y = stringr::str_wrap("Ratio of top 10% average income to bottom 50% average income", width = 35))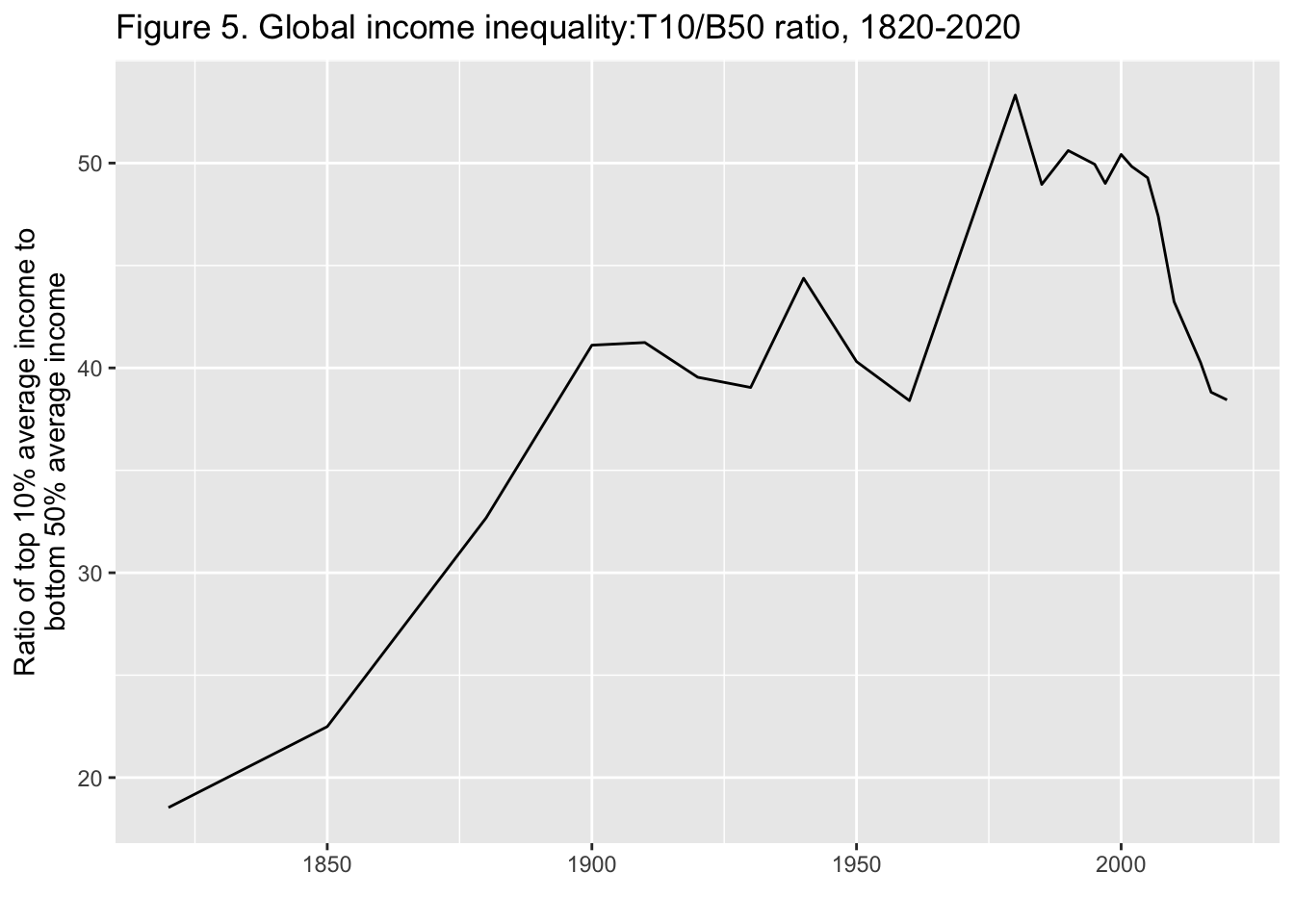
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
geom_line() +
labs(title = "Figure 5. Global income inequality:T10/B50 ratio, 1820-2020",
x = "", y = "Ratio of top 10% average income to \nbottom 50% average income")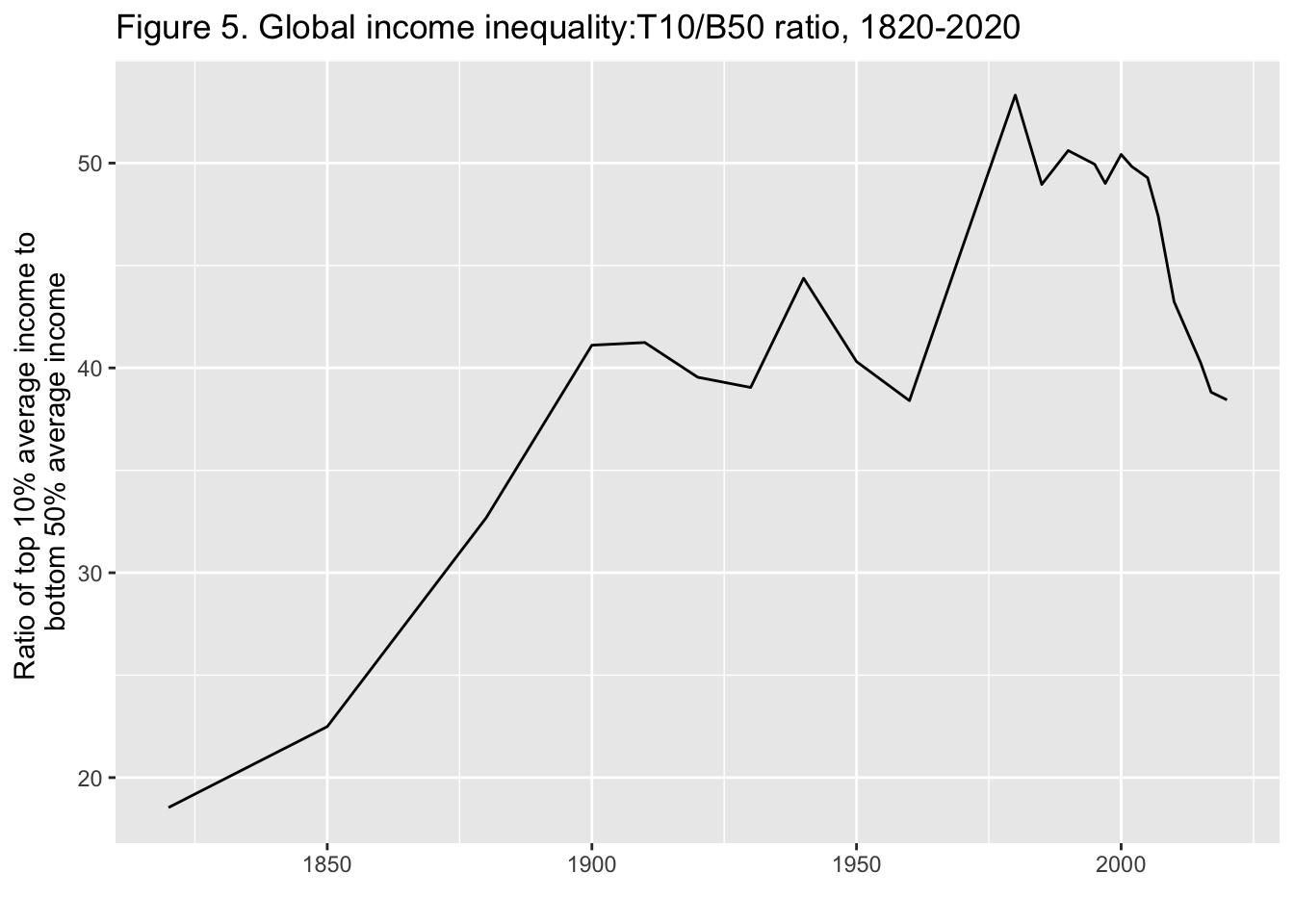
29.3.6.1.2 Step 2.
なめらかな曲線にする方法はいくつもある。基本的には、geom_smooth() を使い、formula = y~x と、method を指定し、必要に応じて、パラメター span などを設定する。se = TRUE (初期値はこのようになっている)とすると、標準誤差の帯が表示される。信頼誤差(level of confidence)は、level で指定できる。初期値は、0.95。
折れ線グラフと局所回帰(Line Plot and LOESS(locally estimated scatterplot smoothing))
- method の初期値は “loess” で
se = TRUEになっている。 - 十分理解できるまでは次を使用:
formula = y~x,method = "loess", andse = FALSE`. - 下では、他の方法も例示する。
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
geom_line() +
geom_smooth(formula = y~x, method = "loess", se = FALSE) +
labs(title = "Figure 5. Global income inequality:",
subtitle = "T10/B50 ratio, 1820-2020",
x = "", y = "Ratio of top 10% average income to bottom 50% average income")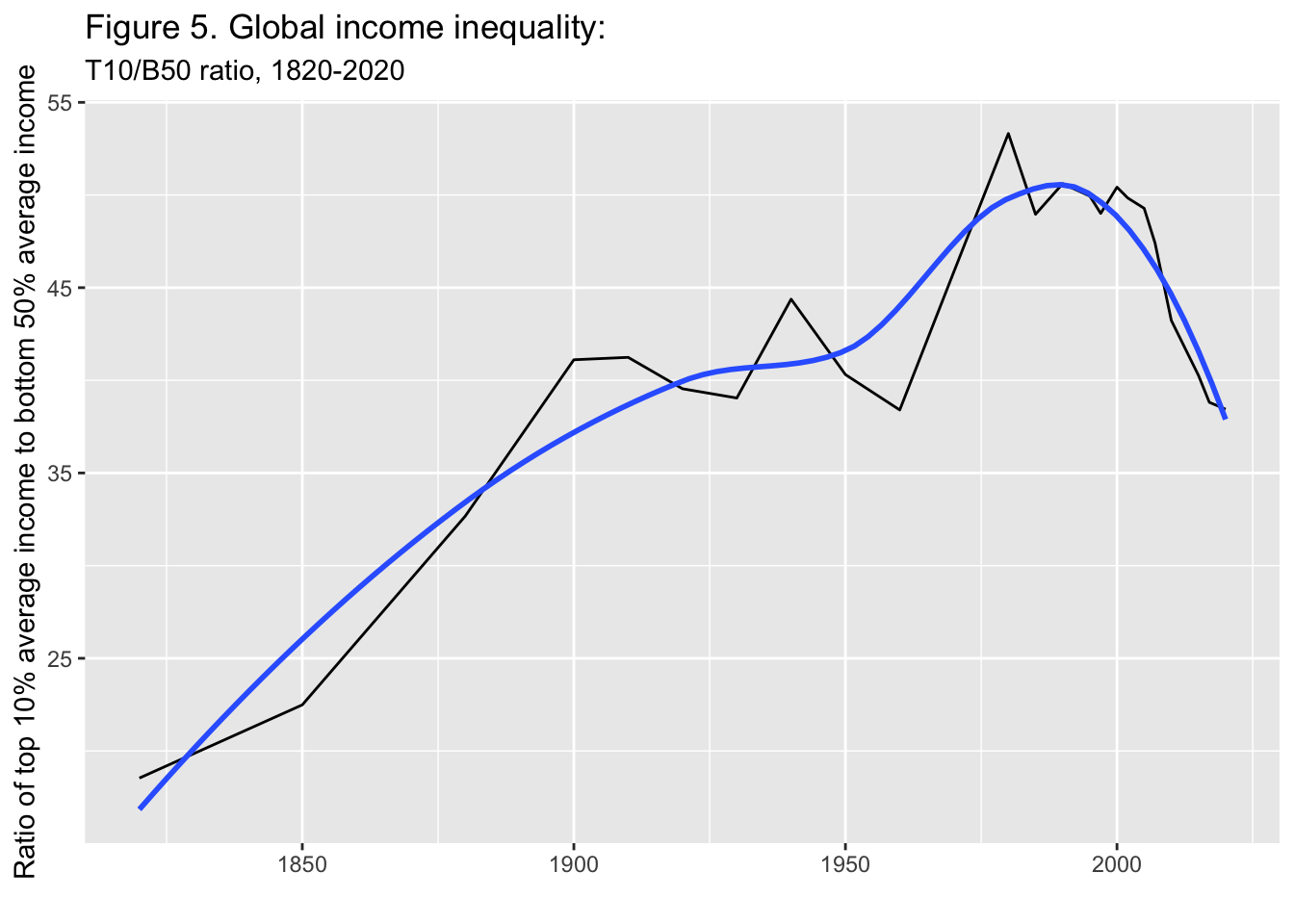
24点での GAM(General Additive Model)近似
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
stat_smooth(method = "gam", formula = y ~ s(x, k = 24), se = FALSE) +
scale_x_continuous(breaks = round(seq(min(df_f5$y), max(df_f5$y), by = 20),1)) +
labs(title = "Figure 5. Global income inequality:T10/B50 ratio, 1820-2020",
x = "", y = stringr::str_wrap("Ratio of top 10% average income to bottom 50% average income", width = 35))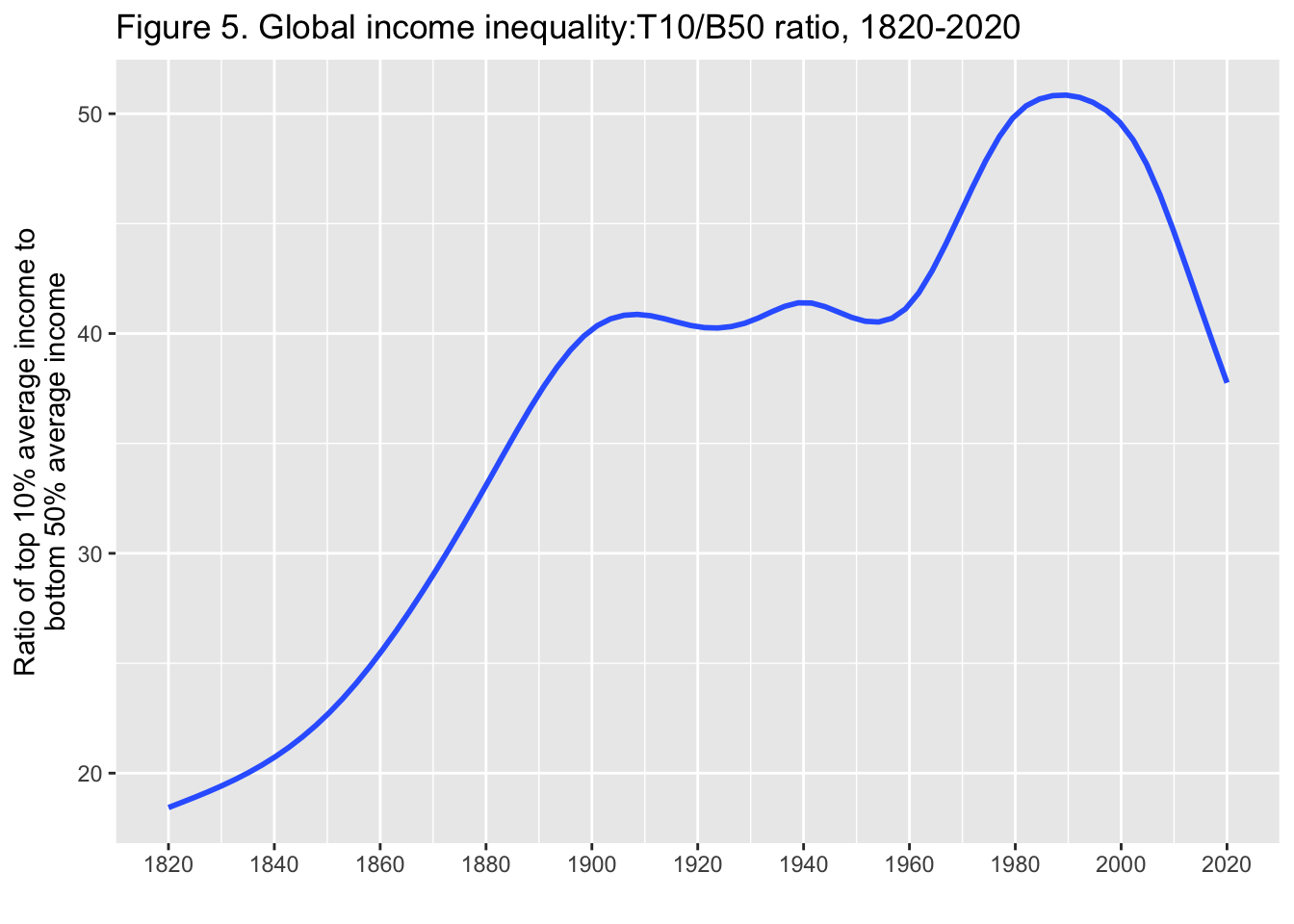
6次多項式近似
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ poly(x, 6), se = FALSE) +
labs(title = "Figure 5. Global income inequality:",
subtitle = "T10/B50 ratio, 1820-2020",
x = "", y = stringr::str_wrap("Ratio of top 10% average income to bottom 50% average income", width = 35))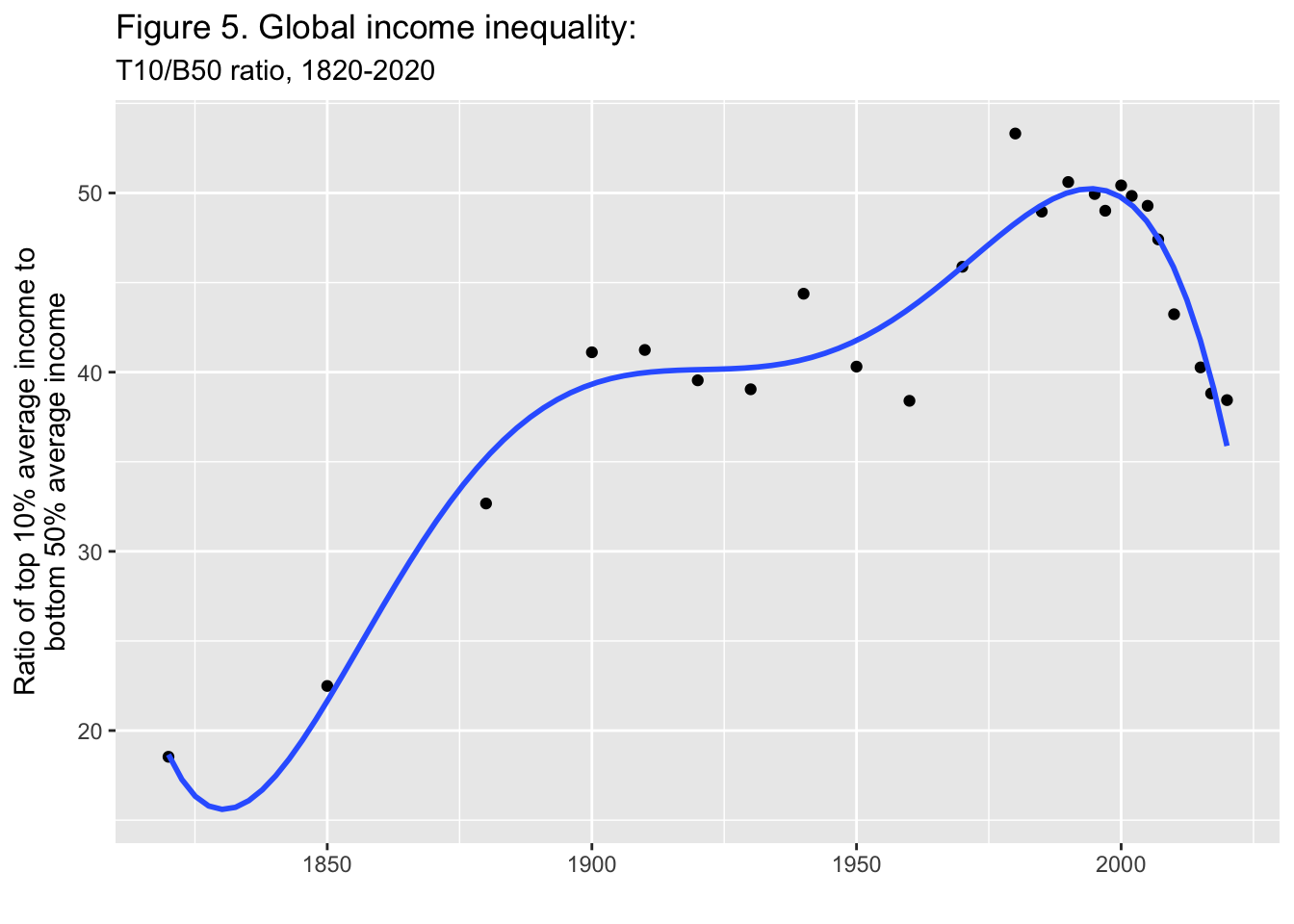
