28 World Inequality Report
28.1 Set up
library(tidyverse)
#> ── Attaching core tidyverse packages ──── tidyverse 2.0.0 ──
#> ✔ dplyr 1.1.2 ✔ readr 2.1.4
#> ✔ forcats 1.0.0 ✔ stringr 1.5.0
#> ✔ ggplot2 3.4.2 ✔ tibble 3.2.1
#> ✔ lubridate 1.9.2 ✔ tidyr 1.3.0
#> ✔ purrr 1.0.1
#> ── Conflicts ────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(readxl) # for excel files
library(WDI)28.1.1 World Inequility Report - WIR2022
- World Inequality Report: https://wir2022.wid.world/
- Executive Summary: https://wir2022.wid.world/executive-summary/
- Methodology: https://wir2022.wid.world/methodology/
- URL of Executive Summary Data: https://wir2022.wid.world/www-site/uploads/2022/03/WIR2022TablesFigures-Summary.xlsx
Please add mode="wb" (web binary). This should work better.
url_summary <- "https://wir2022.wid.world/www-site/uploads/2022/03/WIR2022TablesFigures-Summary.xlsx"
download.file(url = url_summary,
destfile = "./data/WIR2022s.xlsx",
mode = "wb") If you get an error, download the file directory from the methodology site into your computer, then open it with Excel and save it in the data folder of your R Studio project. Then R studio can recognize it easily as an Excel data.
Generally, a text file such as a CSV file is easy to import, but a binary file is difficult to handle. It is because unless R can recognize its file type, for example, Excel or so, R cannot import the data.
excel_sheets("./data/WIR2022s.xlsx")
#> [1] "Index" "F1" "F2" "F3"
#> [5] "F4" "F5." "F6" "F7"
#> [9] "F8" "F9" "F10" "F11"
#> [13] "F12" "F13" "F14" "F15"
#> [17] "T1" "data-F1" "data-F2" "data-F3"
#> [21] "data-F4" "data-F5" "data-F6" "data-F7"
#> [25] "data-F8" "data-F9" "data-F10" "data-F11"
#> [29] "data-F12" "data-F13." "data-F14." "data-F15"28.2 WIR Package
In the following, we explain how to download data by an R package wir. First, you need to install the package. However, it is not an official R package yet; you need to use the package devtools to install it.
install.packages("devtools")
devtools::install_github("WIDworld/wid-r-tool")I have not studied fully, but you can download the data by a package called wir. See here. After installing the package, check the codebook of the indicators. The following is not the ratio given in F8, but an example.
- w wealth-to-income ratio or labor/capital share fraction of national income
- wealg: net public wealth to net national income ratio
- wealp: net private wealth to net national income ratio
library(wid)
wwealg <- download_wid(indicators = "wwealg", areas = "all", years = "all")
wwealp <- download_wid(indicators = "wwealp", areas = "all", years = "all")#> Rows: 8783 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, variable, percentile
#> dbl (2): year, value
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
#> Rows: 8989 Columns: 5
#> ── Column specification ────────────────────────────────────
#> Delimiter: ","
#> chr (3): country, variable, percentile
#> dbl (2): year, value
#>
#> ℹ Use `spec()` to retrieve the full column specification for this data.
#> ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
public <- wwealg %>% select(country, year, public = value)
public
#> # A tibble: 8,783 × 3
#> country year public
#> <chr> <dbl> <dbl>
#> 1 AD 1995 0.0765
#> 2 AD 1996 0.0973
#> 3 AD 1997 0.118
#> 4 AD 1998 0.138
#> 5 AD 1999 0.159
#> 6 AD 2000 0.182
#> 7 AD 2001 0.207
#> 8 AD 2002 0.234
#> 9 AD 2003 0.263
#> 10 AD 2004 0.294
#> # ℹ 8,773 more rows
private <- wwealp %>% select(country, year, private = value)
private
#> # A tibble: 8,989 × 3
#> country year private
#> <chr> <dbl> <dbl>
#> 1 AD 1995 0.441
#> 2 AD 1996 0.488
#> 3 AD 1997 0.534
#> 4 AD 1998 0.582
#> 5 AD 1999 0.628
#> 6 AD 2000 0.678
#> 7 AD 2001 0.727
#> 8 AD 2002 0.778
#> 9 AD 2003 0.834
#> 10 AD 2004 0.894
#> # ℹ 8,979 more rows
public_vs_private <- public %>% left_join(private)
#> Joining with `by = join_by(country, year)`
public_vs_private
#> # A tibble: 8,783 × 4
#> country year public private
#> <chr> <dbl> <dbl> <dbl>
#> 1 AD 1995 0.0765 0.441
#> 2 AD 1996 0.0973 0.488
#> 3 AD 1997 0.118 0.534
#> 4 AD 1998 0.138 0.582
#> 5 AD 1999 0.159 0.628
#> 6 AD 2000 0.182 0.678
#> 7 AD 2001 0.207 0.727
#> 8 AD 2002 0.234 0.778
#> 9 AD 2003 0.263 0.834
#> 10 AD 2004 0.294 0.894
#> # ℹ 8,773 more rowsWe use wdi_cache created by wdi_cache = WDI::wdi_cache().