29.3.6.1.3 Step 3.
F5 の描画では, 次を使用:
geom_smooth(formula = y~x, method = "loess", span = 0.25, se = FALSE)spanの値を変更すれば、なめらかさを変えることができる。実際の図に合わせて Y 軸の範囲を
lims(y = c(10,70))で修正。長いテキストは、str_wrap を使い、注釈(
annotate)を挿入、文字の大きさは、size = fontsizeで調整:stringr::str_wrap("long text", width = size)and withsize = fontsize.ggforce::geom_mark_rectによって注釈を長方形で挿入。
df_f5 |> select(year = y, ratio = t10b50) |>
ggplot(aes(x = year, y = ratio)) +
lims(y = c(10,70)) +
geom_smooth(formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
labs(title = "Figure 5. Global income inequality:T10/B50 ratio, 1820-2020",
x = "", y = stringr::str_wrap("Ratio of top 10% average income to bottom 50% average income", width = 35)) +
annotate("text", x = 1840, y = 32, label = stringr::str_wrap("1820: average income of the global top 10% is 18x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 1910, y = 49, label = stringr::str_wrap("1910: average income of the global top 10% is 41x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 1980, y = 60, label = stringr::str_wrap("1980: average income of the global top 10% is 53x higher than average income of the bottom 50%", width = 20), size = 3) +
annotate("text", x = 2010, y = 32, label = stringr::str_wrap("2020: average income of the global top 10% is 38x higher than average income of the bottom 50%", width = 20), size = 3)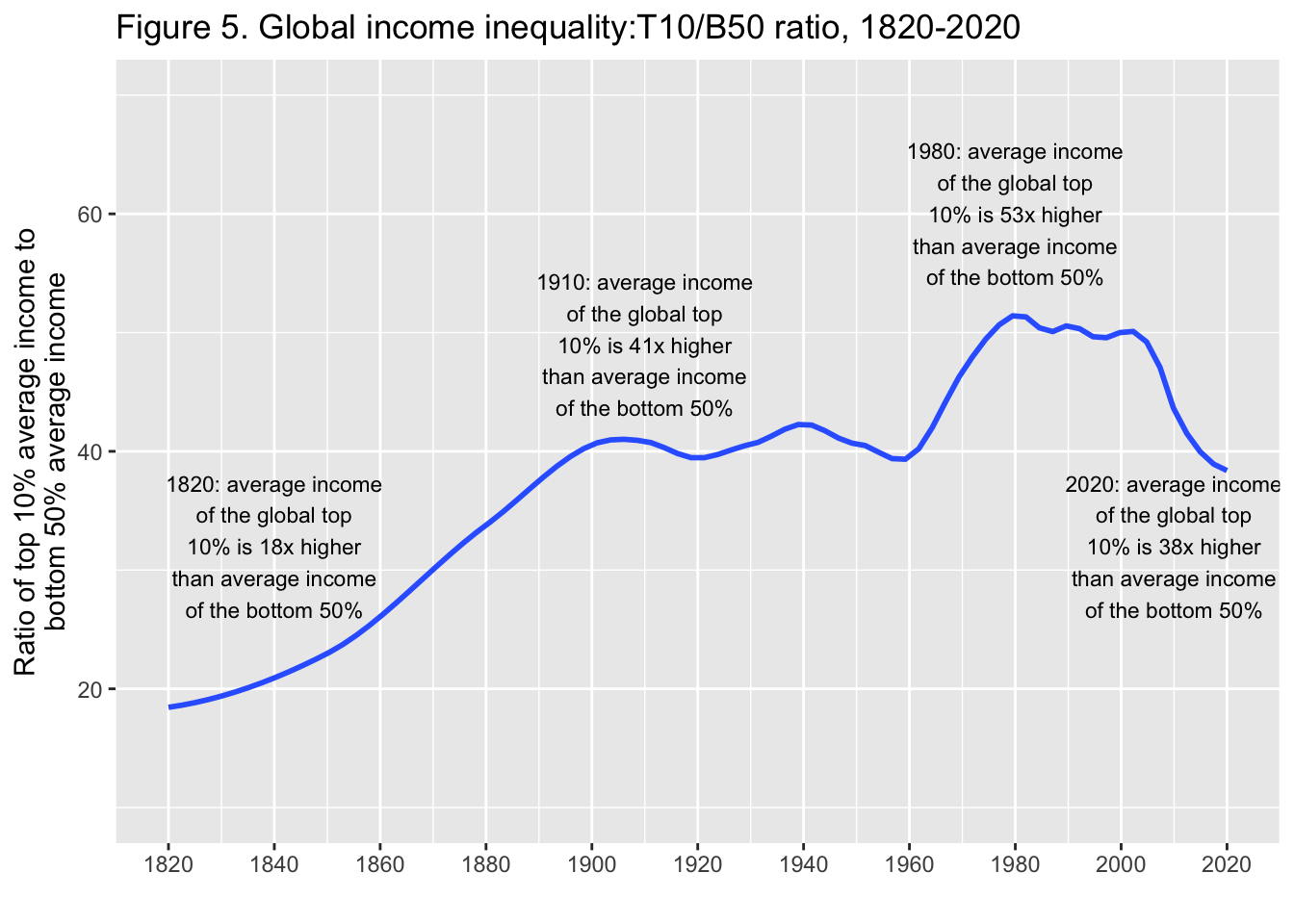
29.3.7 F6: 世界の所得格差: 国間不平等と国内不平等(Theil指数)、1820-2020年
Global income inequality: Between vs. Within country inequality (Theil index), 1820-2020
df_f6 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F6")
#> New names:
#> • `` -> `...1`
df_f6
df_f6 |> select(year = "...1", 2:3) |>
pivot_longer(cols = 2:3, names_to = "type", values_to = "value") |>
mutate(types = factor(type, levels = c("Within-country inequality", "Between-country inequality"))) |>
ggplot(aes(x = year, y = value, fill = types)) +
geom_area() +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
scale_fill_manual(values=rev(scales::hue_pal()(2)), labels = function(x) str_wrap(x, width = 15)) +
labs(title = "Figure 6. Global income inequality: \nBetween vs. within country inequality (Theil index), 1820-2020",
x = "", y = "Share of global inequality (% of total Theil index)", fill = "") +
annotate("text", x = 1850, y = 0.28, label = stringr::str_wrap("1820: Between country inequality represents 11% of global inequality", width = 20), size = 3) +
annotate("text", x = 1980, y = 0.70, label = stringr::str_wrap("1980: Between country inequality represents 57% of global inequality", width = 20), size = 3) +
annotate("text", x = 1990, y = 0.30, label = stringr::str_wrap("2020: Between country inequality represents 32% of global inequality", width = 20), size = 3)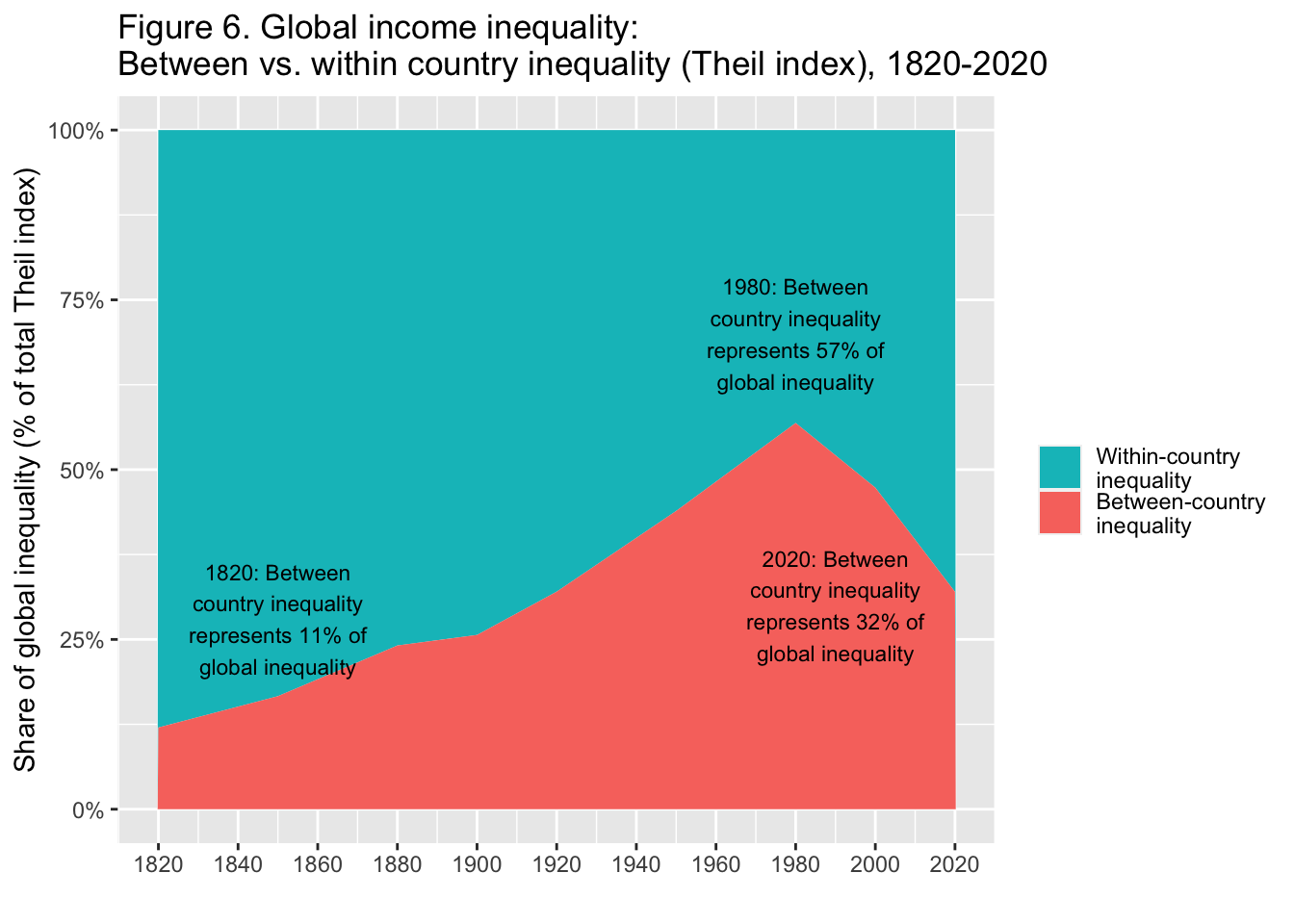
- 凡例を下にしたい場合は
themeを利用:theme(legend.position="bottom")
df_f6 |> select(year = "...1", 2:3) |>
pivot_longer(cols = 2:3, names_to = "type", values_to = "value") |>
mutate(types = factor(type, levels = c("Within-country inequality", "Between-country inequality"))) |>
ggplot(aes(x = year, y = value, fill = types)) +
geom_area() +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
scale_fill_manual(values=rev(scales::hue_pal()(2))) +
labs(title = "Figure 6. Global income inequality: \nBetween vs. within country inequality (Theil index), 1820-2020",
x = "", y = "Share of global inequality (% of total Theil index)", fill = "") +
annotate("text", x = 1850, y = 0.28, label = stringr::str_wrap("1820: Between country inequality represents 11% of global inequality", width = 20), size = 3) +
annotate("text", x = 1980, y = 0.70, label = stringr::str_wrap("1980: Between country inequality represents 57% of global inequality", width = 20), size = 3) +
annotate("text", x = 1990, y = 0.30, label = stringr::str_wrap("2020: Between country inequality represents 32% of global inequality", width = 20), size = 3) +
theme(legend.position="bottom")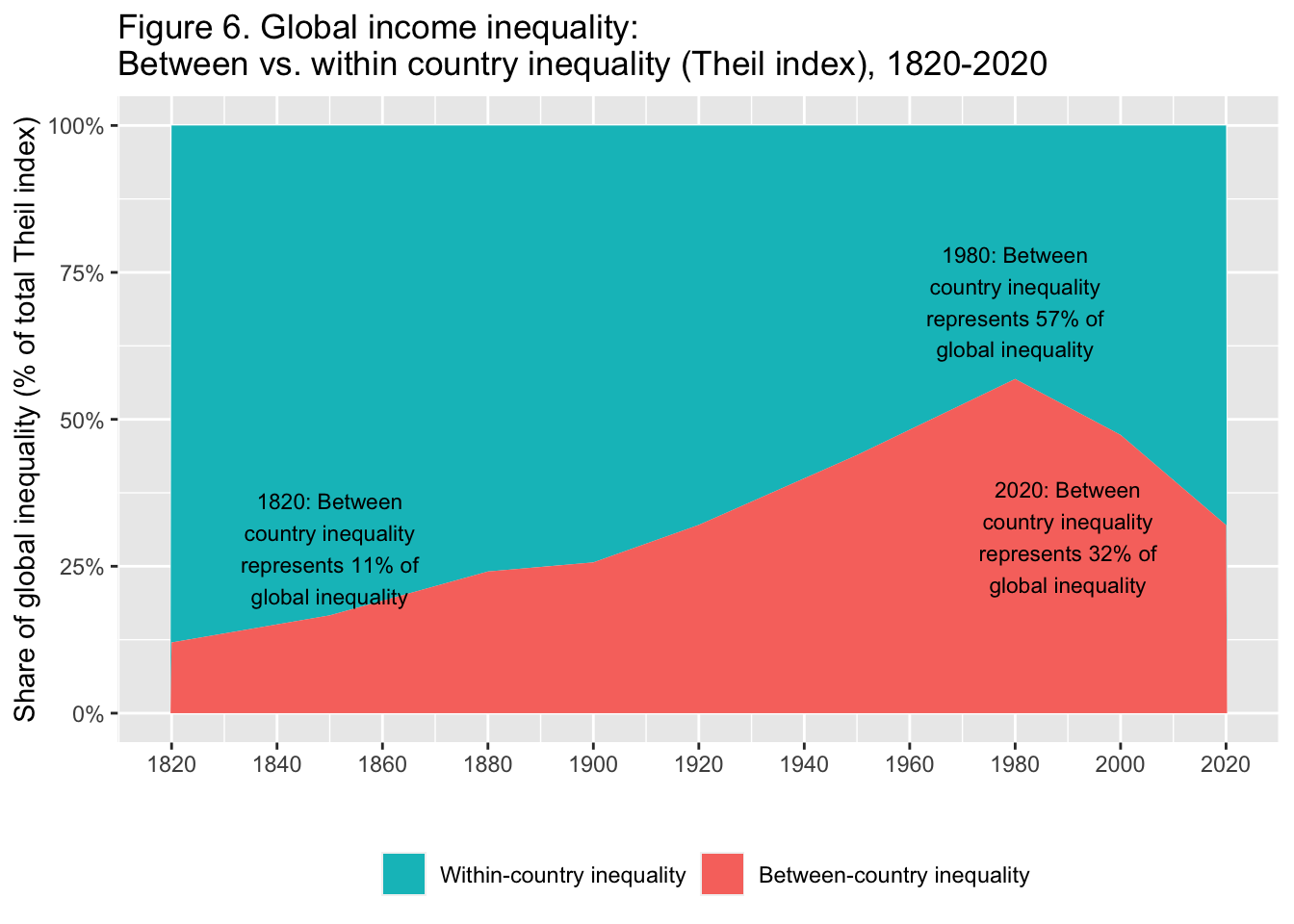
Interpretation. The importance of between-country inequality in overall global inequality, as measured by the Theil index, rose between 1820 and 1980 and strongly declined since then. In 2020, between-country inequality makes-up about a third of global inequality between individuals. The rest is due to inequality within countries. Income is measured per capita after pension and unemployement insurance transfers and before income and wealth taxes.
図の解釈: Theil指数によって測定された、世界全体の不平等における国間不平等の重要性は、1820年から1980年の間に上昇し、それ以降は強く低下した。2020年には、個人間の不平等が世界の不平等の約3分の1を占めるようになる。残りは国内の不平等によるものである。所得は、年金と失業保険給付後、所得税と富裕税課税前の1人当たりで測定されている。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Chancel and Piketty (2021).
29.3.7.1 説明
29.3.7.1.1 Step 1.
- まず
pilot_longerで、データを整えてから、geom_areaを利用。
df_f6 |> select(year = "...1", 2:3) |>
pivot_longer(cols = 2:3, names_to = "type", values_to = "value") |>
ggplot(aes(x = year, y = value, fill = type)) +
geom_area() +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 6. Global income inequality: \nBetween vs. within country inequality (Theil index), 1820-2020",
x = "", y = "Share of global inequality (% of total Theil index)")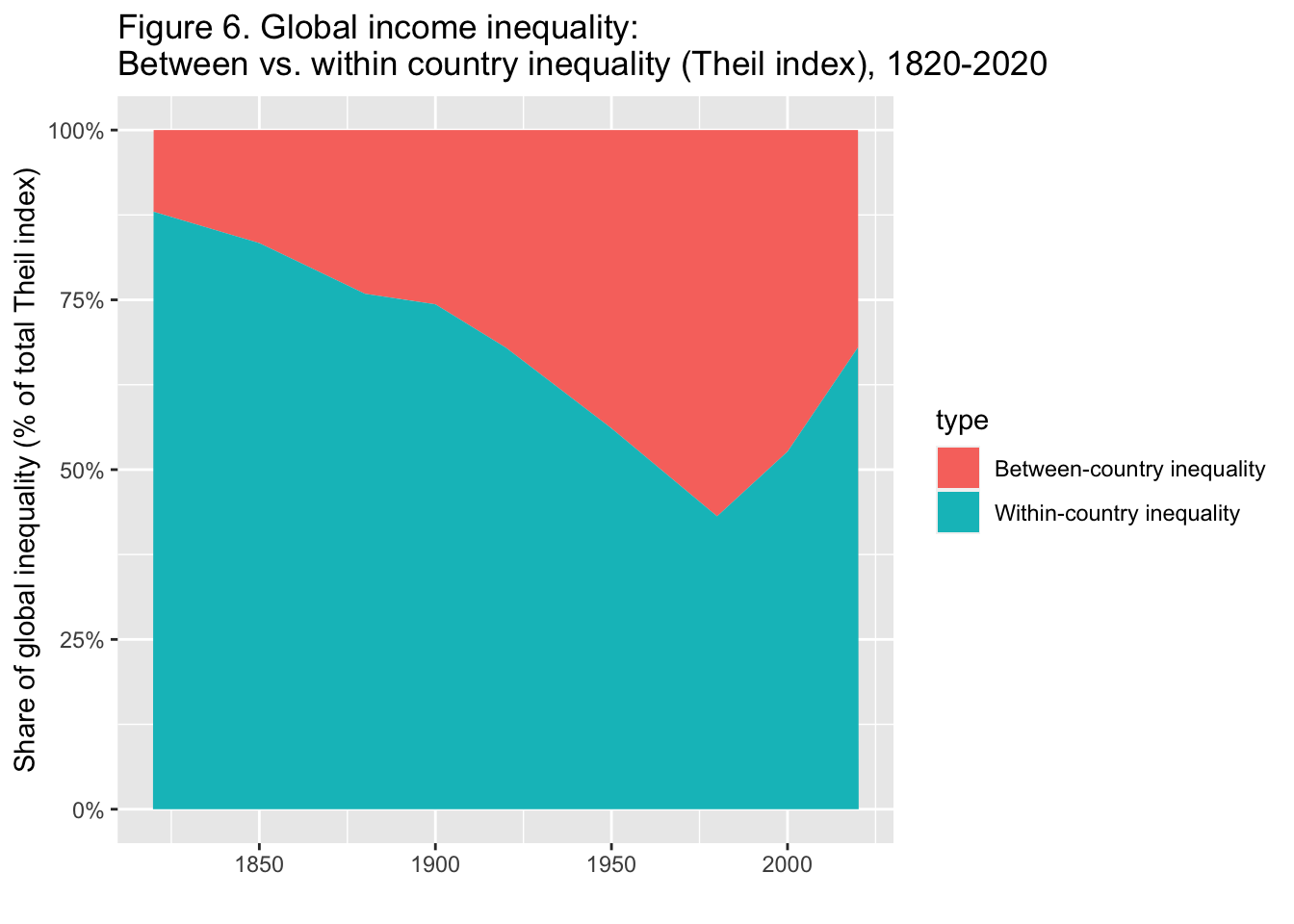
29.3.7.1.2 Step 2.
- グループの順序を変えたいのと、凡例が長いので、折り返すために、下の部分を挿入。
scale_fill_manual(values=rev(scales::hue_pal()(2)), labels = function(x) str_wrap(x, width = 15))RMarkdown で説明を加えるのであれば、注釈を図に加えることはしなくても良いかもしれない。
Y 軸のラベルを、パーセントにし、X 軸のらべるを調整する。
df_f6 |> select(year = "...1", 2:3) |>
pivot_longer(cols = 2:3, names_to = "type", values_to = "value") |>
mutate(types = factor(type, levels = c("Within-country inequality", "Between-country inequality"))) |>
ggplot(aes(x = year, y = value, fill = types)) +
geom_area() +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
scale_fill_manual(values=rev(scales::hue_pal()(2)), labels = function(x) str_wrap(x, width = 15)) +
labs(title = "Figure 6. Global income inequality: \nBetween vs. within country inequality (Theil index), 1820-2020",
x = "", y = "Share of global inequality \n(% of total Theil index)", fill = "")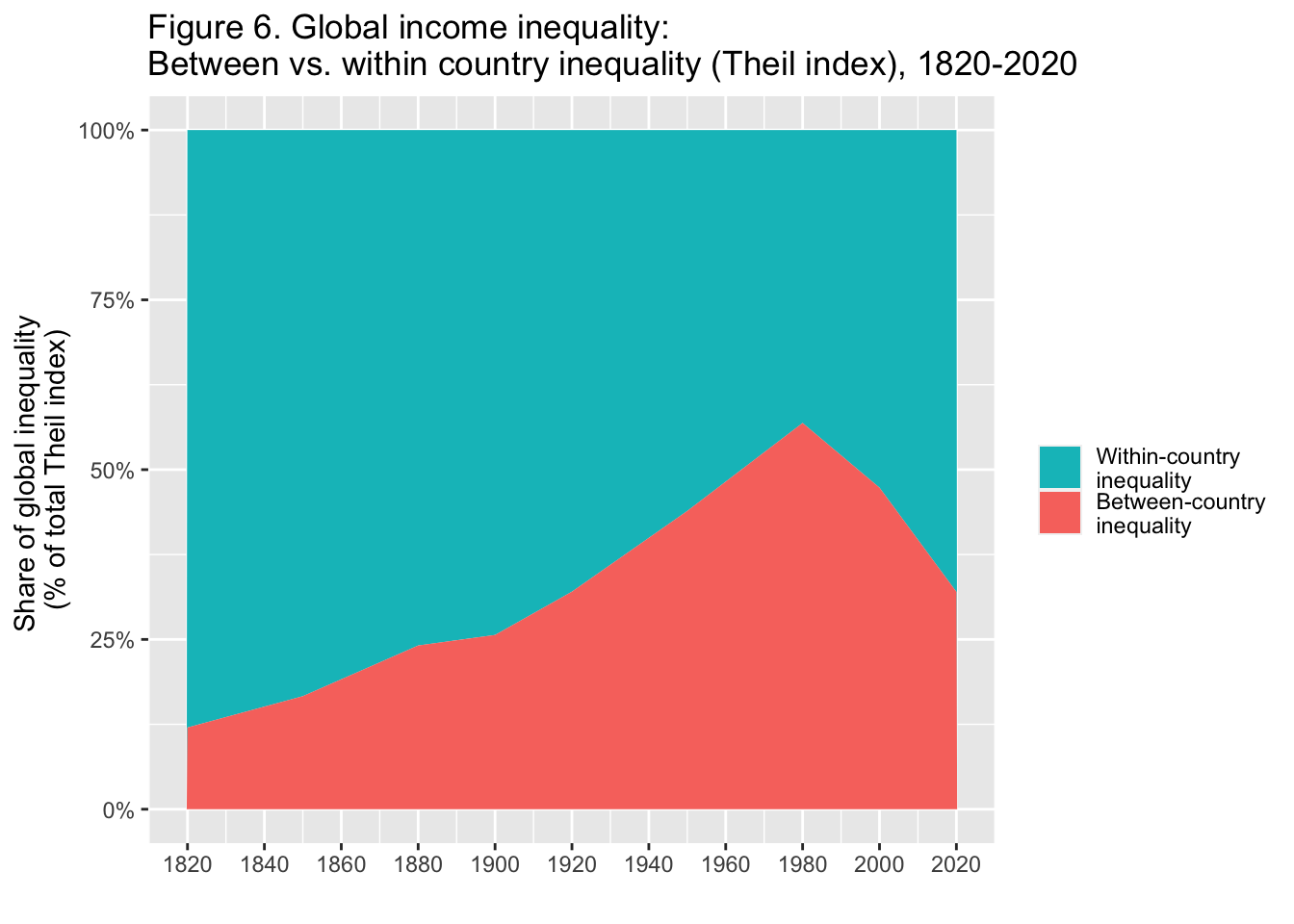
単に、type の順序を逆にして、色の順番を変えるだけなら、fill = fct_rev(type) と、scale_fill_hue(direction = -1, labels = function(x) str_wrap(x, width = 15)) も一つです。この場合は二種類でしたから、順序はそのままか逆にするかでしたが、順序を自由に変えるには、上で示した ように、factor で、levels を指定する方法のほうが良いでしょう。
df_f6 |> select(year = "...1", 2:3) |>
pivot_longer(cols = 2:3, names_to = "type", values_to = "value") |>
ggplot(aes(x = year, y = value, fill = fct_rev(type))) +
geom_area() +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_fill_hue(direction = -1, labels = function(x) str_wrap(x, width = 15)) +
labs(title = "Figure 6. Global income inequality: \nBetween vs. within country inequality (Theil index), 1820-2020",
x = "", y = "Share of global inequality \n(% of total Theil index)",
fill = "")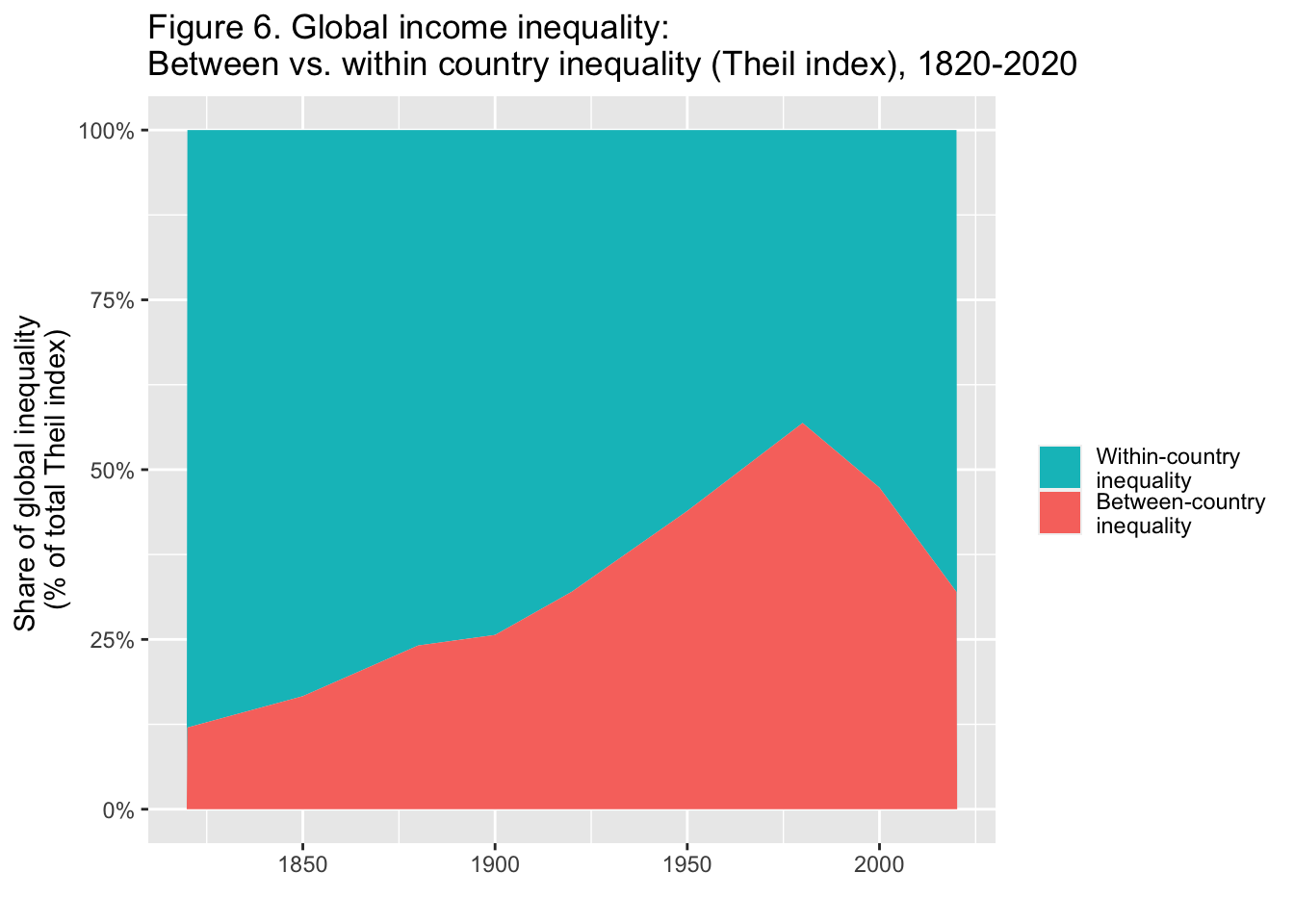
29.3.8 F7: 世界の所得格差、1820-2020年
Global income inequality, 1820-2020
df_f7 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F7")
df_f7
df_f7 |> select(year = y, 2:4) |>
pivot_longer(cols = 2:4, names_to = "type", values_to = "value") |>
ggplot(aes(x = year, y = value, color = type)) +
geom_smooth(formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 7. Global income inequality, 1820-2020",
x = "", y = " Share of total world income (%)", color = "") +
annotate("text", x = 1980, y = 0.20, label = stringr::str_wrap("The global bottom 50% income share remains historically low despite growth in the emerging world in the past decades.", width = 30), size = 3)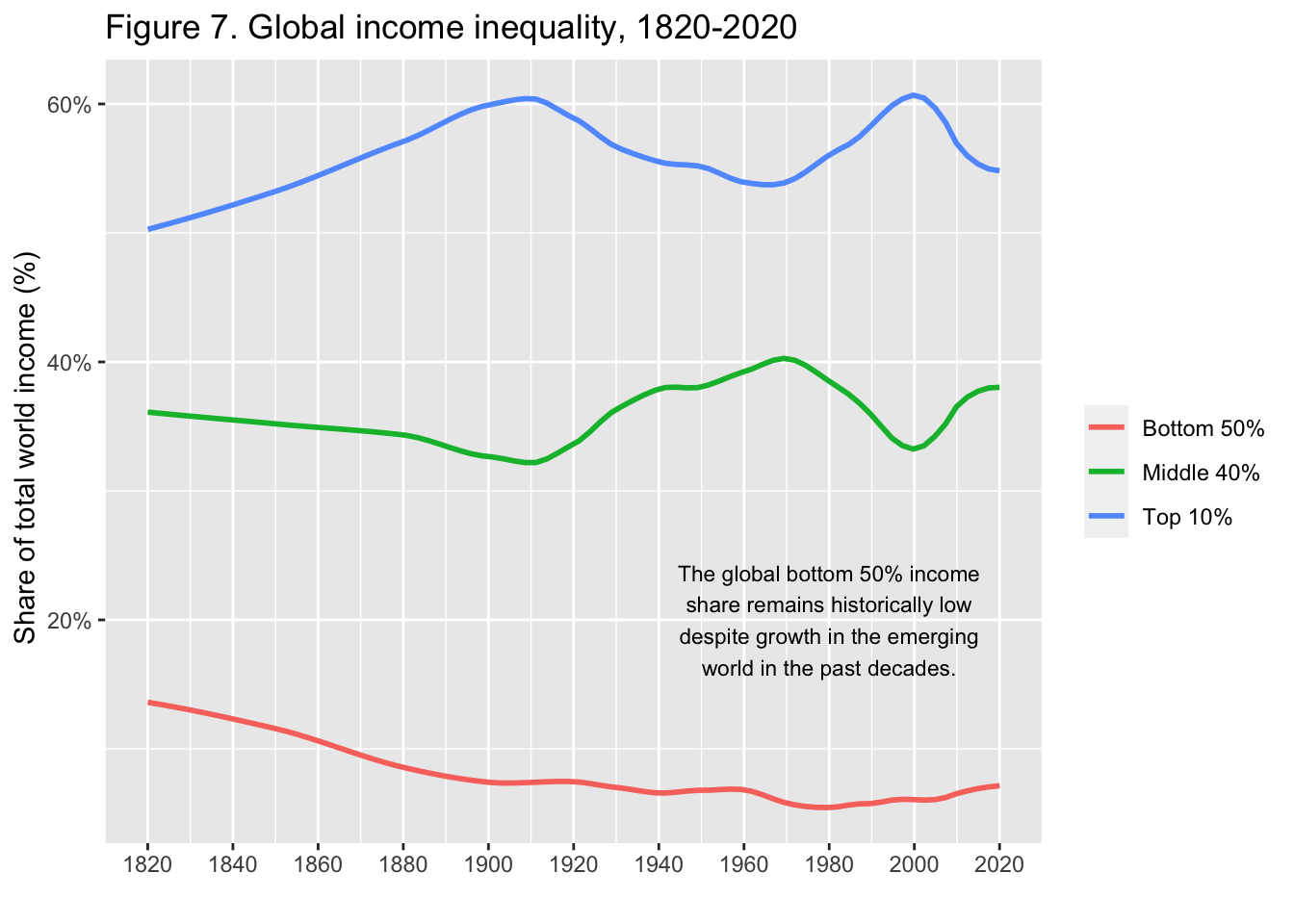
Interpretation. The share of global income going to top 10% highest incomes at the world level has fluctuated around 50-60% between 1820 and 2020 (50% in 1820, 60% in 1910, 56% in 1980, 61% in 2000, 55% in 2020), while the share going to the bottom 50% lowest incomes has generally been around or below 10% (14% in 1820, 7% in 1910, 5% in 1980, 6% in 2000, 7% in 2020). Global inequality has always been very large. It rose between 1820 and 1910 and shows little long-run trend between 1910 and 2020. Distribution of per capita incomes.
図の解釈: 世界所得に占める上位10%の高額所得者の割合は、1820年から2020年にかけて50~60%前後で変動している(1820年:50%、1910年:60%、1980年:56%、2000年:61%、2020年:55%)が、下位50%の低額所得者の割合は概ね10%前後かそれ以下である(1820年:14%、1910年:7%、1980年:5%、2000年:6%、2020年:7%)。世界の不平等は常に非常に大きい。1820年から1910年にかけて上昇し、1910年から2020年にかけては長期的なトレンドはほとんど見られない。一人当たり所得の分布。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Chancel and Piketty (2021).
29.3.8.1 説明
29.3.8.1.1 Step 1.
- pivot_longer() 適用し、tidy データに変換
df_f7 |> select(year = y, 2:4) |>
pivot_longer(cols = 2:4, names_to = "type", values_to = "value") 29.3.8.1.2 Step 2.
-
geom_smoothとspanを使って、なめらかな曲線で近似し、X 軸と、Y 軸のラベルを調整。
df_f7 |> select(year = y, 2:4) |>
pivot_longer(cols = 2:4, names_to = "type", values_to = "value") |>
ggplot(aes(x = year, y = value, color = type)) +
geom_smooth(formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1820, 2020, by = 20),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 7. Global income inequality, 1820-2020",
x = "", y = " Share of total world income (%)", color = "")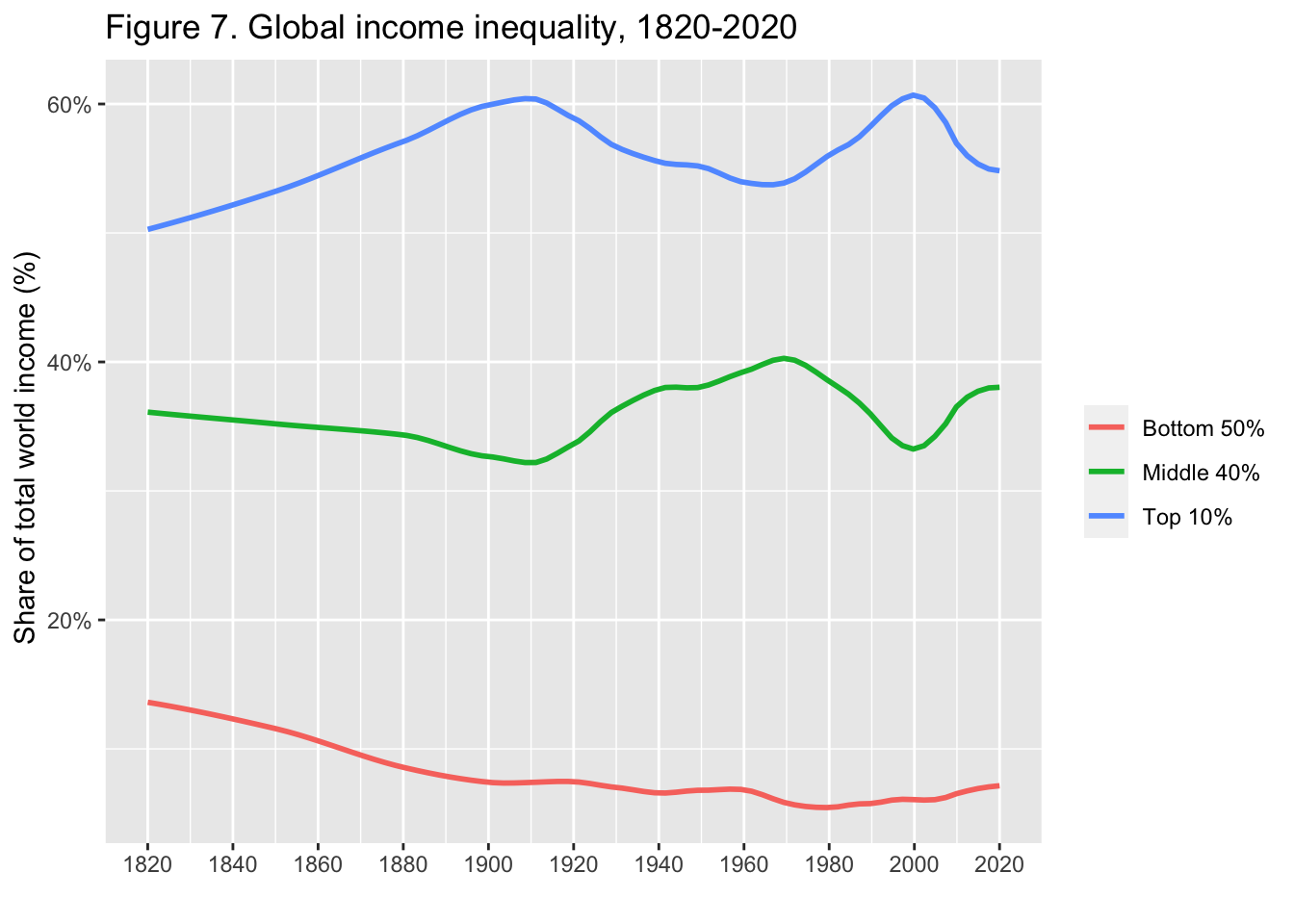
- 最後に、注釈を追加する。
29.3.9 F8: 富裕国における私的富の増加と公的富の減少(1970-2020年)
The rise of private versus the decline of public wealth in rich countries, 1970-2020
df_f8 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F8")
df_f8
df_f8 |> drop_na() |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') |>
pivot_longer(!year, names_to = c("country",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
stat_smooth(aes(x = year, y = value, color = country, linetype = type),
formula = y~x, method = "loess",
span = 0.25, se = FALSE, size=0.75) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 8. The rise of private versus the decline of \npublic wealth in rich countries, 1970-2020",
x = "", y = "wealth as % of national income", color = "", type = "")
#> Warning: Using `size` aesthetic for lines was deprecated in ggplot2
#> 3.4.0.