wdi_cache <- read_rds("./data/wdi_cache.RData")
df_pub_priv <- public_vs_private %>% pivot_longer(cols = c(3,4), names_to = "category", values_to = "value") %>% left_join(wdi_cache$country, by = c("country"="iso2c")) %>%
select(country = country.y, iso2c = country, year, category, value, region, income, lending)
df_pub_priv
#> # A tibble: 17,566 × 8
#> country iso2c year category value region income lending
#> <chr> <chr> <dbl> <chr> <dbl> <chr> <chr> <chr>
#> 1 Andorra AD 1995 public 0.0765 Europ… High … Not cl…
#> 2 Andorra AD 1995 private 0.441 Europ… High … Not cl…
#> 3 Andorra AD 1996 public 0.0973 Europ… High … Not cl…
#> 4 Andorra AD 1996 private 0.488 Europ… High … Not cl…
#> 5 Andorra AD 1997 public 0.118 Europ… High … Not cl…
#> 6 Andorra AD 1997 private 0.534 Europ… High … Not cl…
#> 7 Andorra AD 1998 public 0.138 Europ… High … Not cl…
#> 8 Andorra AD 1998 private 0.582 Europ… High … Not cl…
#> 9 Andorra AD 1999 public 0.159 Europ… High … Not cl…
#> 10 Andorra AD 1999 private 0.628 Europ… High … Not cl…
#> # ℹ 17,556 more rows
unique(df_pub_priv$country)
#> [1] "Andorra"
#> [2] "United Arab Emirates"
#> [3] "Afghanistan"
#> [4] "Antigua and Barbuda"
#> [5] NA
#> [6] "Albania"
#> [7] "Armenia"
#> [8] "Angola"
#> [9] "Argentina"
#> [10] "American Samoa"
#> [11] "Austria"
#> [12] "Australia"
#> [13] "Aruba"
#> [14] "Azerbaijan"
#> [15] "Bosnia and Herzegovina"
#> [16] "Barbados"
#> [17] "Bangladesh"
#> [18] "Belgium"
#> [19] "Burkina Faso"
#> [20] "Bulgaria"
#> [21] "Bahrain"
#> [22] "Burundi"
#> [23] "Benin"
#> [24] "Bermuda"
#> [25] "Brunei Darussalam"
#> [26] "Bolivia"
#> [27] "Brazil"
#> [28] "Bahamas, The"
#> [29] "Bhutan"
#> [30] "Botswana"
#> [31] "Belize"
#> [32] "Canada"
#> [33] "Congo, Dem. Rep."
#> [34] "Central African Republic"
#> [35] "Congo, Rep."
#> [36] "Switzerland"
#> [37] "Cote d'Ivoire"
#> [38] "Chile"
#> [39] "Cameroon"
#> [40] "China"
#> [41] "Colombia"
#> [42] "Costa Rica"
#> [43] "Cuba"
#> [44] "Cabo Verde"
#> [45] "Curacao"
#> [46] "Cyprus"
#> [47] "Czechia"
#> [48] "Germany"
#> [49] "Djibouti"
#> [50] "Denmark"
#> [51] "Dominica"
#> [52] "Dominican Republic"
#> [53] "Algeria"
#> [54] "Ecuador"
#> [55] "Estonia"
#> [56] "Egypt, Arab Rep."
#> [57] "Eritrea"
#> [58] "Spain"
#> [59] "Ethiopia"
#> [60] "Finland"
#> [61] "Fiji"
#> [62] "Micronesia, Fed. Sts."
#> [63] "France"
#> [64] "Gabon"
#> [65] "United Kingdom"
#> [66] "Grenada"
#> [67] "Georgia"
#> [68] "Ghana"
#> [69] "Greenland"
#> [70] "Gambia, The"
#> [71] "Guinea"
#> [72] "Equatorial Guinea"
#> [73] "Greece"
#> [74] "Guatemala"
#> [75] "Guam"
#> [76] "Guinea-Bissau"
#> [77] "Guyana"
#> [78] "Hong Kong SAR, China"
#> [79] "Honduras"
#> [80] "Croatia"
#> [81] "Haiti"
#> [82] "Hungary"
#> [83] "Indonesia"
#> [84] "Ireland"
#> [85] "Israel"
#> [86] "Isle of Man"
#> [87] "India"
#> [88] "Iraq"
#> [89] "Iran, Islamic Rep."