#> ℹ Please use `linewidth` instead.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where
#> this warning was generated.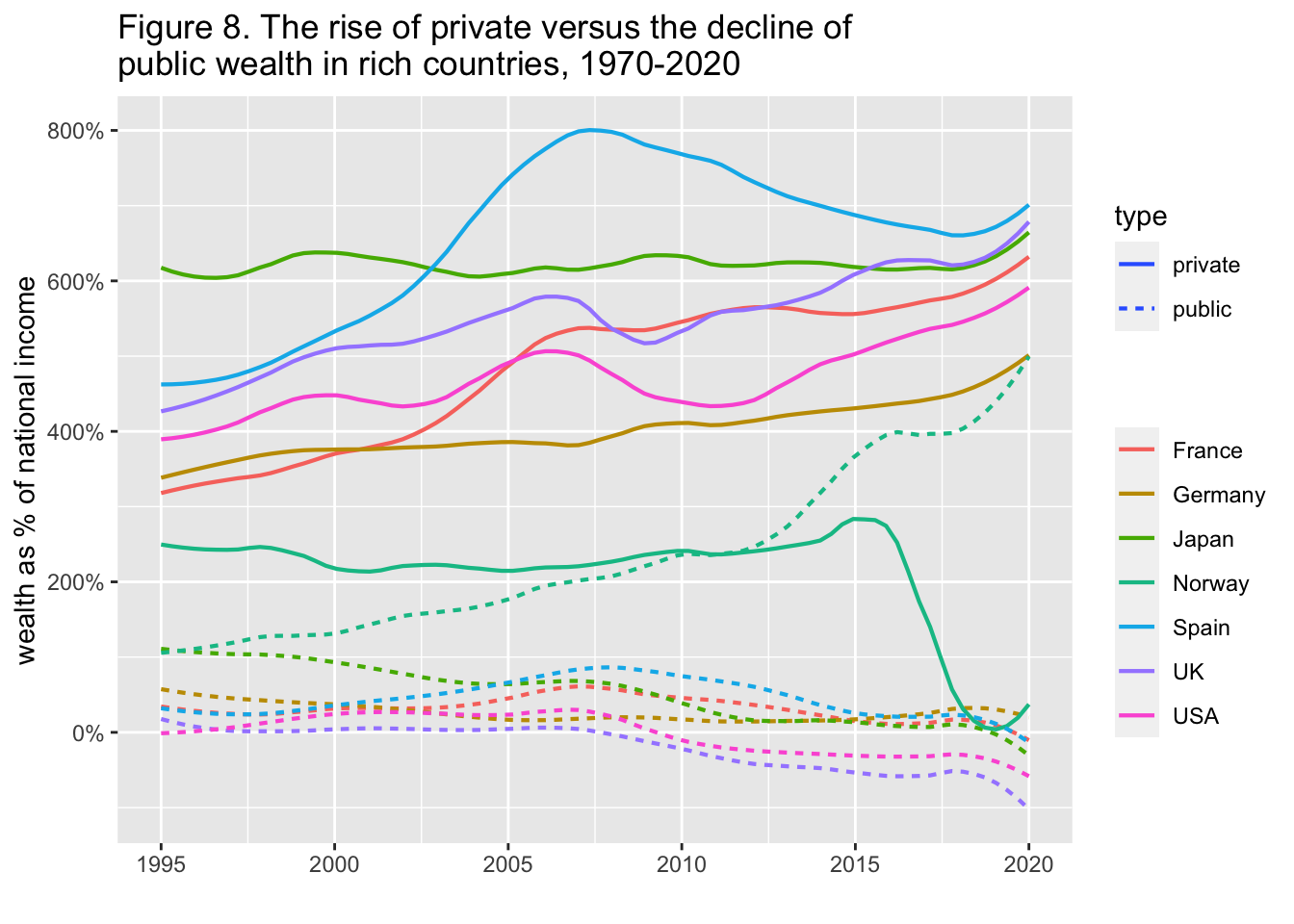
Interpretation: Public wealth is the sum of all financial and non-financial assets, net of debts, held by governments. Public wealth dropped from 60% of national income in 1970 to -106% in 2020 in the UK.
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Bauluz et al. (2021) と更新情報.
29.3.9.1 説明
29.3.9.1.1 Step 1.
- それぞれの、countries において、public と private というグループに分かれているので、まずは、列名を、変更しやすいように、下線 ‘_’ で分けることにする。最後の二列 “gwealAVGRICH”、“pwealAVGRICH” は、使わないので、削除。
df_f8 |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') 29.3.9.1.2 Step 2.
- まずは、国を分け、poublic と private を分ける。次のオプションを利用
names_sep = "_".
df_f8 |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') |>
pivot_longer(!year, names_to = c("country",".value"), names_sep = "_") 29.3.9.1.3 Step 3.
- つぎに
pivot_longerを使って、次のグループを作成
df_f8 |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') |>
pivot_longer(!year, names_to = c("country",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value")29.3.9.1.4 Step 4.
- 色と、線の種類
linetypeを使って、グループを区別する。
df_f8 |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') |>
pivot_longer(!year, names_to = c("country",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = country, linetype = type),
formula = y~x, method = "loess", span = 0.25, se = FALSE)
#> Warning: Removed 50 rows containing non-finite values
#> (`stat_smooth()`).
29.3.9.1.5 Step 5.
- たくさん NA’s があるので、
drop_na()を使って、削除。 - 線の太さは
sizeで変更し、Y 軸を百分率に、また、表題を追加。
df_f8 |> drop_na() |>
select(year, Germany_public = Germany, Germany_private = 'Germany (private)',
Spain_public = Spain, Spain_private = 'Spain (private)',
France_public = France, France_private = 'France (private)',
UK_public = UK, UK_private = 'UK (private)',
Japan_public = Japan, Japan_private = 'Japan (private)',
Norway_public = Norway, Norway_private = 'Norway (private)',
USA_public = USA, USA_private = 'USA (private)') |>
pivot_longer(!year, names_to = c("country",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = country, linetype = type),
formula = y~x, method = "loess",
span = 0.25, se = FALSE, size=0.75) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 8. The rise of private versus the decline of \npublic wealth in rich countries, 1970-2020",
x = "", y = "wealth as % of national income", color = "", type = "")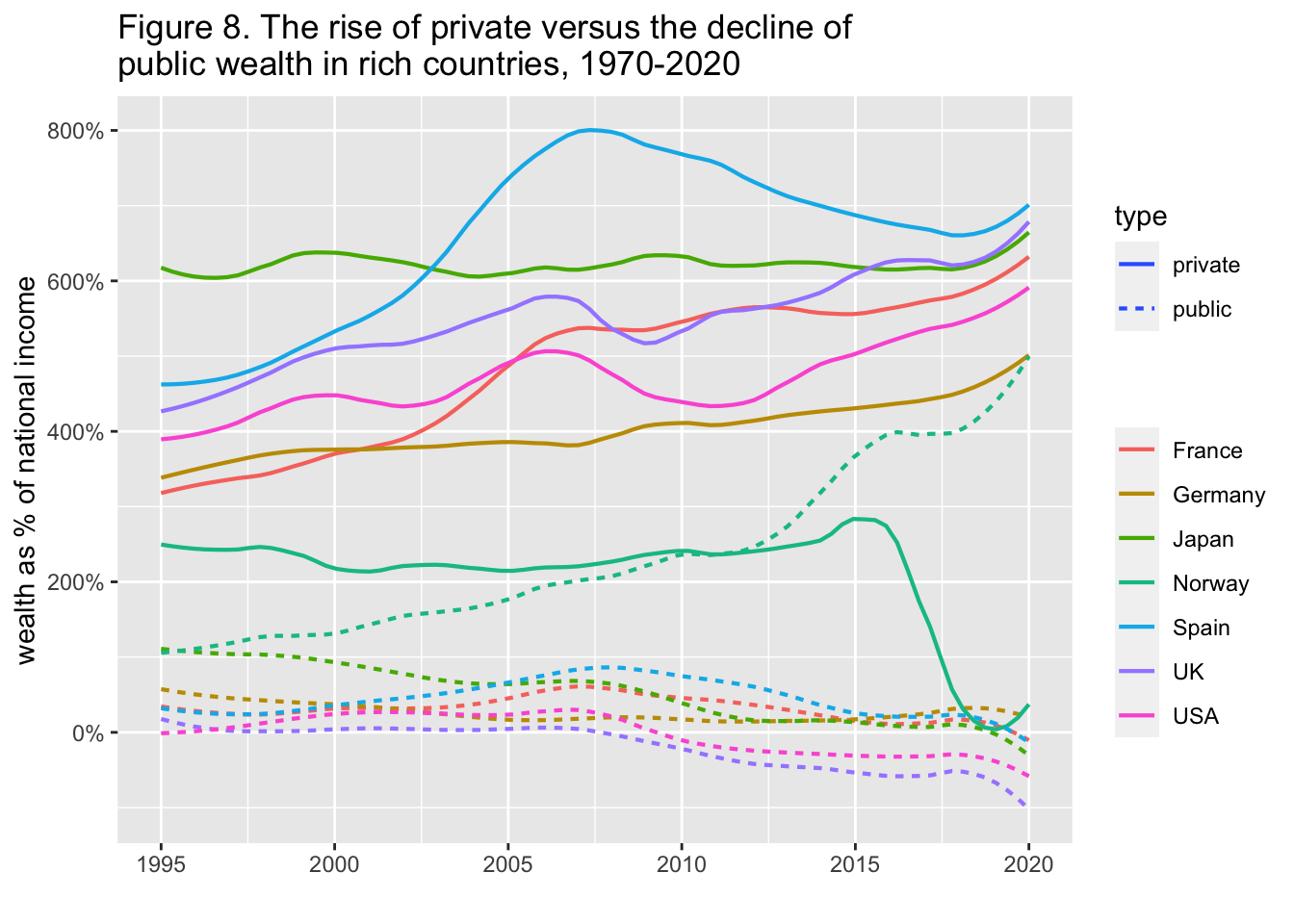
29.3.9.1.6 Step 6.
- 色 color だけを使うと、どうだろうか。これは、望んでいたものではないことを、確認してください。
df_f8 |> drop_na() |>
pivot_longer(!year, names_to = "group", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group),
formula = y~x, method = "loess",
span = 0.25, se = FALSE, size=0.75) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 8. The rise of private versus \nthe decline of public wealth in rich countries, \n1970-2020",
x = "", y = "wealth as % of national income", color = "")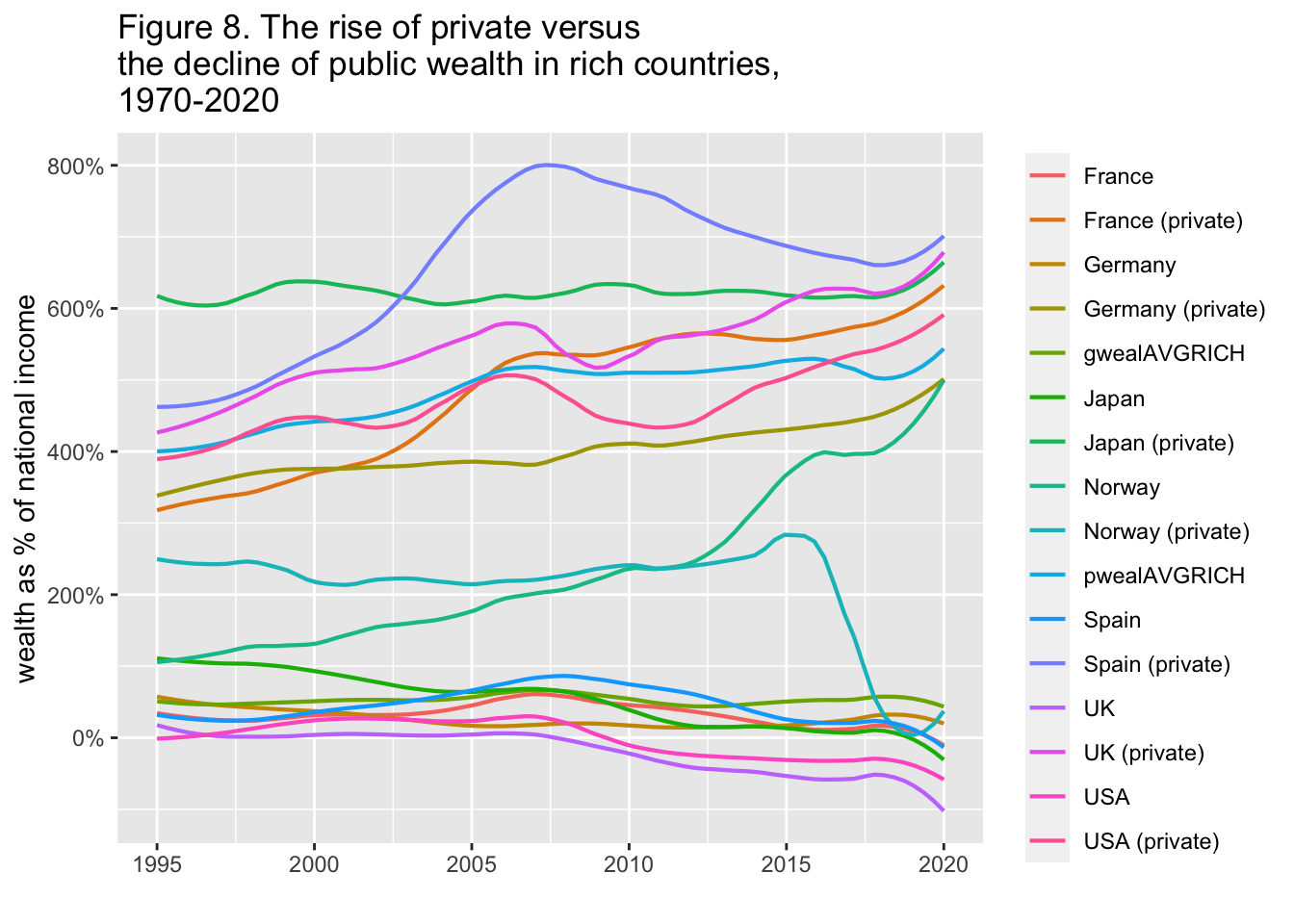
29.3.10 F9: 年平均資産成長率(1995年-2021年)
Average annual wealth growth rate, 1995-2021
df_f9 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F9")
df_f9
brks <- c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 99, 99.9, 99.99, 99.999)
df_f9 |>
mutate(level = cut(p, breaks = c(brks,100), labels = as.character(brks), include.lowest = TRUE)) |>
mutate(xlabel = as.numeric(level)+0.8) |>
ggplot(aes(x = xlabel, y = `Wealth growth 1995-2021`)) + geom_smooth(method = "loess", formula = y~x, se = FALSE, span = 0.5) +
scale_x_discrete(limits=as.character(brks)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.1)) +
labs(title = "Figure 9. Average annual wealth growth rate, 1995-2021",
x = "←1% poorest Global wealth group 0.001% richest→",
y = "Per adult annual growth rate in wealth, \nnet of inflation (%)")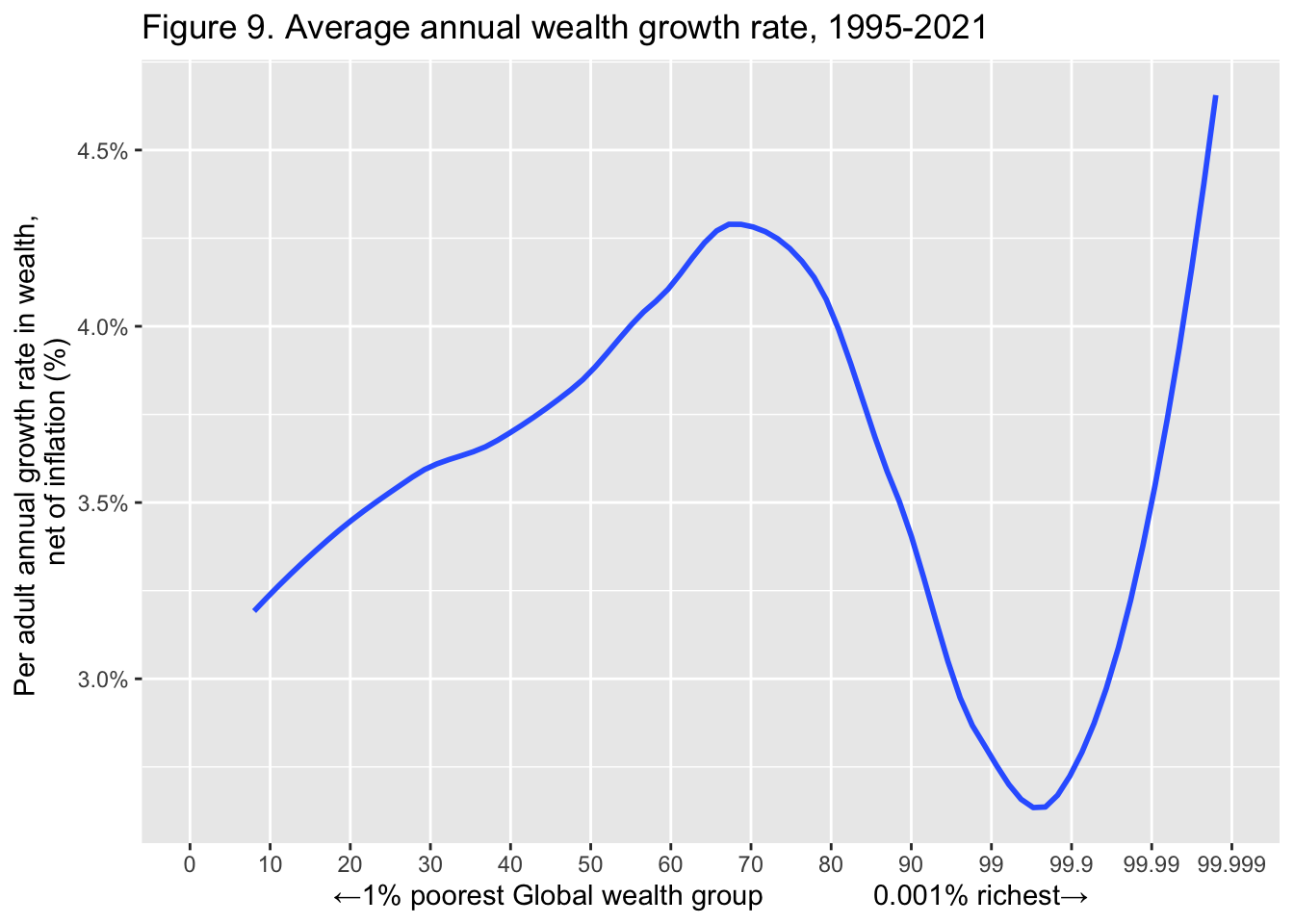
Interpretation: Growth rates among the poorest half of the population were between 3% and 4% per year, between 1995 and 2021. Since this group started from very low wealth levels, its absolute levels of growth remained very low. The poorest half of the world population only captured 2.3% of overall wealth growth since 1995. The top 1% benefited from high growth rates (3% to 9% per year). This group captured 38% of total wealth growth between 1995 and 2021. Net household wealth is equal to the sum of financial assets (e.g. equity or bonds) and non-financial assets (e.g. housing or land) owned by individuals, net of their debts.
図の解釈: 1995年から2021年にかけて、最貧困層の成長率は年率3%から4%であった。このグループは非常に低い富の水準から出発したため、成長の絶対水準は非常に低いままであった。世界人口の最貧困層は、1995年以降、富の成長全体の2.3%を占めたに過ぎない。上位1%は高い成長率(年率3%から9%)の恩恵を受けた。このグループは1995年から2021年の間に富の増加全体の38%を獲得した。家計純富とは、個人が所有する金融資産(株式や債券など)と非金融資産(住宅や土地など)の合計から負債を差し引いたものである。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.10.1 説明
29.3.10.1.1 Step 1.
- 実際の図を見ると、X軸が、等間隔には分割されていない。 (0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 99, 99.9, 99.99, 99.999).
- データの p 列を参照。
df_f9 |> distinct(p) |> pull()
#> [1] 0.000 1.000 2.000 3.000 4.000 5.000 6.000
#> [8] 7.000 8.000 9.000 10.000 11.000 12.000 13.000
#> [15] 14.000 15.000 16.000 17.000 18.000 19.000 20.000
#> [22] 21.000 22.000 23.000 24.000 25.000 26.000 27.000
#> [29] 28.000 29.000 30.000 31.000 32.000 33.000 34.000
#> [36] 35.000 36.000 37.000 38.000 39.000 40.000 41.000
#> [43] 42.000 43.000 44.000 45.000 46.000 47.000 48.000
#> [50] 49.000 50.000 51.000 52.000 53.000 54.000 55.000
#> [57] 56.000 57.000 58.000 59.000 60.000 61.000 62.000
#> [64] 63.000 64.000 65.000 66.000 67.000 68.000 69.000
#> [71] 70.000 71.000 72.000 73.000 74.000 75.000 76.000
#> [78] 77.000 78.000 79.000 80.000 81.000 82.000 83.000
#> [85] 84.000 85.000 86.000 87.000 88.000 89.000 90.000
#> [92] 91.000 92.000 93.000 94.000 95.000 96.000 97.000
#> [99] 98.000 99.000 99.900 99.990 99.999-
cutを使って、分割を作成します。
brks <- c(0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 99, 99.9, 99.99, 99.999)
df_f9 |> mutate(level = cut(p, breaks = c(brks,100), labels = as.character(brks), include.lowest = TRUE))29.3.10.1.2 Step 2.
- 列
xlabelを加えます。
df_f9 |> mutate(level = cut(p, breaks = c(brks,100), labels = as.character(brks), include.lowest = TRUE)) |>
mutate(xlabel = as.numeric(level))29.3.10.1.3 Step 3.
- GEOM
geom_smoothを使って、近似曲線を描きます。 - 各区間の平均をとるため 0.5 を加えています。
df_f9 |> mutate(level = cut(p, breaks = c(brks,100), labels = as.character(brks), include.lowest = TRUE)) |>
mutate(xlabel = as.numeric(level)+0.5) |>
ggplot(aes(x = xlabel, y = `Wealth growth 1995-2021`)) + geom_smooth(method = "loess", formula = y~x, se = FALSE, span = 0.5)
29.3.10.1.4 Step 4.
- X 軸のラベルを
scale_x_discrete(limits=as.character(brks))で変更します。 - Y 軸のラベルを
scale_y_continuous(labels = scales::percent_format(accuracy = 0.1))で設定します。
df_f9 |> mutate(level = cut(p, breaks = c(brks,100), labels = as.character(brks), include.lowest = TRUE)) |>
mutate(xlabel = as.numeric(level)+ 0.8) |>
ggplot(aes(x = xlabel, y = `Wealth growth 1995-2021`)) + geom_smooth(method = "loess", formula = y~x, se = FALSE, span = 0.5) +
scale_x_discrete(limits=as.character(brks)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 0.1))
29.3.11 F10: 世界の0.1%と億万長者が所有する富のシェア(2021年)
The share of wealth owned by the global 0.1% and billionaires, 2021
df_f10 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F10")
#> New names:
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
df_f10
df_f10 |>
select(year, "Global Billionaire Wealth" = bn_hhweal, "Top 0.01%" = top0.1_hhweal) |>
pivot_longer(!year, names_to = "group", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group),
formula = y~x, method = "loess",
span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1995, 2020, by = 5),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_color_manual(values=rev(scales::hue_pal()(2))) +
labs(title = "Figure 10. Extreme wealth inequality: \nthe rise of global billionaires and top 0.01%, 1995-2021",
x = "", y = "Share of total household wealth (%)", color = "")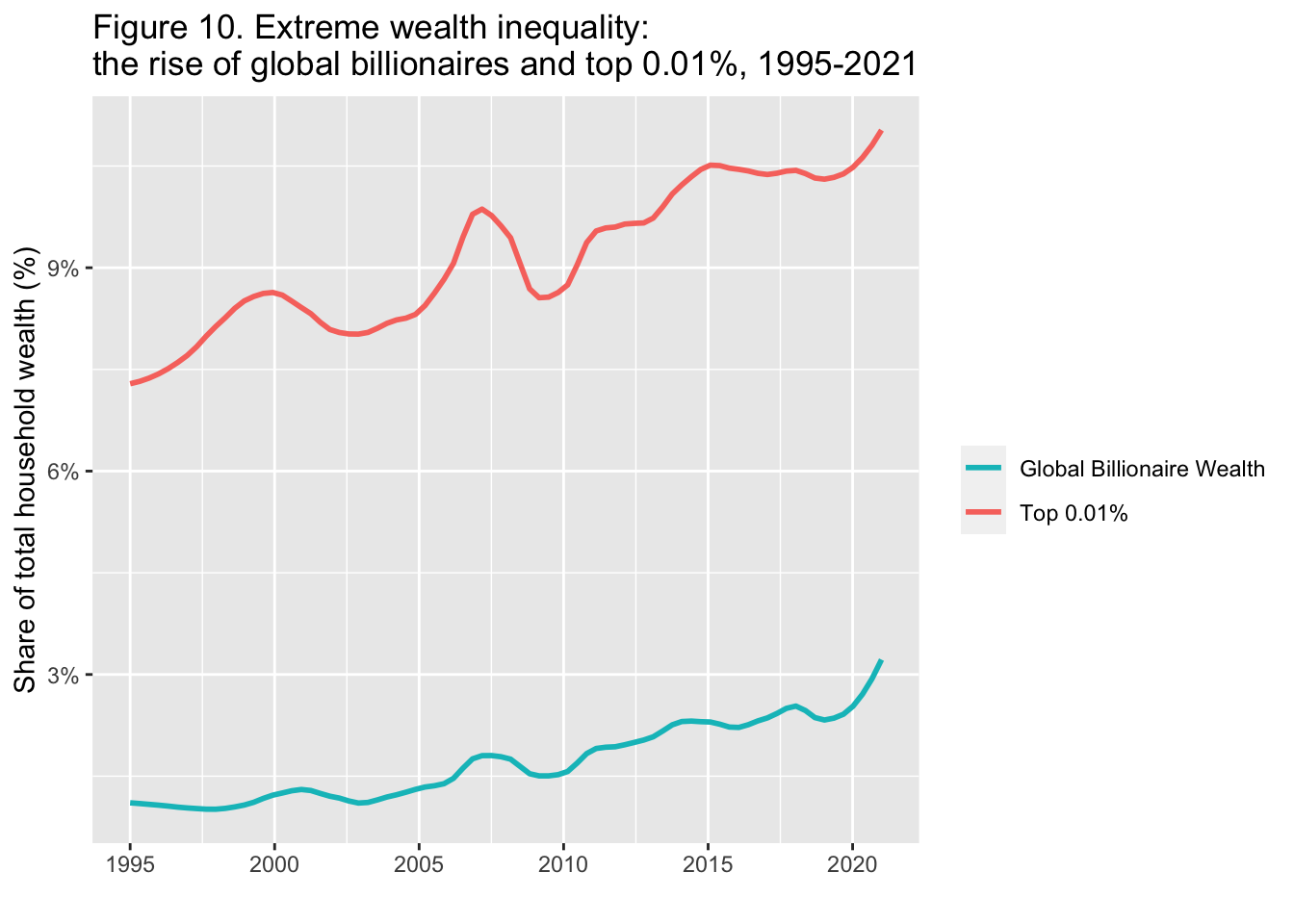
Interpretation: The share of wealth detained by the world’s billionaires rose from 1% of total household wealth in 1995 to nearly 3.5% today. The threshold of top 0.01%, composed of 520 000 adults, grew from €693,000 (PPP) in 1995 to €16,666,000 today. The net household wealth is equal to the sum of financial assets (e.g. equity or bonds) and non-financial assets (e.g. housing or land) owned by individuals, net of their debts.
図の解釈:世界の億万長者が保有する富のシェアは、1995年の世帯総資産の1%から、今日では約3.5%に上昇した。520,000人の成人で構成される上位0.01%の閾値は、1995年の693,000ユーロ(購買力平価)から、今日では16,666,000ユーロに増加している。正味家計資産とは、個人が所有する金融資産(株式や債券など)と非金融資産(住宅や土地など)の合計から負債を差し引いたものである。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Bauluz et al. (2021) と更新情報
29.3.11.1 説明
29.3.11.1.1 Step 1.
- わかりやすい列名に変更し
pivot_longerを使って tidy データに整理。
df_f10 |>
select(year, "Global Billionaire Wealth" = bn_hhweal, "Top 0.01%" = top0.1_hhweal) |>
pivot_longer(!year, names_to = "group", values_to = "value")29.3.11.1.2 Step 2.
- 近似曲線を
geom_smoothに引数span = 0.25を加えて描き、X 軸のラベルを変更。
df_f10 |>
select(year, "Global Billionaire Wealth" = bn_hhweal, "Top 0.01%" = top0.1_hhweal) |>
pivot_longer(!year, names_to = "group", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group),
formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1995, 2020, by = 5),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 10. Extreme wealth inequality: \nthe rise of global billionaires and top 0.01%, 1995-2021",
x = "", y = "Share of total household wealth (%)", color = "")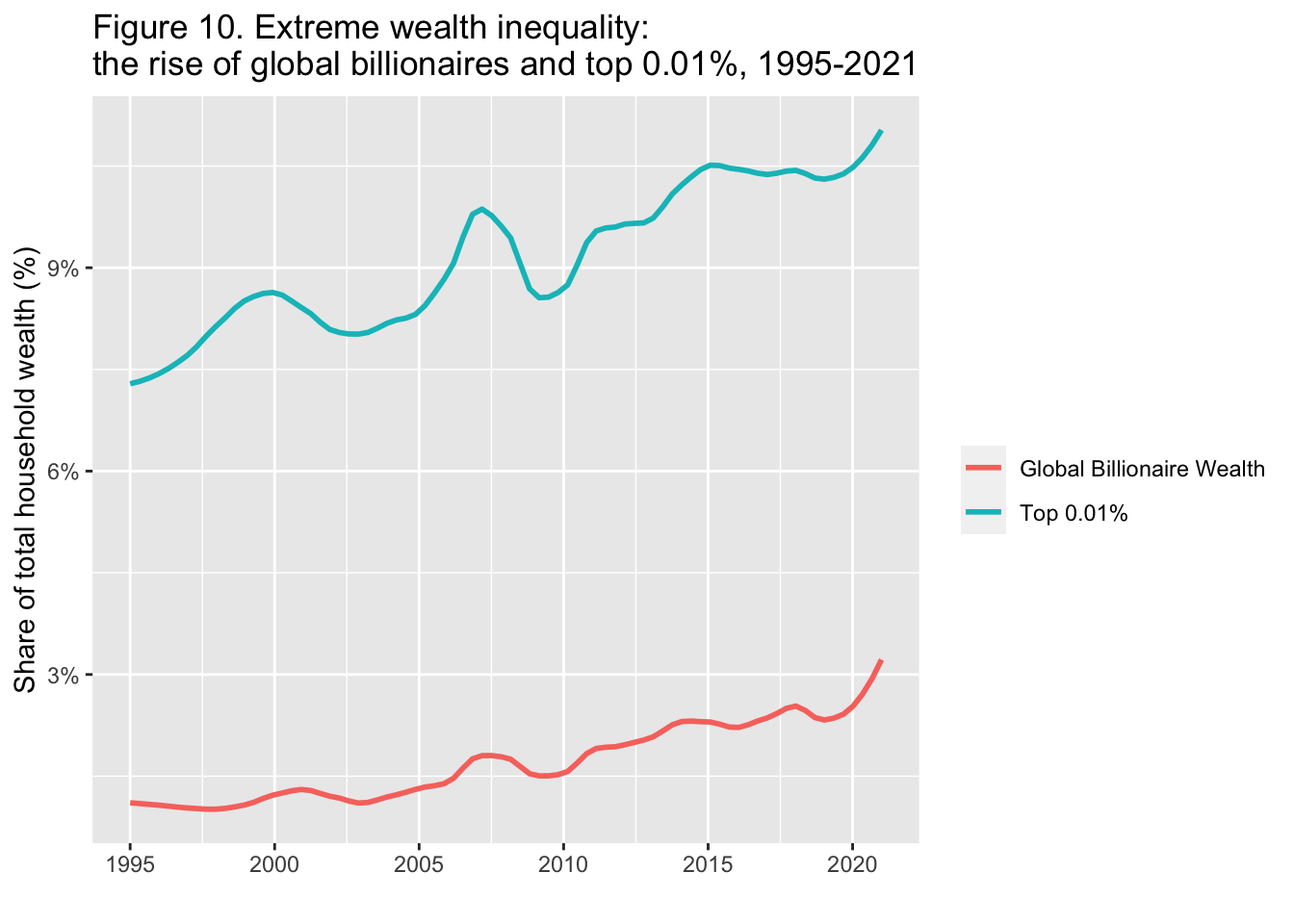
29.3.11.1.3 Step 3.
- 色を
scale_color_manual(values=rev(scales::hue_pal()(2)))で入れ替えます。nを数の数とするとscales::hue_pal()(n)によって RGB の色コードがわかります。 またrevを使うと、順序を逆にできます。 https://ggplot2.tidyverse.org/reference/scale_hue.html.
df_f10 |>
select(year, "Global Billionaire Wealth" = bn_hhweal, "Top 0.01%" = top0.1_hhweal) |>
pivot_longer(!year, names_to = "group", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group),
formula = y~x, method = "loess", span = 0.25, se = FALSE) +
scale_x_continuous(breaks = round(seq(1995, 2020, by = 5),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_color_manual(values=rev(scales::hue_pal()(2))) +
labs(title = "Figure 10. Extreme wealth inequality: \nthe rise of global billionaires and top 0.01%, 1995-2021",
x = "", y = "Share of total household wealth (%)", color = "")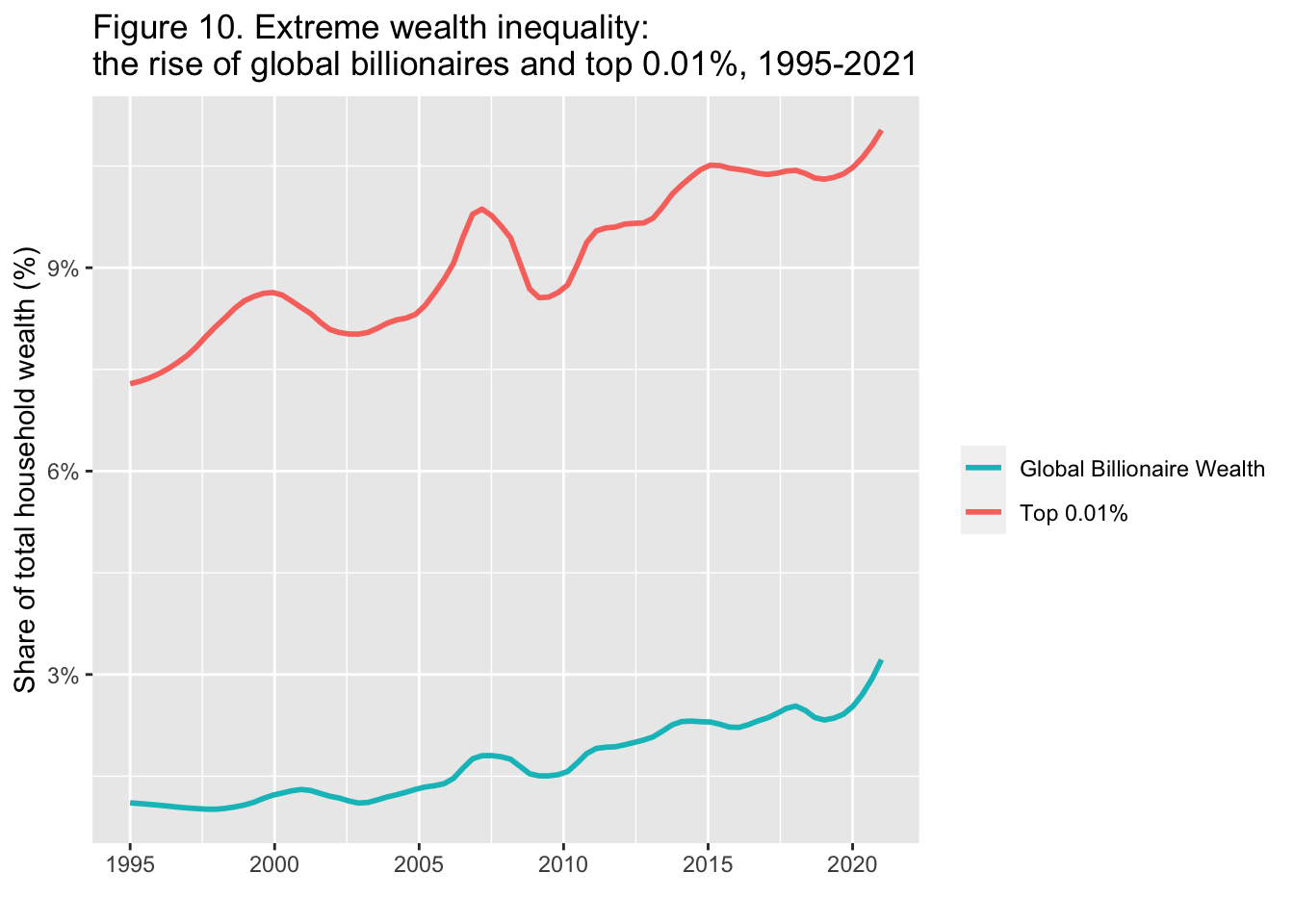
29.3.12 F11: 西欧とアメリカにおける上位1%と下位50%の富のシェア(1910年-2020年)
Top 1% vs bottom 50% wealth shares in Western Europe and the US, 1910-2020
df_f11 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F11")
df_f11
df_f11 |>
rename(!year, US_bot50 = USbot50, US_top1 = UStop1, EU_bot50 = EUbot50, EU_top1 = EUtop1) |>
pivot_longer(!year, names_to = c("group",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group, linetype = type),
formula = y~x, method = "loess", span = 0.5, se = FALSE) +
scale_x_continuous(breaks = round(seq(1910, 2020, by = 10),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 11. Top 1% vs bottom 50% wealth shares \n in Western Europe and the US, 1910-2020",
x = "", y = "Share of total personal wealth (%)", color = "", linetype = "") +
scale_linetype_manual(values = c("dotted","solid")) +
annotate("text", x = 2000, y = 0.50, label = stringr::str_wrap("Wealth inequality has been rising at different speeds after a historical decline. The bottom 50% has always been extremely low.", width = 30), size = 3)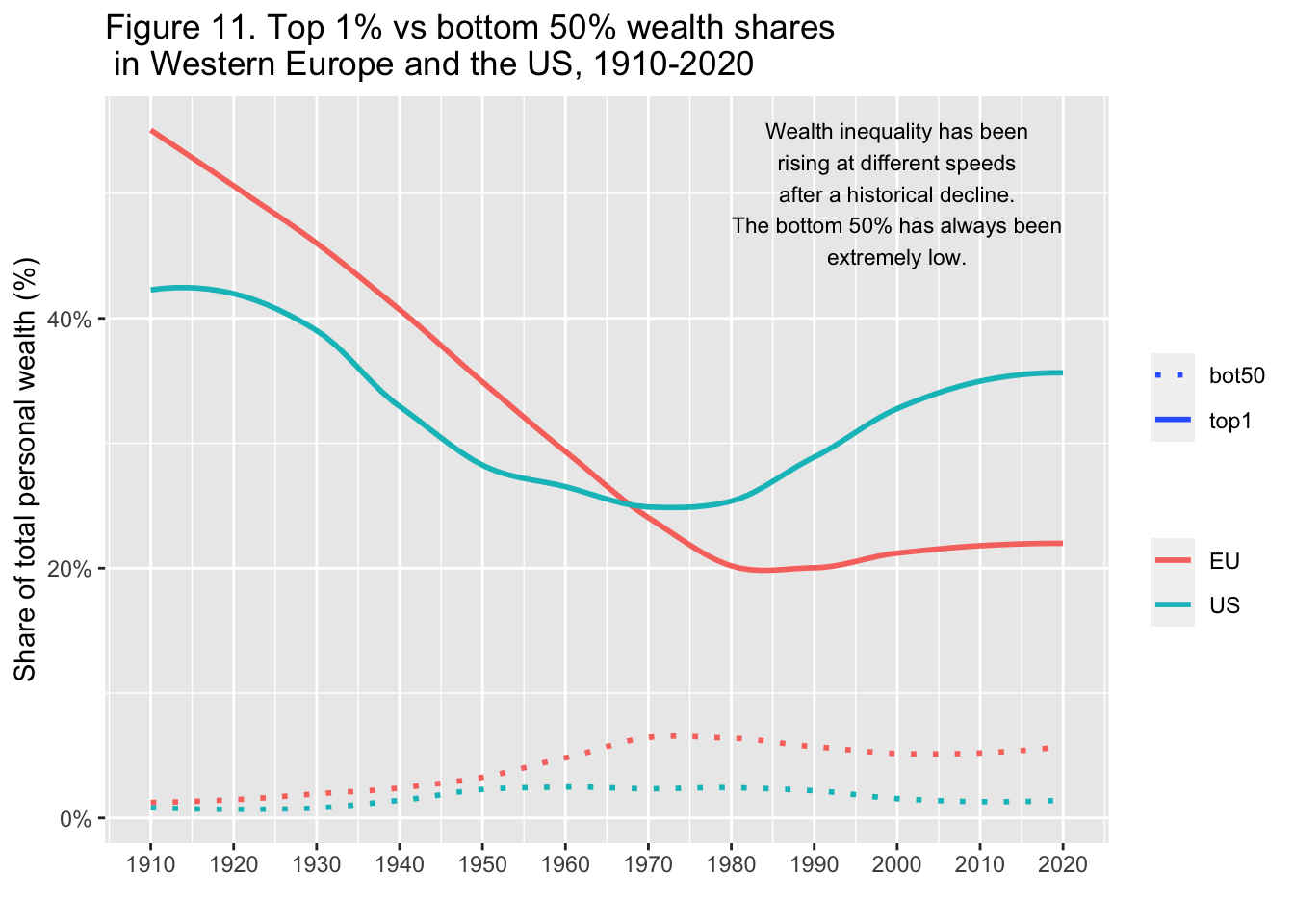
Interpretation: The graph presents decennal averages of top 1% personal wealth shares in Western Europe and the US. Between 1910 and 2020, the top 1% was 55% on average in Europe vs. 43% in the US. A century later, the US is almost back to its early 20th century level.