#> [90] "Iceland"
#> [91] "Italy"
#> [92] "Jamaica"
#> [93] "Jordan"
#> [94] "Japan"
#> [95] "Kenya"
#> [96] "Kyrgyz Republic"
#> [97] "Cambodia"
#> [98] "Kiribati"
#> [99] "Comoros"
#> [100] "St. Kitts and Nevis"
#> [101] "Korea, Dem. People's Rep."
#> [102] "Korea, Rep."
#> [103] "Kuwait"
#> [104] "Cayman Islands"
#> [105] "Kazakhstan"
#> [106] "Lao PDR"
#> [107] "Lebanon"
#> [108] "St. Lucia"
#> [109] "Liechtenstein"
#> [110] "Sri Lanka"
#> [111] "Liberia"
#> [112] "Lesotho"
#> [113] "Lithuania"
#> [114] "Luxembourg"
#> [115] "Latvia"
#> [116] "Libya"
#> [117] "Morocco"
#> [118] "Monaco"
#> [119] "Moldova"
#> [120] "Montenegro"
#> [121] "Madagascar"
#> [122] "Marshall Islands"
#> [123] "North Macedonia"
#> [124] "Mali"
#> [125] "Myanmar"
#> [126] "Mongolia"
#> [127] "Macao SAR, China"
#> [128] "Northern Mariana Islands"
#> [129] "Mauritania"
#> [130] "Malta"
#> [131] "Mauritius"
#> [132] "Maldives"
#> [133] "Malawi"
#> [134] "Mexico"
#> [135] "Malaysia"
#> [136] "Mozambique"
#> [137] "New Caledonia"
#> [138] "Niger"
#> [139] "Nigeria"
#> [140] "Nicaragua"
#> [141] "Netherlands"
#> [142] "Norway"
#> [143] "Nepal"
#> [144] "Nauru"
#> [145] "New Zealand"
#> [146] "OECD members"
#> [147] "Oman"
#> [148] "Panama"
#> [149] "Peru"
#> [150] "French Polynesia"
#> [151] "Papua New Guinea"
#> [152] "Philippines"
#> [153] "Pakistan"
#> [154] "Poland"
#> [155] "Puerto Rico"
#> [156] "West Bank and Gaza"
#> [157] "Portugal"
#> [158] "Palau"
#> [159] "Paraguay"
#> [160] "Qatar"
#> [161] "Romania"
#> [162] "Serbia"
#> [163] "Russian Federation"
#> [164] "Rwanda"
#> [165] "Saudi Arabia"
#> [166] "Solomon Islands"
#> [167] "Seychelles"
#> [168] "Sudan"
#> [169] "Sweden"
#> [170] "Singapore"
#> [171] "Slovenia"
#> [172] "Slovak Republic"
#> [173] "Sierra Leone"
#> [174] "San Marino"
#> [175] "Senegal"
#> [176] "Somalia"
#> [177] "Suriname"
#> [178] "South Sudan"
#> [179] "Sao Tome and Principe"
#> [180] "El Salvador"
#> [181] "Sint Maarten (Dutch part)"
#> [182] "Syrian Arab Republic"
#> [183] "Eswatini"
#> [184] "Turks and Caicos Islands"
#> [185] "Chad"
#> [186] "Togo"
#> [187] "Thailand"
#> [188] "Tajikistan"
#> [189] "Timor-Leste"
#> [190] "Turkmenistan"
#> [191] "Tunisia"
#> [192] "Tonga"
#> [193] "Turkiye"
#> [194] "Trinidad and Tobago"
#> [195] "Tuvalu"
#> [196] "Taiwan, China"
#> [197] "Tanzania"
#> [198] "Ukraine"
#> [199] "Uganda"
#> [200] "United States"
#> [201] "Uruguay"
#> [202] "Uzbekistan"
#> [203] "St. Vincent and the Grenadines"
#> [204] "Venezuela, RB"
#> [205] "British Virgin Islands"
#> [206] "Virgin Islands (U.S.)"
#> [207] "Vietnam"
#> [208] "Vanuatu"
#> [209] "Samoa"
#> [210] "IBRD only"
#> [211] "IDA only"
#> [212] "Least developed countries: UN classification"
#> [213] "Low income"
#> [214] "Lower middle income"
#> [215] "Yemen, Rep."