図の解釈: グラフは西欧と米国の上位1%の個人資産シェアの10年平均を示している。1910年から2020年にかけて、上位1%の平均は欧州が55%であったのに対し、米国は43%であった。1世紀後、米国は20世紀初頭の水準にほぼ戻っている。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.3.12.1 説明
29.3.12.1.1 Step 1.
- 二種類のグループがあります: US と EU の組と、 bot50 と top1 の組です。F8 で使ったのと同じ、方法を使って、分離します。
df_f11 |>
rename(!year, US_bot50 = USbot50, US_top1 = UStop1, EU_bot50 = EUbot50, EU_top1 = EUtop1) |>
pivot_longer(!year, names_to = c("group",".value"), names_sep = "_")29.3.12.1.2 Step 2.
- ここでは、
geom_smoothと、異なるaes()を使うことも可能です。 - 違いがわかりますか。
df_f11 |>
rename(!year, US_bot50 = USbot50, US_top1 = UStop1, EU_bot50 = EUbot50, EU_top1 = EUtop1) |>
pivot_longer(!year, names_to = c("group",".value"), names_sep = "_") |>
ggplot() +
geom_smooth(aes(x = year, y = top1, color = group),
formula = y~x, method = "loess", span = 0.5, se = FALSE) +
geom_smooth(aes(x = year, y = bot50, color = group),
formula = y~x, method = "loess", span = 0.5, se = FALSE, linetype = 2) +
scale_x_continuous(breaks = round(seq(1910, 2020, by = 10),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 11. Top 1% vs bottom 50% wealth shares \n in Western Europe and the US, 1910-2020",
x = "", y = "Share of total personal wealth (%)", color = "") +
annotate("text", x = 2000, y = 0.50, label = stringr::str_wrap("Wealth inequality has been rising at different speeds after a historical decline. The bottom 50% has always been extremely low.", width = 30), size = 3)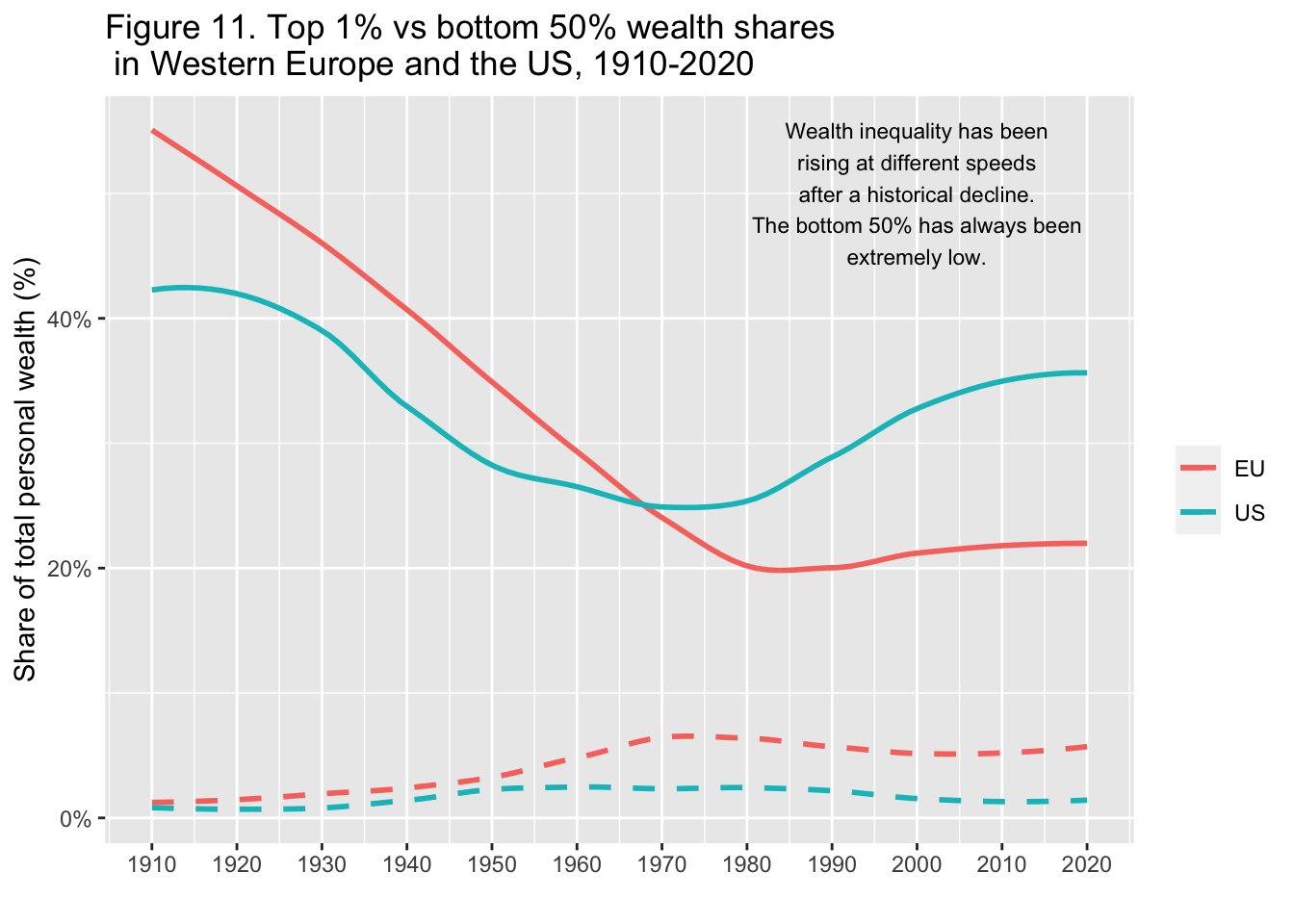
29.3.12.1.3 Step 3.
再度 pivot_longer を使います。
df_f11 |>
rename(!year, US_bot50 = USbot50, US_top1 = UStop1, EU_bot50 = EUbot50, EU_top1 = EUtop1) |>
pivot_longer(!year, names_to = c("group",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group, linetype = type),
formula = y~x, method = "loess", span = 0.5, se = FALSE) +
scale_x_continuous(breaks = round(seq(1910, 2020, by = 10),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 11. Top 1% vs bottom 50% wealth shares \n in Western Europe and the US, 1910-2020",
x = "", y = "Share of total personal wealth (%)", color = "", linetype = "") +
annotate("text", x = 2000, y = 0.50, label = stringr::str_wrap("Wealth inequality has been rising at different speeds after a historical decline. The bottom 50% has always been extremely low.", width = 30), size = 3)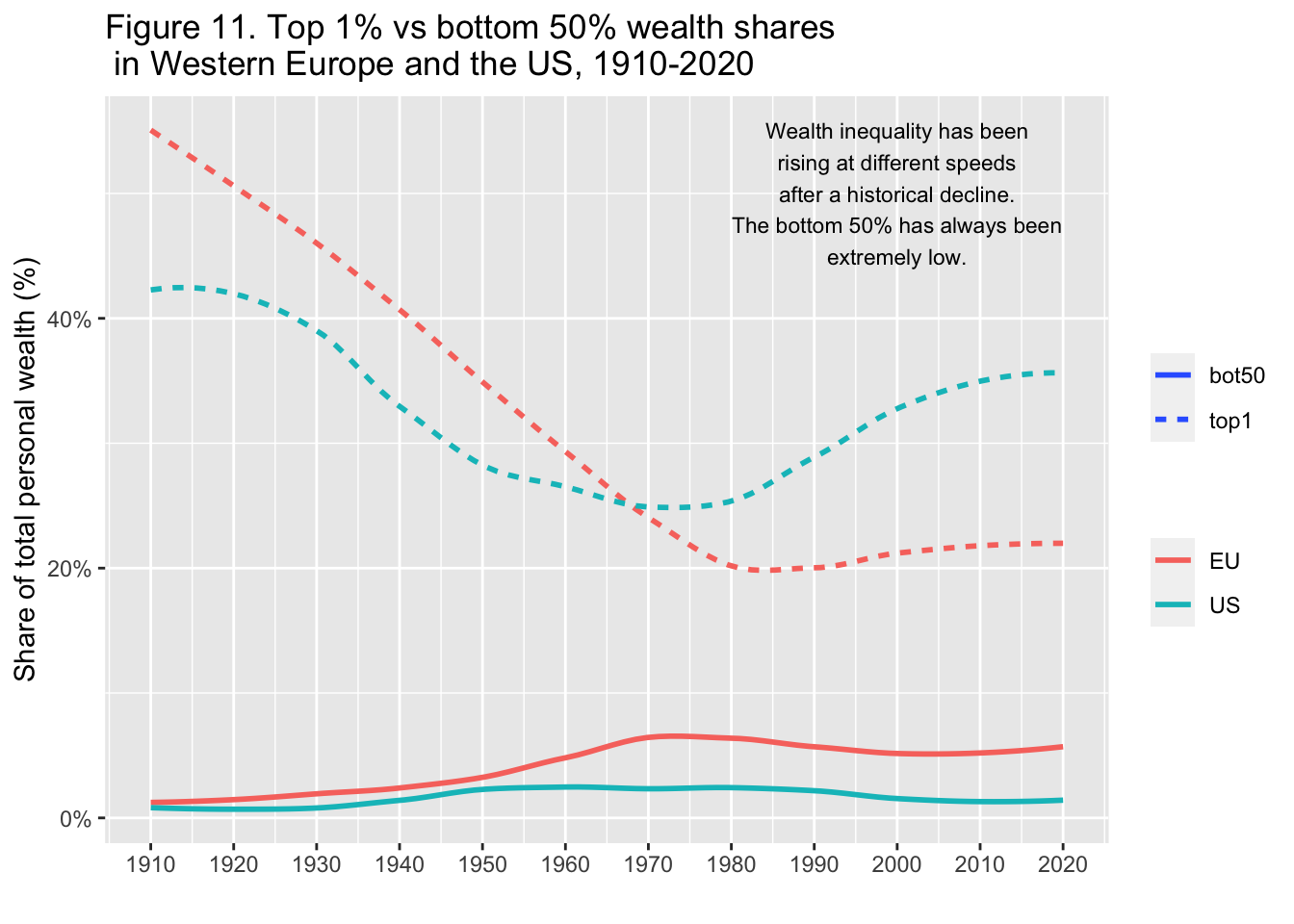
29.3.12.1.4 Step 4.
線の種類 linetypes を手動で変更します。
df_f11 |>
rename(!year, US_bot50 = USbot50, US_top1 = UStop1, EU_bot50 = EUbot50, EU_top1 = EUtop1) |>
pivot_longer(!year, names_to = c("group",".value"), names_sep = "_") |>
pivot_longer(3:4, names_to = "type", values_to = "value") |>
ggplot() +
geom_smooth(aes(x = year, y = value, color = group, linetype = type),
formula = y~x, method = "loess",
span = 0.5, se = FALSE) +
scale_x_continuous(breaks = round(seq(1910, 2020, by = 10),1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 11. Top 1% vs bottom 50% wealth shares \n in Western Europe and the US, 1910-2020",
x = "", y = "Share of total personal wealth (%)", color = "", linetype = "") +
scale_linetype_manual(values = c("dotted","solid")) +
annotate("text", x = 2000, y = 0.50, label = stringr::str_wrap("Wealth inequality has been rising at different speeds after a historical decline. The bottom 50% has always been extremely low.", width = 30), size = 3)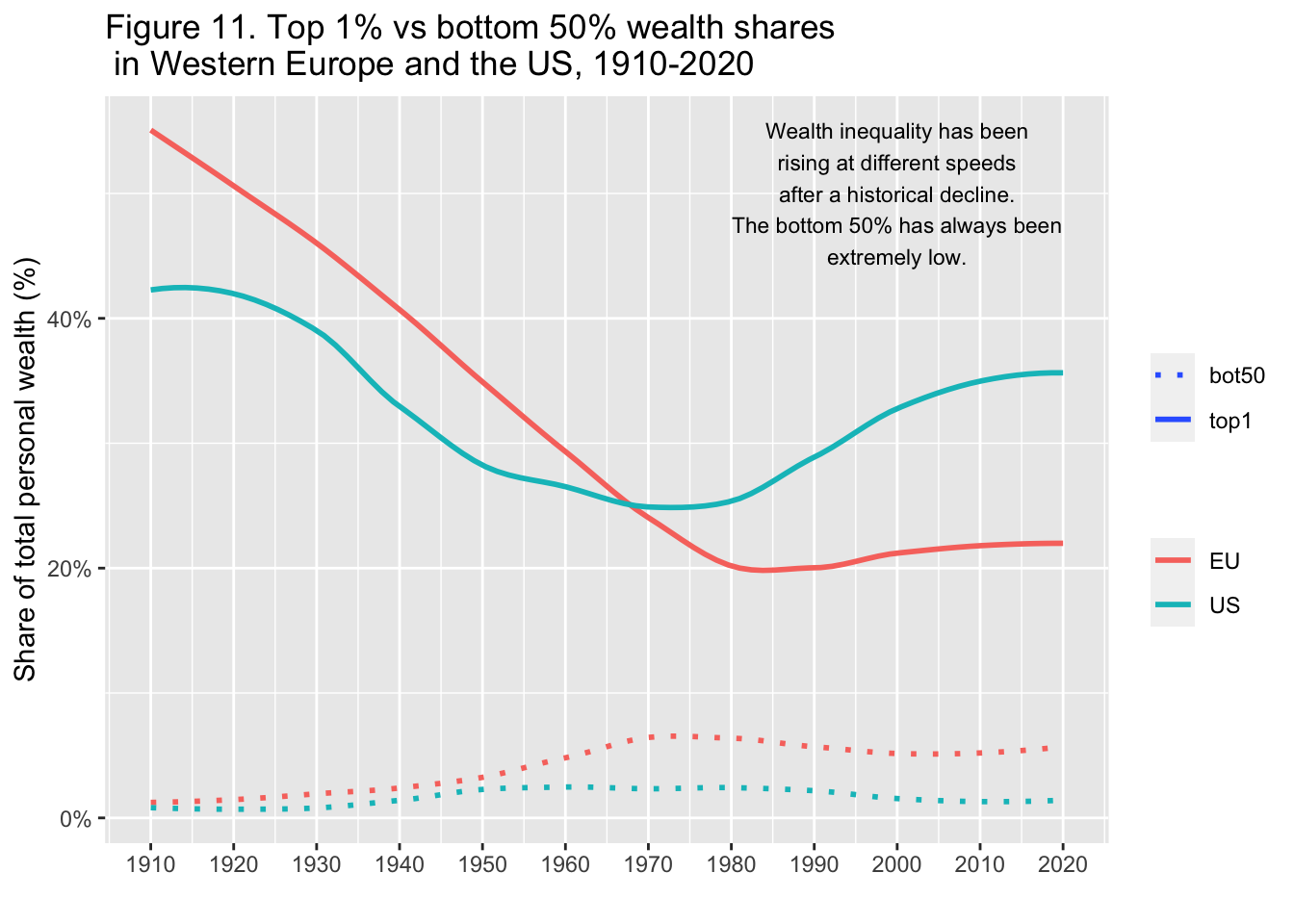
29.3.13 F12: 世界の労働所得に占める女性の割合(1990年-2020年)
Female share in global labor incomes, 1990-2020
df_f12 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F12")
#> New names:
#> • `` -> `...2`
df_f12
df_f12 |>
select(year = "Data needs to be updated", value = ...2) |>
filter(!is.na(year)) |>
ggplot(aes(x = year, y = value)) +
geom_col(width = 0.5, fill = scales::hue_pal()(2)[2]) +
geom_hline(yintercept = 0.5, linetype = 2, colour = scales::hue_pal()(2)[1]) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 12. Female share in global labor incomes, 1990-2020",
x = "", y = "") +
annotate("text", x = 1, y = 0.48, label = "Gender parity", size = 3) +
annotate("text", x = 5.2, y = 0.47, label = stringr::str_wrap("Women make only 35% of global labor incomes, men make the remaining 65%.", width = 40), size = 3)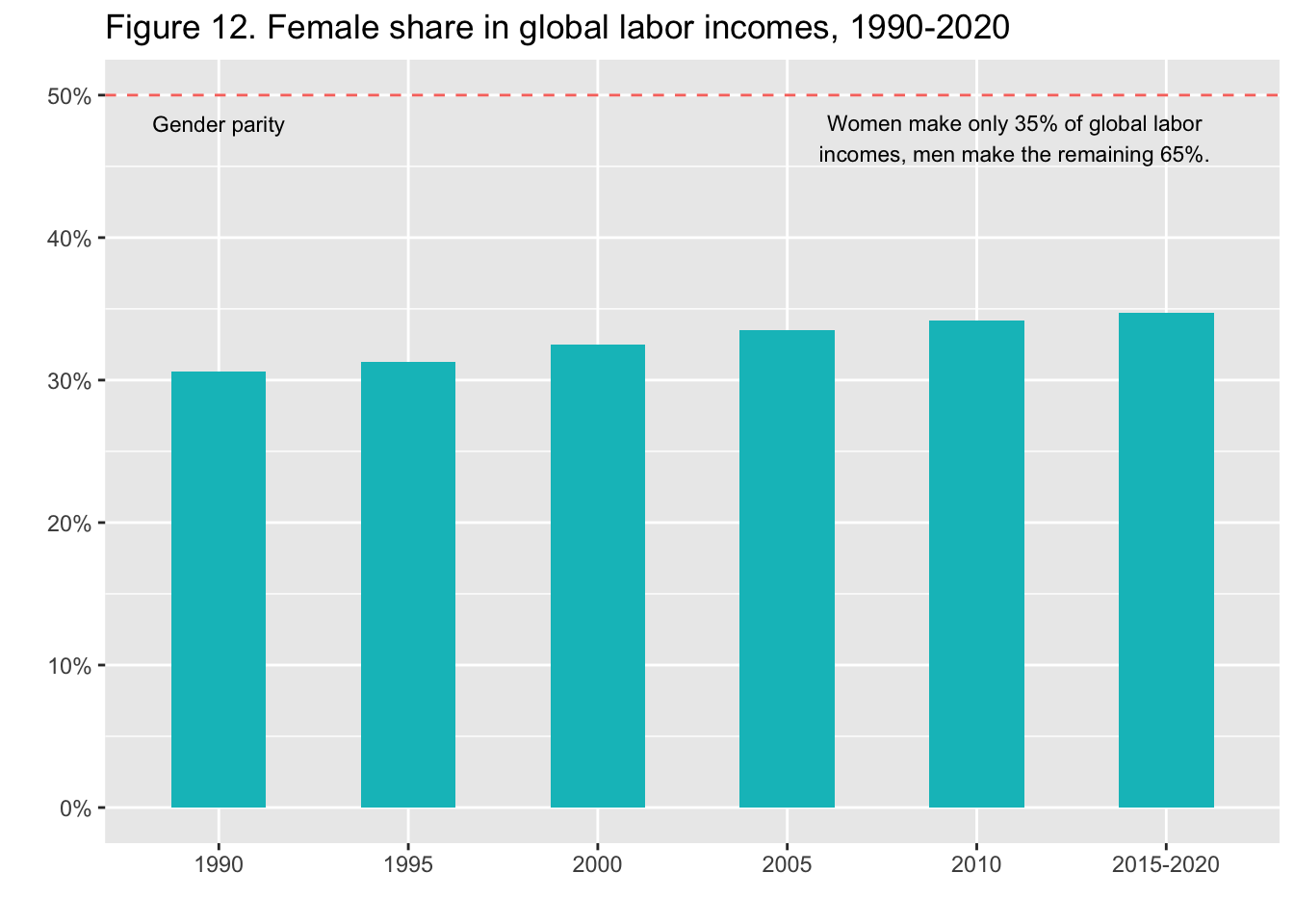
Interpretation: The share of female incomes in global labour incomes was 31% in 1990 and nears 35% in 2015-2020. Today, males make up 65% of total labor incomes.
図の解釈: 世界の労働所得に占める女性の割合は、1990年には31%であったが、2015-2020年には35%に近づく。現在、男性が労働所得全体の65%を占めている。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Neef and Robilliard (2021).
29.3.13.1 説明
29.3.13.1.2 Step 2.
二つの GEOM、 geom_col と geom_hline を使い、色を、scales::hue_pal()(2)[2] と scales::hue_pal()(2)[1] で設定します。
df_f12 |>
select(year = "Data needs to be updated", value = ...2) |>
filter(!is.na(year)) |>
ggplot(aes(x = year, y = value)) +
geom_col(width = 0.5, fill = scales::hue_pal()(2)[2]) +
geom_hline(yintercept = 0.5, linetype = 2, colour = scales::hue_pal()(2)[1]) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 12. Female share in global labor incomes, 1990-2020",
x = "", y = "") +
annotate("text", x = 1, y = 0.48, label = "Gender parity", size = 3) +
annotate("text", x = 5.2, y = 0.47, label = stringr::str_wrap("Women make only 35% of global labor incomes, men make the remaining 65%.", width = 40), size = 3)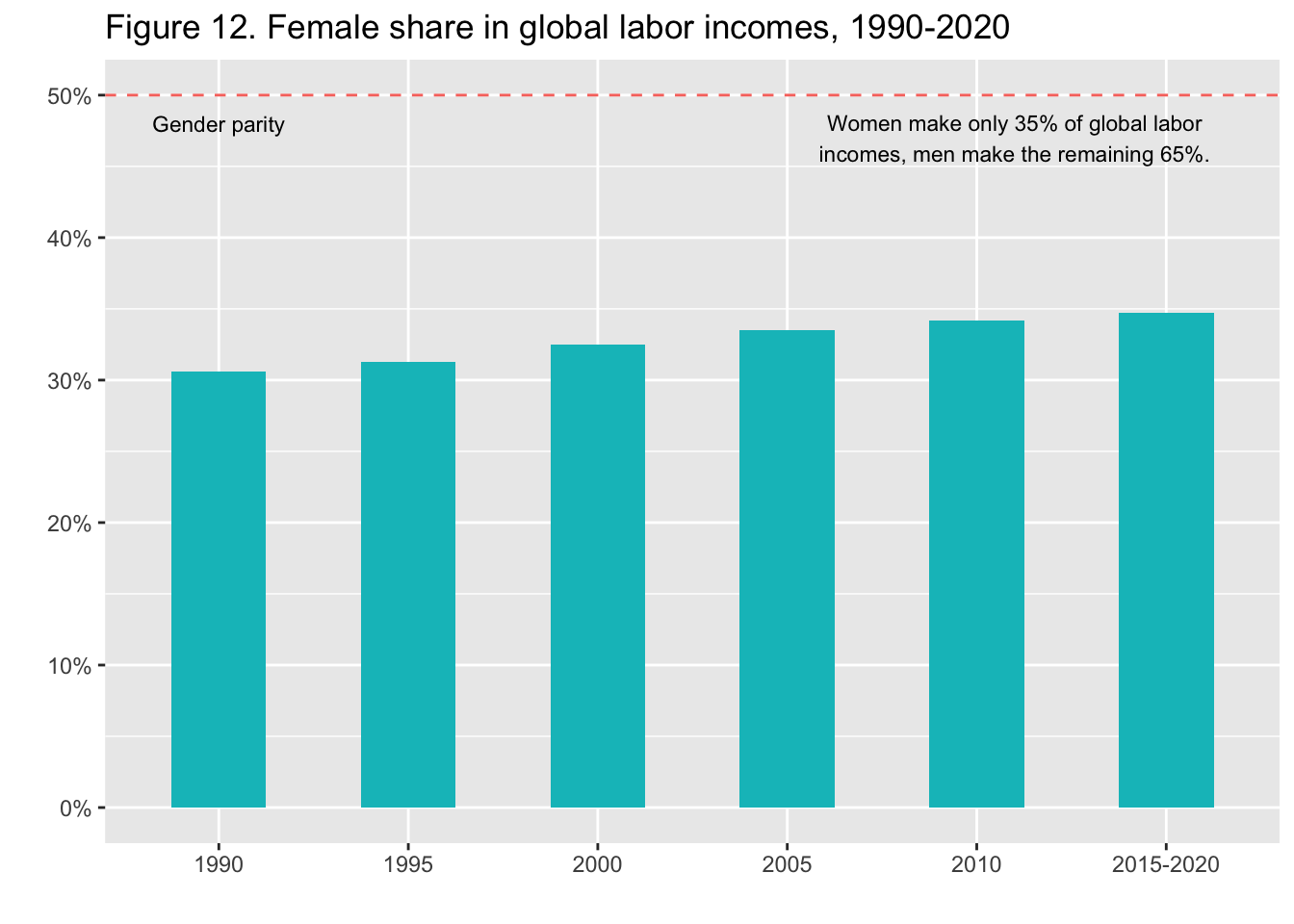
29.3.14 F13: 世界における女性の労働所得シェア(1990-2020年)
Female labor income share across the world, 1990-2020
シート名には F13 の後に、ピリオッドがついています。 `summary_sheets[30] = `data-F13.
df_f13 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F13.")
#> New names:
#> • `` -> `...1`
df_f13
df_f13 |> pivot_longer(2:9, names_to = "region", values_to = "value") |>
ggplot(aes(x = region, y = value, fill = ...1)) +
geom_col(position = "dodge") +
geom_hline(yintercept = 0.5, linetype = 2, colour = "red") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 12)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 13. Female labor income share across the world, 1990-2020",
x = "", y = "", fill = "") +
annotate("text", x = 1.2, y = 0.48, label = "Gender parity", size = 3)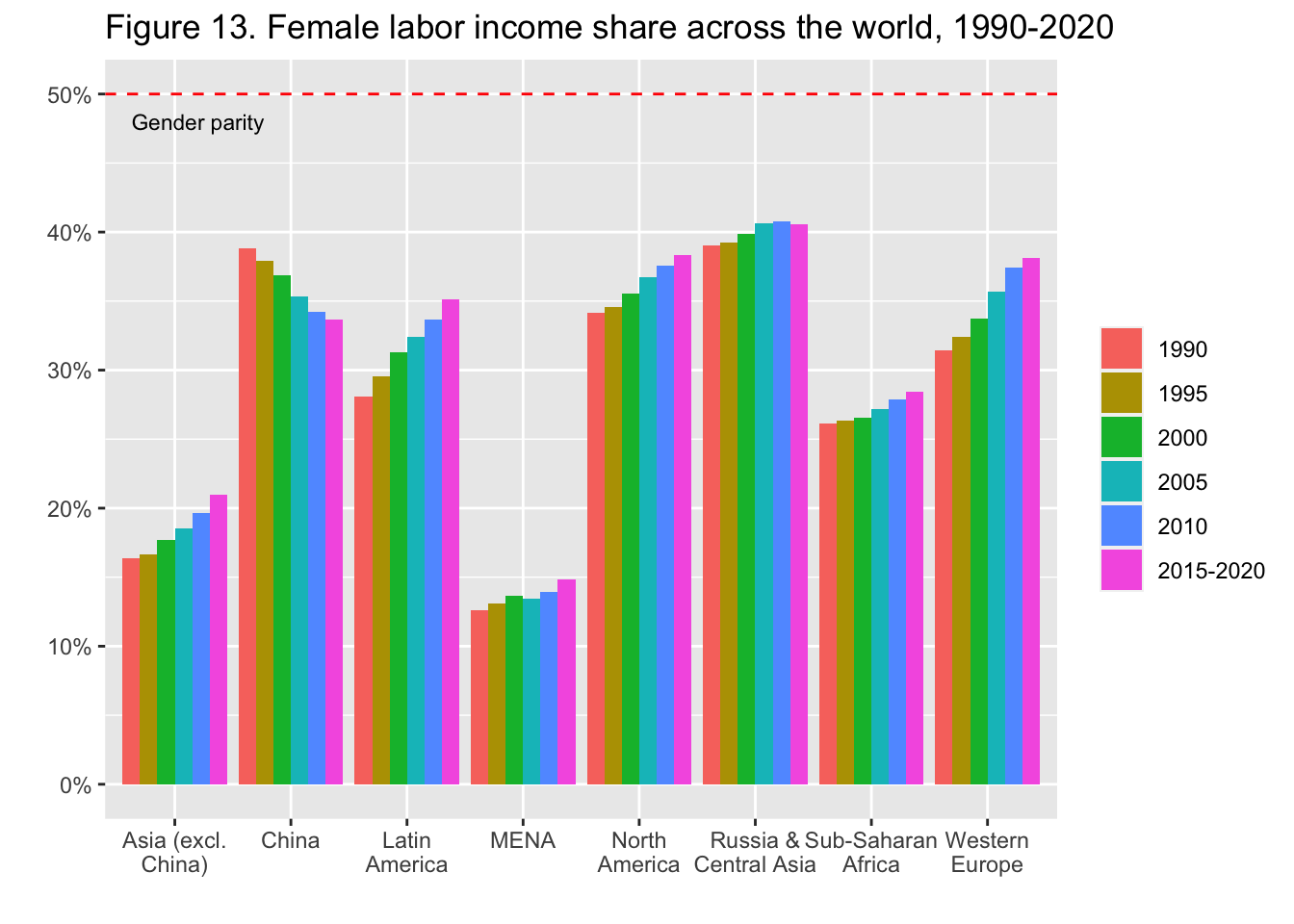
Interpretation: The female labour income share rose from 34% to 38% in North America between 1990 and 2020.
図の解釈: 1990年から2020年にかけて、北米における女性の労働所得シェアは34%から38%に上昇した。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Neef and Robilliard (2021).
29.3.15 F14: 世界の炭素不平等、2019年 世界の排出量に対するグループの寄与率(%)
Global carbon inequality, 2019. Group contribution to world emissions (%)
シート名にピリオッドが F14 の後ろについています。 Note that `summary_sheets[31] = `data-F14.
df_f14 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F14.")
df_f14-
\nをタイトルの、改行が必要な箇所に挿入します。
df_f14 |>
ggplot(aes(x = Group, y = Share)) +
geom_col(width = 0.5, fill = scales::hue_pal()(1)[1]) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(title = "Figure 14. Global carbon inequality, \n2019 Group contribution to world emissions (%)",
x = "", y = "Share of world emissions (%)")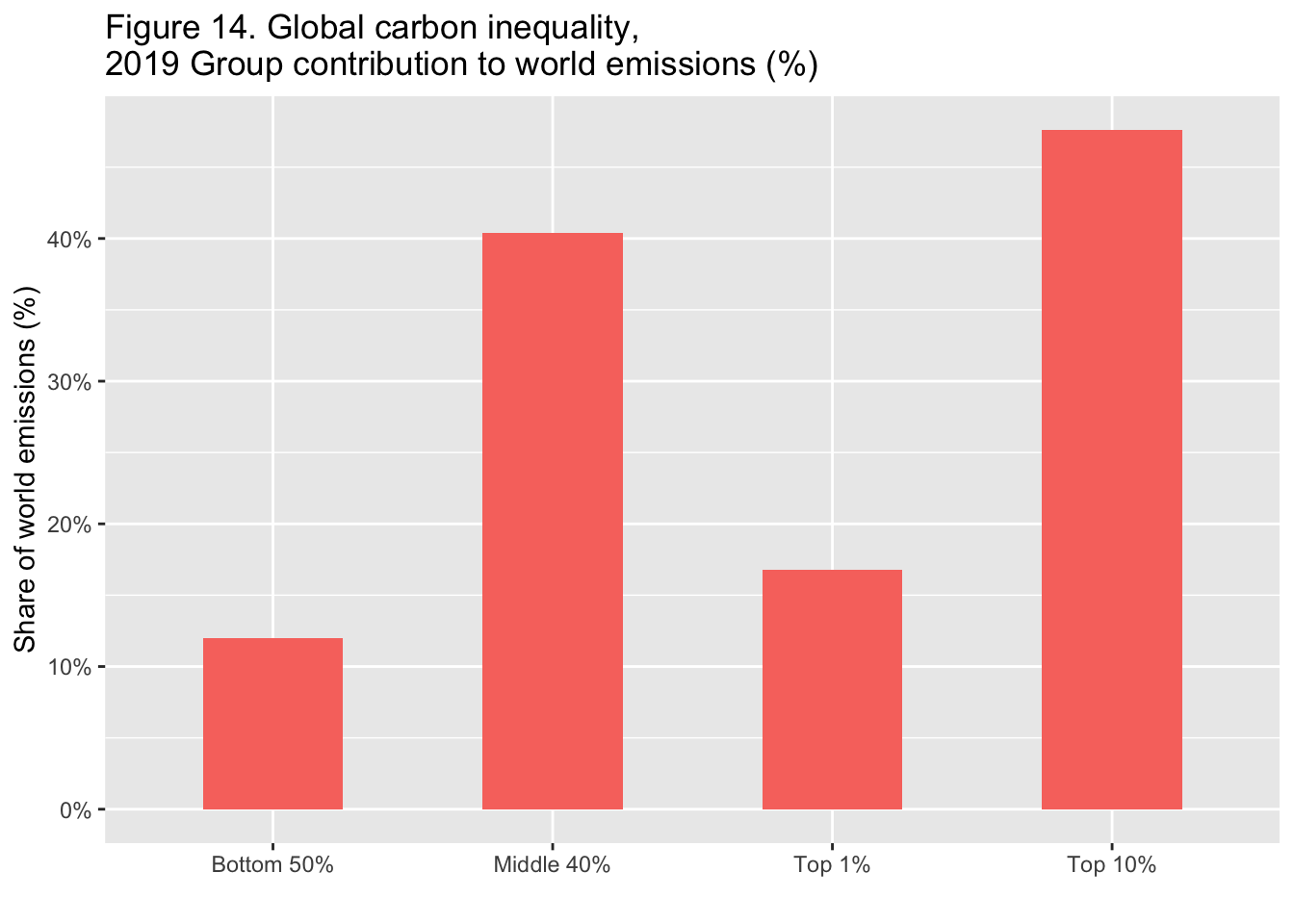
Interpretation: Personal carbon footprints include emissions from domestic consumption, public and private investments as well as imports and exports of carbon embedded in goods and services traded with the rest of the world. Modeled estimates based on the systematic combination of tax data, household surveys and input-output tables. Emissions split equally within households.
図の解釈: 個人のカーボン・フットプリントには、国内消費、公共投資、民間投資による排出に加え、世界と取引される財やサービスに含まれる炭素の輸出入が含まれる。税データ、家計調査、産業連関表の体系的な組み合わせに基づくモデル推定値。排出量は家計内で均等に分配される。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Chancel (2021).
29.3.15.1 説明
Not so difficult. You can assign color name. See http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/.
29.3.16 F15: 世界の一人当たり排出量(2019年)
Per capita emissions acriss the world, 2019
df_f15 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx", sheet = "data-F15")
df_f15
df_f15 |> mutate(region = rep(regionWID[!is.na(regionWID)], each = 3)) |>
select(region, group, tcap) |>
ggplot(aes(x = region, y = tcap, fill = group)) +
geom_col(position = "dodge") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 10)) +
labs(title = "Figure 15 Per capita emissions across the world, 2019",
x = "", y = "tonnes of CO2e per person per year", fill = "")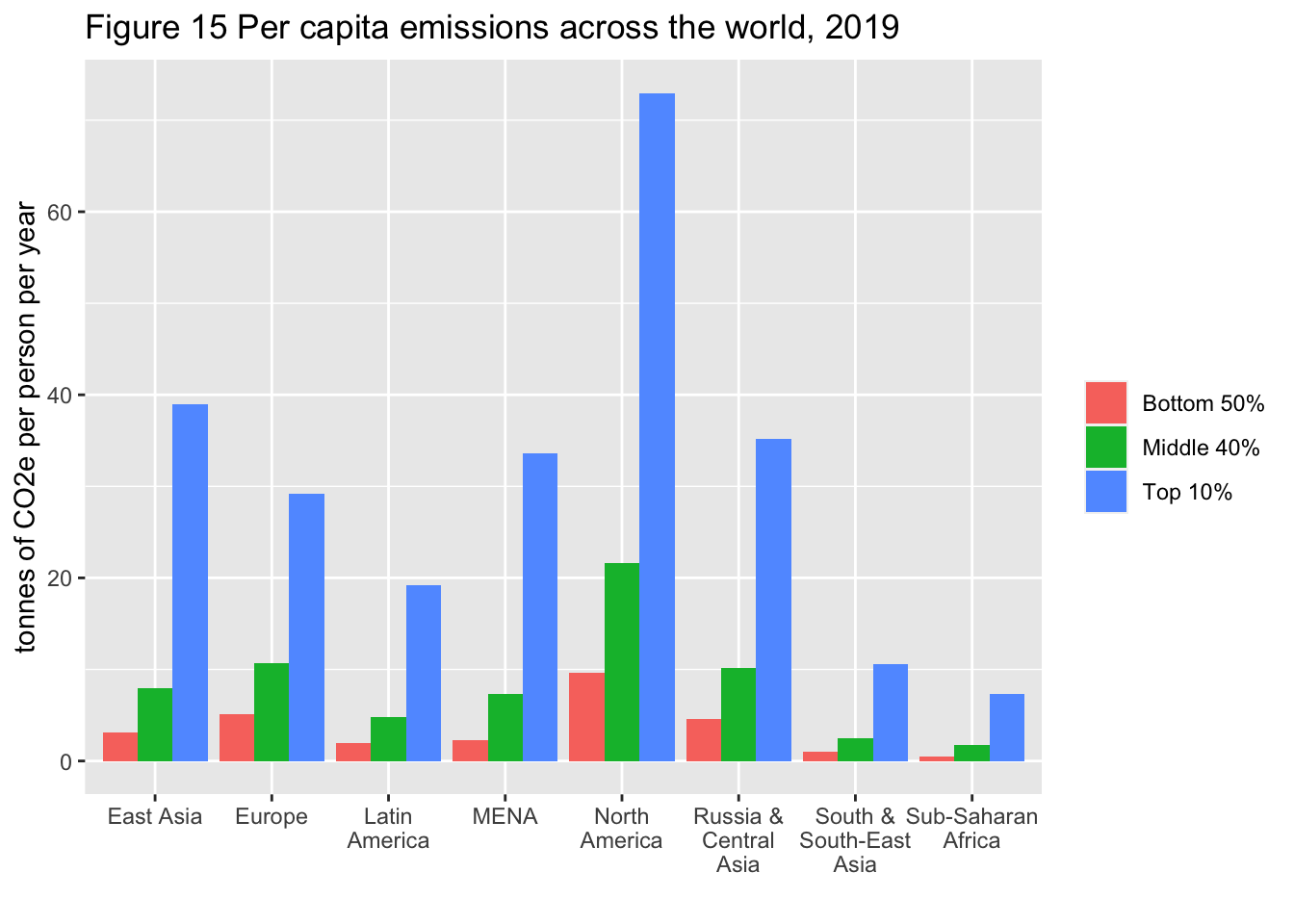
Interpretation: Personal carbon footprints include emissions from domestic consumption, public and private investments as well as imports and exports of carbon embedded in goods and services traded with the rest of the world. Modeled estimates based on the systematic combination of tax data, household surveys and input-output tables. Emissions split equally within households.
図の解釈: 個人のカーボン・フットプリントには、国内消費、公共投資、民間投資による排出に加え、世界と取引される財やサービスに含まれる炭素の輸出入が含まれる。税データ、家計調査、産業連関表の体系的な組み合わせに基づくモデル推定値。排出量は家計内で均等に分配される。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology, Chancel (2021).
29.3.16.1 説明
29.3.16.1.1 Step 1.
Excel では、よくあることですが、一列目に、値が入っていません。次を参照してください。ここでは、まず、三つずつ繰り返したものを作っています。
region_test <- rep(df_f15$regionWID[!is.na(df_f15$regionWID)], each = 3)
region_test
#> [1] "East Asia" "East Asia"
#> [3] "East Asia" "Europe"
#> [5] "Europe" "Europe"
#> [7] "North America" "North America"
#> [9] "North America" "South & South-East Asia"
#> [11] "South & South-East Asia" "South & South-East Asia"
#> [13] "Russia & Central Asia" "Russia & Central Asia"
#> [15] "Russia & Central Asia" "MENA"
#> [17] "MENA" "MENA"
#> [19] "Latin America" "Latin America"
#> [21] "Latin America" "Sub-Saharan Africa"
#> [23] "Sub-Saharan Africa" "Sub-Saharan Africa"29.3.16.1.2 Step 2.
最後の列に mutate を使って、値を挿入し select を使って、適切な順序に入れ替えます。
df_f15 |> mutate(region = rep(regionWID[!is.na(regionWID)], each = 3)) |>
select(region, group, tcap)29.3.16.1.3 Step 3.