#> [216] "South Africa"
#> [217] "Zambia"
#> [218] "Zimbabwe"
df_pub_priv %>%
filter(country %in% c("Japan", "Norway", "Sweden", "Denmark", "Finland"), year %in% 1970:2020) %>%
ggplot(aes(year, value, color = country, linetype = category)) + geom_line()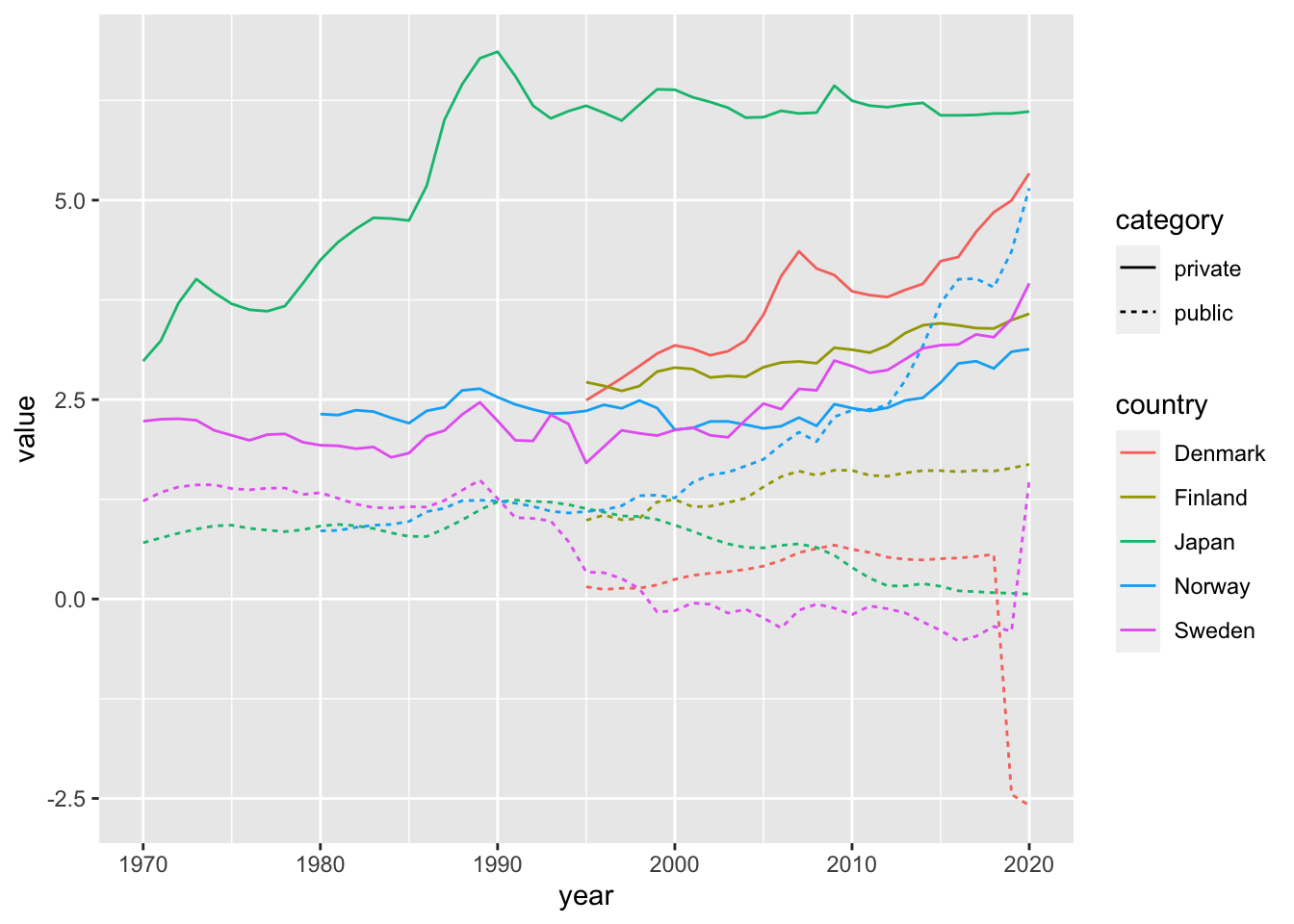
We choose two indicators: ‘wealg’ and ‘wealp’. WIR2022 indicators consists of 6 characters; 1 letter code plus 5 letter code. You can find the list in the codebook.
If you want to study WIR2022, please study the report, the codebook, and wir vignette together with the R Notebook.
As I mentioned earlier, the data tables used in the report are available from the following page.
- Methodology: https://wir2022.wid.world/methodology/