表が、このようになっていれば、あとは、難しくありません。
df_f15 |> mutate(region = rep(regionWID[!is.na(regionWID)], each = 3)) |>
select(region, group, tcap) |>
ggplot(aes(x = region, y = tcap, fill = group)) +
geom_col(position = "dodge") +
scale_x_discrete(labels = function(x) stringr::str_wrap(x, width = 10)) +
labs(title = "Figure 15 Per capita emissions across the world, 2019",
x = "", y = "tonnes of CO2e per person per year", fill = "")
29.3.17 T1 世界の億万長者と億万長者(2021年)
Global millionaires and billionaires, 2021
シートの形式を確認し、 skip=4, n_max=7 、すなわち、最初の4行を、読み込まず、最大、7行を読み込みます。
df_t1 <- read_excel("./data/WIR2022TablesFigures-Summary.xlsx",
sheet = "T1", skip = 4, n_max = 7)
df_t1Interpretation: In 2021, there were 62.2 million people in the world owning more than $1 million (measured at Market Exchange Rates). Their average wealth was $ 2.8 million, representing a total of $174 trillion. In our Tax scenario 2, a global progressive wealth tax would yield 2.1% of global income, taking into account capital depreciation and evasion.
表の解釈: 2021年、世界には100万ドル以上(市場為替レートで測定)を所有する人々が6,220万人いた。彼らの平均資産は280万ドルで、合計174兆ドルに相当する。我々の税制シナリオ2では、世界的な累進富裕税は、資本償却と脱税を考慮すると、世界所得の2.1%をもたらすだろう。
出典とシリーズ(Sources and series):wir2022.wid.world/methodology.
29.4 WIR2022 の他のデータ
29.4.1 報告書の第1章から第10章で使用されたデータ
There are three ways to import data used in Chapter 1 to Chapter 10.
29.4.1.1 Use the link to download the data.
Go to the Methodology site: https://wir2022.wid.world/methodology/
Copy the link to Dataset 2, i.e., the datasets of chapters 1 to 10.
url_wir1to10 <- "https://wir2022.wid.world/www-site/uploads/2022/03/WIR2022TablesFigures-Chapter.zip"- Download the data in your data folder.
download.file(url_wir1to10, destfile = "./data/wir1to10.zip", mode = "wb")- Unzip the file.
unzip("./data/wir1to10.zip", exdir = "./data")- Download the data from the following site.
- Methodology: https://wir2022.wid.world/methodology/
- Check the file names and check the sheet names.
list.files("./data/WIR2022TablesFigures-Chapter")
#> [1] "WIR2022TablesFigures-Chapter1.xlsx"
#> [2] "WIR2022TablesFigures-Chapter10.xlsx"
#> [3] "WIR2022TablesFigures-Chapter2.xlsx"
#> [4] "WIR2022TablesFigures-Chapter3.xlsx"
#> [5] "WIR2022TablesFigures-Chapter4.xlsx"
#> [6] "WIR2022TablesFigures-Chapter5.xlsx"
#> [7] "WIR2022TablesFigures-Chapter6.xlsx"
#> [8] "WIR2022TablesFigures-Chapter7.xlsx"
#> [9] "WIR2022TablesFigures-Chapter8.xlsx"
#> [10] "WIR2022TablesFigures-Chapter9.xlsx"
excel_sheets("./data/WIR2022TablesFigures-Chapter/WIR2022TablesFigures-Chapter1.xlsx")
#> [1] "Index" "F1.0" "Table 1.1"
#> [4] "F1.1" "F1.2a" "F1.2b"
#> [7] "F1.3" "F1.4" "F1.5"
#> [10] "F1.6a" "F1.6b" "F1.7"
#> [13] "F1.8" "F1.9a" "F1.9b"
#> [16] "F1.10." "F1.11." "F1.12"
#> [19] "F1.13" "F1.14a" "F1.14b"
#> [22] "F1.14c" "F1.15" "F1.16"
#> [25] "FB1.1" "FB1.2" "data-F1.0"
#> [28] "data-Table 1.1" "data-F1.1" "data-F1.2a"
#> [31] "data-F1.2b" "data-F1.3" "data-F1.4"
#> [34] "data-F1.5" "data-F1.6" "data-F1.7"
#> [37] "data-F1.8" "data-F1.9a" "data-F1.9b"
#> [40] "data-F1.10." "data-F1.11." "data-F1.12."
#> [43] "data-F1.13" "data-F1.14abc" "data-F1.15"
#> [46] "data-F1.16" "data-FB1.1" "data-FB1.2"- Import the data table.
wir_F1.0 <- read_excel("./data/WIR2022TablesFigures-Chapter/WIR2022TablesFigures-Chapter1.xlsx", sheet = "data-F1.0")
wir_F1.0- Select the range by slice or use range option.
wir_F1.0 <- wir_F1.0 |> slice(1:2)
wir_F1.0
wir_F1.0a <- read_excel("./data/WIR2022TablesFigures-Chapter/WIR2022TablesFigures-Chapter1.xlsx", sheet = "data-F1.0", range = "A2:E4")
wir_F1.0a
wir_F1.0b <- read_excel("./data/WIR2022TablesFigures-Chapter/WIR2022TablesFigures-Chapter1.xlsx", sheet = "data-F1.0", range = "A7:E9")
#> New names:
#> • `` -> `...1`
wir_F1.0b29.4.2 Download the zip file and move to you data folder
Go to the Methodology site: https://wir2022.wid.world/methodology/
Double click the download link under Dataset 2, i.e., the datasets of chapters 1 to 10 to dounload the zip file.
Unzip the file using the helper application of your PC. In most cases, if you double click the zip file, you can get a folder containing Excel files.
Move to your data folder and follow the line above of the previous method.
29.4.3 Use copying and pasting
Since the table structure of Excel is complicated, it may be much easier to copy and paste the range you want to use. In this case keep the record of the data so that the method is reproducible.
# Copy the range of an Excel sheet into your clipboard
wir_F1.0c <- read_delim(clipboard())
29.5 Package: wid to Download Data
In the following, we explain how to download data by an R package wid-r-tool. First, you need to install the package. The wid-r-tool is a package in the development stage; it is not an official R package yet; you need to use the package devtools to install it.
To install, run the following code or in Console. If you are recommended to update, select one by choosing ‘All’.
install.packages("devtools")
devtools::install_github("WIDworld/wid-r-tool")For references use ‘?download_wid’ or put ‘download_wid’ in the search box under Help.
It is similar to WDI. For more detail and examples, see vignettes.
For indicators of WIR, see codebook.
library("wid")29.5.1 Examples
29.5.1.1 Evolution of national income over long period
This example is essentially the same as in the vignettes.
- We now plot the evolution of average net national income per adult in Japan, France, Germany, the United Kingdom and the United States.
# Average national income data
data <- download_wid(
indicators = "anninc", # Average net national income
areas = c("JP", "FR", "US", "DE", "GB"),
ages = 992 # Adults
) |> rename(value_lcu = value)
# Purchasing power parities with US dollar
ppp <- download_wid(
indicators = "xlcusp", # US PPP
areas = c("JP", "FR", "US", "DE", "GB"), # France, China and United States
year = 2016 # Reference year only
) |> rename(ppp = value) |> select(-year, -percentile)
# Convert from local currency to PPP US dollar
data <- merge(data, ppp, by = "country") |>
mutate(value_ppp = value_lcu/ppp) |>
filter(year %in% 1950:2021)
ggplot(data) +
geom_line(aes(x = year, y = value_ppp, color = country, linetype=country)) +
scale_y_log10(breaks = c(2e3, 5e3, 1e4, 2e4, 5e4)) +
ylab("2016 $ PPP") +
scale_color_discrete(
labels = c("JP" = "Japan", "US" = "USA", "FR" = "France", "DE" = "Germany", "GB" = "UK")
) +
scale_linetype_discrete(
labels = c("JP" = "Japan", "US" = "USA", "FR" = "France", "DE" = "Germany", "GB" = "UK")
) +
ggtitle("Average net national income per adult")We choose two indicators: ‘wealg’ and ‘wealp’. WIR2022 indicators consists of 6 characters; 1 letter code plus 5 letter code. You can find the list in the codebook.
If you want to study WIR2022, please study the report, the codebook, and wir vignette together with the R Notebook.
References: https://ds-sl.github.io/data-analysis/wir2022.nb.html
29.6 WIR Package
In the following, we explain how to download data by an R package wir. First, you need to install the package. However, it is not an official R package yet; you need to use the package devtools to install it.
install.packages("devtools")
devtools::install_github("WIDworld/wid-r-tool")I have not studied fully, but you can download the data by a package called wir. See here. After installing the package, check the codebook of the indicators. The following is not the ratio given in F8, but an example.
- w wealth-to-income ratio or labor/capital share fraction of national income
- wealg: net public wealth to net national income ratio
- wealp: net private wealth to net national income ratio
library(wid)
wwealg <- download_wid(indicators = "wwealg", areas = "all", years = "all")
wwealp <- download_wid(indicators = "wwealp", areas = "all", years = "all")#> Rows: 8783 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, variable, percentile
#> dbl (2): year, value
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> Rows: 8989 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, variable, percentile
#> dbl (2): year, value
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
public <- wwealg |> select(country, year, public = value)
public
private <- wwealp |> select(country, year, private = value)
private
public_vs_private <- public |> left_join(private)
#> Joining with `by = join_by(country, year)`
public_vs_privateWe use wdi_cache created by wdi_cache = WDI::wdi_cache().
wdi_cache <- read_rds("./data/wdi_cache.RData")
df_pub_priv <- public_vs_private |> pivot_longer(cols = c(3,4), names_to = "category", values_to = "value") |> left_join(wdi_cache$country, by = c("country"="iso2c")) |>
select(country = country.y, iso2c = country, year, category, value, region, income, lending)
df_pub_priv
unique(df_pub_priv$country)
#> [1] "Andorra"
#> [2] "United Arab Emirates"
#> [3] "Afghanistan"
#> [4] "Antigua and Barbuda"
#> [5] NA
#> [6] "Albania"
#> [7] "Armenia"
#> [8] "Angola"
#> [9] "Argentina"
#> [10] "American Samoa"
#> [11] "Austria"
#> [12] "Australia"
#> [13] "Aruba"
#> [14] "Azerbaijan"
#> [15] "Bosnia and Herzegovina"
#> [16] "Barbados"
#> [17] "Bangladesh"
#> [18] "Belgium"
#> [19] "Burkina Faso"
#> [20] "Bulgaria"
#> [21] "Bahrain"
#> [22] "Burundi"
#> [23] "Benin"
#> [24] "Bermuda"
#> [25] "Brunei Darussalam"
#> [26] "Bolivia"
#> [27] "Brazil"
#> [28] "Bahamas, The"
#> [29] "Bhutan"
#> [30] "Botswana"
#> [31] "Belize"
#> [32] "Canada"
#> [33] "Congo, Dem. Rep."
#> [34] "Central African Republic"
#> [35] "Congo, Rep."
#> [36] "Switzerland"
#> [37] "Cote d'Ivoire"
#> [38] "Chile"
#> [39] "Cameroon"
#> [40] "China"
#> [41] "Colombia"
#> [42] "Costa Rica"
#> [43] "Cuba"
#> [44] "Cabo Verde"
#> [45] "Curacao"
#> [46] "Cyprus"
#> [47] "Czechia"
#> [48] "Germany"
#> [49] "Djibouti"
#> [50] "Denmark"
#> [51] "Dominica"
#> [52] "Dominican Republic"
#> [53] "Algeria"
#> [54] "Ecuador"
#> [55] "Estonia"
#> [56] "Egypt, Arab Rep."
#> [57] "Eritrea"
#> [58] "Spain"
#> [59] "Ethiopia"
#> [60] "Finland"
#> [61] "Fiji"
#> [62] "Micronesia, Fed. Sts."
#> [63] "France"
#> [64] "Gabon"
#> [65] "United Kingdom"
#> [66] "Grenada"
#> [67] "Georgia"
#> [68] "Ghana"
#> [69] "Greenland"
#> [70] "Gambia, The"
#> [71] "Guinea"
#> [72] "Equatorial Guinea"
#> [73] "Greece"
#> [74] "Guatemala"
#> [75] "Guam"
#> [76] "Guinea-Bissau"
#> [77] "Guyana"
#> [78] "Hong Kong SAR, China"
#> [79] "Honduras"
#> [80] "Croatia"
#> [81] "Haiti"
#> [82] "Hungary"
#> [83] "Indonesia"
#> [84] "Ireland"
#> [85] "Israel"
#> [86] "Isle of Man"
#> [87] "India"
#> [88] "Iraq"
#> [89] "Iran, Islamic Rep."
#> [90] "Iceland"
#> [91] "Italy"
#> [92] "Jamaica"
#> [93] "Jordan"
#> [94] "Japan"
#> [95] "Kenya"
#> [96] "Kyrgyz Republic"
#> [97] "Cambodia"
#> [98] "Kiribati"
#> [99] "Comoros"
#> [100] "St. Kitts and Nevis"
#> [101] "Korea, Dem. People's Rep."
#> [102] "Korea, Rep."
#> [103] "Kuwait"
#> [104] "Cayman Islands"
#> [105] "Kazakhstan"
#> [106] "Lao PDR"
#> [107] "Lebanon"
#> [108] "St. Lucia"
#> [109] "Liechtenstein"
#> [110] "Sri Lanka"
#> [111] "Liberia"
#> [112] "Lesotho"
#> [113] "Lithuania"
#> [114] "Luxembourg"
#> [115] "Latvia"
#> [116] "Libya"
#> [117] "Morocco"
#> [118] "Monaco"
#> [119] "Moldova"
#> [120] "Montenegro"
#> [121] "Madagascar"
#> [122] "Marshall Islands"
#> [123] "North Macedonia"
#> [124] "Mali"
#> [125] "Myanmar"
#> [126] "Mongolia"
#> [127] "Macao SAR, China"
#> [128] "Northern Mariana Islands"
#> [129] "Mauritania"
#> [130] "Malta"
#> [131] "Mauritius"
#> [132] "Maldives"
#> [133] "Malawi"
#> [134] "Mexico"
#> [135] "Malaysia"
#> [136] "Mozambique"
#> [137] "New Caledonia"
#> [138] "Niger"
#> [139] "Nigeria"
#> [140] "Nicaragua"
#> [141] "Netherlands"
#> [142] "Norway"
#> [143] "Nepal"
#> [144] "Nauru"
#> [145] "New Zealand"
#> [146] "OECD members"
#> [147] "Oman"
#> [148] "Panama"
#> [149] "Peru"
#> [150] "French Polynesia"
#> [151] "Papua New Guinea"
#> [152] "Philippines"
#> [153] "Pakistan"
#> [154] "Poland"
#> [155] "Puerto Rico"
#> [156] "West Bank and Gaza"
#> [157] "Portugal"
#> [158] "Palau"
#> [159] "Paraguay"
#> [160] "Qatar"
#> [161] "Romania"
#> [162] "Serbia"
#> [163] "Russian Federation"
#> [164] "Rwanda"
#> [165] "Saudi Arabia"
#> [166] "Solomon Islands"
#> [167] "Seychelles"
#> [168] "Sudan"
#> [169] "Sweden"
#> [170] "Singapore"
#> [171] "Slovenia"
#> [172] "Slovak Republic"
#> [173] "Sierra Leone"
#> [174] "San Marino"
#> [175] "Senegal"
#> [176] "Somalia"
#> [177] "Suriname"
#> [178] "South Sudan"
#> [179] "Sao Tome and Principe"
#> [180] "El Salvador"
#> [181] "Sint Maarten (Dutch part)"
#> [182] "Syrian Arab Republic"
#> [183] "Eswatini"
#> [184] "Turks and Caicos Islands"
#> [185] "Chad"
#> [186] "Togo"
#> [187] "Thailand"
#> [188] "Tajikistan"
#> [189] "Timor-Leste"
#> [190] "Turkmenistan"
#> [191] "Tunisia"
#> [192] "Tonga"
#> [193] "Turkiye"
#> [194] "Trinidad and Tobago"
#> [195] "Tuvalu"
#> [196] "Taiwan, China"
#> [197] "Tanzania"
#> [198] "Ukraine"
#> [199] "Uganda"
#> [200] "United States"
#> [201] "Uruguay"
#> [202] "Uzbekistan"
#> [203] "St. Vincent and the Grenadines"
#> [204] "Venezuela, RB"
#> [205] "British Virgin Islands"
#> [206] "Virgin Islands (U.S.)"
#> [207] "Vietnam"
#> [208] "Vanuatu"
#> [209] "Samoa"
#> [210] "IBRD only"
#> [211] "IDA only"
#> [212] "Least developed countries: UN classification"
#> [213] "Low income"
#> [214] "Lower middle income"
#> [215] "Yemen, Rep."
#> [216] "South Africa"
#> [217] "Zambia"
#> [218] "Zimbabwe"
df_pub_priv |>
filter(country %in% c("Japan", "Norway", "Sweden", "Denmark", "Finland"), year %in% 1970:2020) |>
ggplot(aes(year, value, color = country, linetype = category)) + geom_line()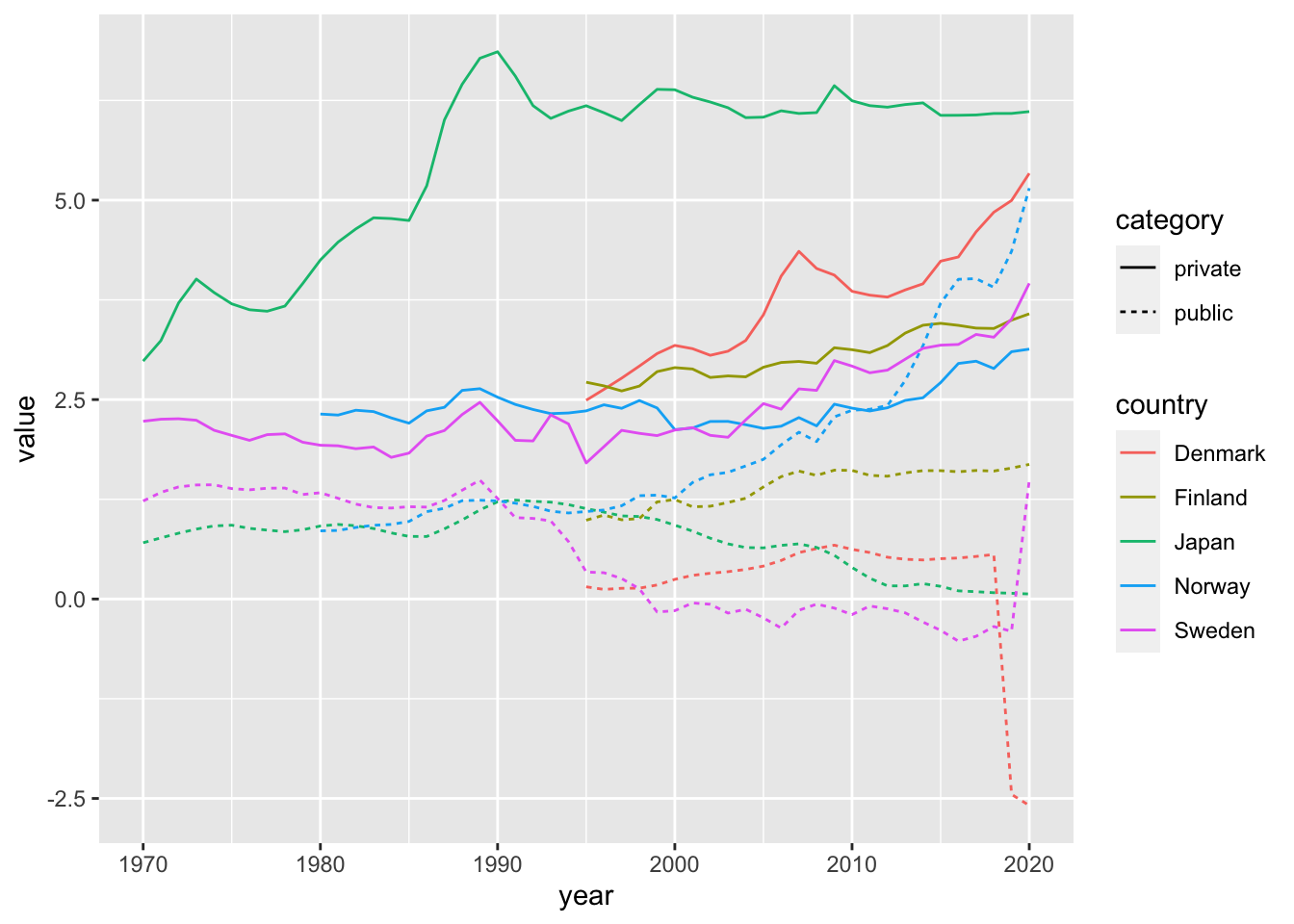
We choose two indicators: ‘wealg’ and ‘wealp’. WIR2022 indicators consists of 6 characters; 1 letter code plus 5 letter code. You can find the list in the codebook.
If you want to study WIR2022, please study the report, the codebook, and wir vignette together with the R Notebook.
As I mentioned earlier, the data tables used in the report are available from the following page.
- Methodology: https://wir2022.wid.world/methodology/